《大数据求职》专题
-
 2023届校招面经:北京移动-大数据工程师
2023届校招面经:北京移动-大数据工程师TimeLine:一面20221115(已挂) BG:北邮本硕,管理类专业,两段实习经历:字节数据分析师、美团商业分析师 写在前面的话:北京移动的面试环节紧凑,面试时间5-6分钟,问的问题都比较常规 一面 1. 毕业时间在什么时候? 2. 在北京移动公司是否有直系亲属? 3. 对于北京户口是否有刚需? 4. 你的年薪预期是多少? 5. 有没有投北京移动的其他岗位? 6. 是否愿意接受调剂到市场/综
-
 (暑期实习)美团大数据开发实习生一面
(暑期实习)美团大数据开发实习生一面个人情况简述:本硕双非,acm银牌 随便找群友要了个内推投递 笔试4.2题,投递选择的是都喜欢,笔试完在人才池待了十几天,被数仓部门捞了 一面(总时长50分钟) 聊实习经历和简历项目,聊了约30分钟 聊天环节把整个技术栈聊的差不多了,还有离线、实时数仓的很多点,后面又问了几个问题 离线数仓分层设计、实时数仓设计,spark、flink相关生成经验,S3、OSS的使用理解,k8s的使用心得等都在聊项
-
为什么抵达率会有大于100%的数据出现
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么抵达率会有大于100%的数据出现 抵达率的计算方法为访问次数比上点击数,如有无效点击,点击会被过滤掉不计费,但是后续的PV、访问次数等数据统计会记录到,所以点击数量可能出现小于访问次数。百度统计里边的点击量和凤巢里边的点击量是一致的,都是过滤了无效点击之后的数据,但无效点击产生的访次还在,所以可能导致抵达率>100%。
-
 2023秋招-大数据开发面试-阿里国际-一面
2023秋招-大数据开发面试-阿里国际-一面1、 确认专业,保研,成绩,排名 2、 课程内容,研究生课程等 3、 数据库底层索引的优劣势? 4、 我现在有一张表把所有字段都加索引了,这样好吗? 5、 存储过程和视图? 6、 视图字段是单独存储的吗? 7、 MR原理用你自己话简单描述。 8、 MR中数据倾斜的产生情况,你如何解决? 9、 一个复杂的SQL中发生了数据倾斜,你怎么确定是哪个group by还是join发生的? 10、 count
-
 2023秋招-大数据开发面试-阿里淘天-一面
2023秋招-大数据开发面试-阿里淘天-一面1、 是找大数据还是算法? 2、 对大数据领域的了解? 3、 从0-1建设数仓,你怎么做? 4、 数仓建设规范,依据? 5、 没想一块去,他想问建模思想之类的。维度、范式 6、 会哪些技术栈? 7、 Hadoop讲讲吧? 8、 为什么要有Hive,Hive作用? 9、 详细讲讲MR? 10、 数据倾斜发生的位置? 11、 Combiner了解吗? 12、 什么情况下不能用Combiner? 13、
-
 2023秋招-大数据开发面试-阿里淘天-二面
2023秋招-大数据开发面试-阿里淘天-二面1、 在XX实习,目前没有offer吗? 2、 实习和你项目的区别、实习项目主要做的内容? 3、 实习的难点? 4、 系统主要做的什么? 5、 讲讲MR? 6、 数据倾斜遇到过吗? 7、 除了null值呢? 8、 除了随机打散还有别的方案解决吗?
