《数据分析工程师》专题
-
 美团-工程效能组-开发工程师实习生(工程基建方向)-一面
美团-工程效能组-开发工程师实习生(工程基建方向)-一面项目 介绍网页音视频项目 项目代码量多少?是一个人完成的吗? 介绍SaaS视频项目 Spring Spring框架有什么特性?(❌不知道这个问题要问什么,答的扩展性、封装性啥的) 控制反转了解吗?原理呢?(❌简单说了下,原理不知道) AOP了解吗?项目用过吗?(❌简单说了下,项目里没用过) Java 线程池的七个参数? 拒绝策略有哪些?(❌漏了一个静默丢弃) 阻塞队列的长度怎么设置?(❌不会) J
-
分页工具-PageUtil
由来 分页工具类并不是数据库分页的封装,而是分页方式的转换。在我们手动分页的时候,常常使用页码+每页个数的方式,但是有些数据库需要使用开始位置和结束位置来表示。很多时候这种转换容易出错(边界问题),于是封装了PageUtil工具类。 使用 transToStartEnd 将页数和每页条目数转换为开始位置和结束位置。 此方法用于不包括结束位置的分页方法。 例如: 页码:0,每页10 -> [0, 1
-
VTune 分析未显示多态函数分支预测的指标?
我正在分析处理数百万条消息的两种设计之间的差异。一种设计使用多态,另一种不使用——每个消息都将由多态子类型表示。 我已经使用 VTune 分析了这两种设计。高级摘要数据似乎很有意义 - 与使用IF语句实现的非多态版本相比,多态设计具有更高的“分支误判”率,更高的CPI和更高的“ICache未命中”率。 多态设计有一行源代码,如下所示: 这被称为数百万次(其中子类型每次都改变)。由于分支目标预测失误
-
 详解C++中虚析构函数的作用及其原理分析
详解C++中虚析构函数的作用及其原理分析本文向大家介绍详解C++中虚析构函数的作用及其原理分析,包括了详解C++中虚析构函数的作用及其原理分析的使用技巧和注意事项,需要的朋友参考一下 C++中的虚析构函数到底什么时候有用的,什么作用呢。 一.虚析构函数的作用 总的来说虚析构函数是为了避免内存泄露,而且是当子类中会有指针成员变量时才会使用得到的。也就说虚析构函数使得在删除指向子类对象的基类指针时可以调用子类的析构函数达到释放子类中堆内存的
-
 得物L【95分】商业分析师面试0221~
得物L【95分】商业分析师面试0221~今年第三家面试公司是得物旗下的95分商业分析师。现在看录音回放,感觉当时的回答好糟糕啊!!! 面试得物的是一个超级无敌温柔的商业分析师。感觉就像是小姐姐一样亲切一直引导你,但我还是经验尚浅。准备的不够充分吧。 开头一贯都是先让做自我介绍。 然后接下来就问我目前所在位置+实习能够实习多久之类的问题。 接下来就是扔给我之前HR发我的两道题,一道是有关费米估算问题的求解,另一道是SQL题。 费米估算问题
-
Java文本分析库
问题内容: 我正在寻找一种Java驱动的解决方案来满足分析句子以记录关键字是肯定还是否定使用的要求。 即关键词可能是’白菜’和句子: 我喜欢白菜而不喜欢豌豆 我想要某种Java文本分析器将此记录为肯定。可以使用lucene(休眠搜索)库吗? 有什么想法吗? 问题答案: 您正在寻找“情感分析”。LingPipe是一种可能,他也与竞争对手保持友好联系。Jeff Dalton 的博客中还提供了大量自然语