-
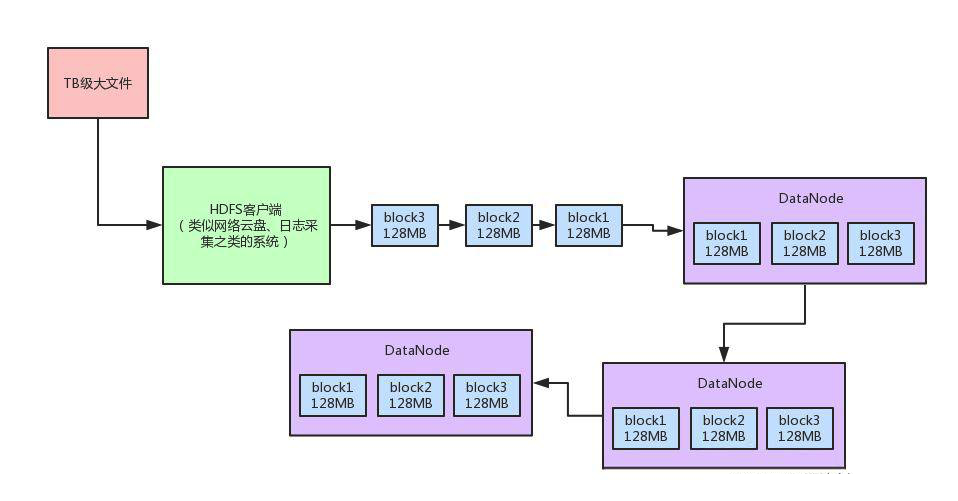 关于超大数据量的系统性能优化设计
关于超大数据量的系统性能优化设计主要内容:1、Chunk缓冲机制,2、Packet数据包机制,3、内存队列异步发送机制,总结:这篇文章,我们来聊一聊在十亿级的大数据量技术挑战下,世界上最优秀的大数据系统之一的Hadoop是如何将系统性能提升数十倍的? 首先一起来画个图,回顾一下Hadoop HDFS中的超大数据文件上传的原理。 其实说出来也很简单,比如有个十亿数据量级的超大数据文件,可能都达到TB级了,此时这个文件实在是太大了。 此时,HDFS客户端会给拆成很多block,一个block就128MB。 这个HDFS客户端
-
 小公司不招Java实习从大数据聊到开发
小公司不招Java实习从大数据聊到开发答的不是很好 #Java# 第一个面试官似乎是个领导跟之前大二面的ruoyi二开那个人脸熟,纯难崩。 自我介绍:自学Spring,微服务等等……,拿省赛奖等等,成绩前3%。 pua我学历大专 大数据提问:谈了下hadoop生态的hdfs,hbase,hive,kafka,MySQL,pg基本原理以及使用,etl概念 (加班潜规则) 然后我说想干Java,但是公司不招Java实习,现阶段项目很复杂,
-
 腾讯社招(一面)面经;大数据开发工程师
腾讯社招(一面)面经;大数据开发工程师1. 请简述您如何理解腾讯的企业文化,并结合您的经验谈谈您如何融入这样的文化环境。 2. 在团队合作项目中,您通常扮演什么角色?请举例说明您如何在团队中发挥作用。 3. 描述一次您在项目中遇到困难或挑战的情况,以及您是如何解决问题的。 4. 请讲述一个您成功领导团队达成目标的经历,包括您采取的策略和最终结果。 5. 面对紧急且重要的任务时,您如何安排时间和资源以确保任务按时完成? 6. 请分享一个
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点 hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理 hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台) 特点: 高扩容:had
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台)特点:高扩容:hadoop在
-
 理想汽车 | 实习一面面经 | 大数据开发 |5.18
理想汽车 | 实习一面面经 | 大数据开发 |5.18#在牛客分享我的求职旅程##理想汽车信息集散地##理想汽车##实习##面经#
-
有没有办法找到Android中HTTP请求和响应的完整大小(用于数据使用情况跟踪)?
问题内容: 我想跟踪我的应用程序的数据使用,但要做到这一点,我需要能够得到的全尺寸和。仅获取的大小是不够的,因为请求和响应都传输了更多的数据(标头,参数,正在传输的实际URL等)。那么,有没有办法找到双向传输的全部数据呢? 谢谢。 问题答案: 如果只希望度量“之后”,则可以提供适合自己的实现的子类,并在将请求返回给管理器之后获取相关的子类。 作为一个简单的示例(以及一点点sh * tty),sub
-
R: 查找数据帧列中大于或等于其他数据帧列的行值的最小值
第一次问问题(温柔点),因为我还没有找到任何有用的东西。 在R中,我有两个数据帧。一个(DataFrameA)有一列带有唯一日期列表。另一个(DataFrameB)也有日期列表。但是DataFrameB中的某些日期在DataFrameA中可能不存在。在这种情况下,我想将DataFrameB中的日期更新为DataFrameA中的最小日期,该日期大于DataFrameB中的日期。 在SQL中,我可能会
-
宇宙数据库能否以批大小从文件 Blob 或 Csv 或 Json 文件中读取数据?
我目前正在研究使用cosmos db读取数据,基本上我们目前的方法是使用带有Cosmos DB SDK的.Net Core C#应用程序从文件blob或csv或json文件中读取整个数据,然后使用for循环,逐个从cosmos db中提取其信息并比较/插入/更新, 这在某种程度上感觉效率低下。 我们很好奇 cosmos DB 是否可以执行从文件 blob 或 csv 或 json 文件以及类似 S