-
Android AsyncTask源码分析
本文向大家介绍Android AsyncTask源码分析,包括了Android AsyncTask源码分析的使用技巧和注意事项,需要的朋友参考一下 Android中只能在主线程中进行UI操作,如果是其它子线程,需要借助异步消息处理机制Handler。除此之外,还有个非常方便的AsyncTask类,这个类内部封装了Handler和线程池。本文先简要介绍AsyncTask的用法,然后分析具体实现。 基
-
全面分析c# LINQ
本文向大家介绍全面分析c# LINQ,包括了全面分析c# LINQ的使用技巧和注意事项,需要的朋友参考一下 大家好,这是 [C#.NET 拾遗补漏] 系列的第 08 篇文章,今天讲 C# 强大的 LINQ 查询。LINQ 是我最喜欢的 C# 语言特性之一。 LINQ 是 Language INtegrated Query 单词的首字母缩写,翻译过来是语言集成查询。它为查询跨各种数据源和格式的数据提
-
Elasticsearch定制分析器
问题内容: 是否可以创建可按空间拆分索引然后创建两个令牌的自定义elasticsearch分析器?一是空间前的一切,二是空间。例如:我存储的记录字段包含以下文本:“ 35 G”。现在,我想通过仅在该字段中键入“ 35”或“ 35 G”查询来接收该记录。因此,Elastic应该创建两个令牌:[‘35’,‘35 G’],并且不再更多。 如果可能,如何实现? 问题答案: 可使用tokenizer实现。
-
Elasticsearch中的分析器
问题内容: 我在理解带轮胎宝石的elasticsearch中分析仪的概念时遇到了麻烦。我实际上是这些搜索概念的新手。这里有人可以帮我提供一些参考文章还是解释一下分析仪的实际作用以及为什么要使用它们? 我看到在Elasticsearch中提到了不同的分析器,例如关键字,标准,简单,滚雪球。没有分析仪的知识,我无法确定真正适合我的需求。 问题答案: 我给你一个简短的答案。 在索引时间和搜索时间使用分析
-
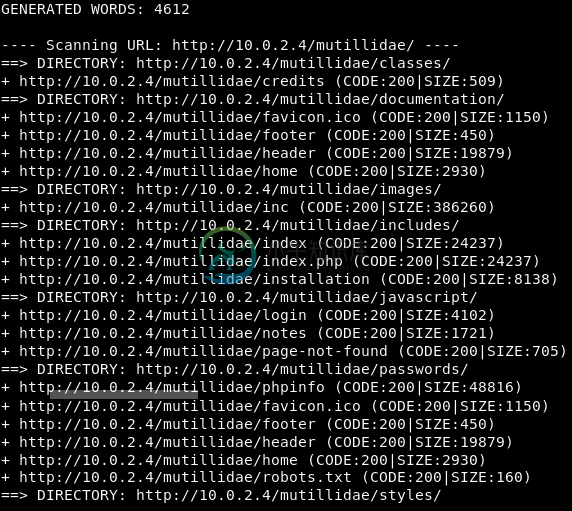 分析发现文件
分析发现文件在下面的屏幕截图中,可以看到dirb工具能够找到许多文件的结果。下面是我们已经知道的一些文件: 在下面的屏幕截图中,我们可以看到只是一个图标文件。是我们经常看到的索引。页脚和标题可能只是样式文件。可以看到有一个登录页面。 现在,我们可以通过利用一个非常复杂的漏洞找到目标的用户名和密码。但我们最终无法登录,因为无法找到登录的位置(页面)。在这种情况下,像这样的工具会很有用。我们查看文件通常非常有用,
-
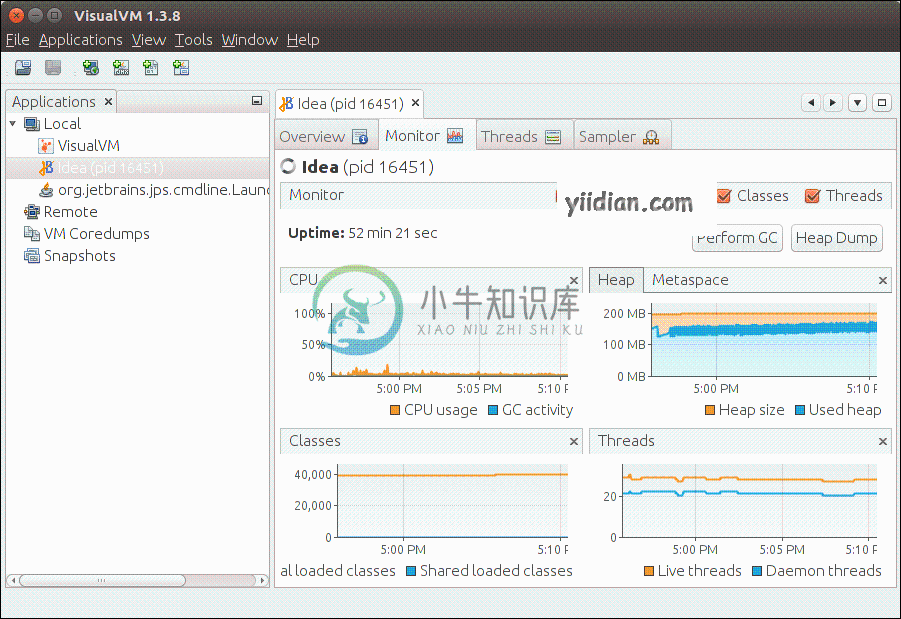 Intellij Idea Profiler分析器
Intellij Idea Profiler分析器主要内容:什么是 VisualVM?,配置,监控应用,螺纹测量,抽样申请,CPU采样,内存采样,内存泄漏Profiler 提供了有关我们应用程序性能的准确信息。它通过我们的应用程序测量 CPU、内存和堆使用的性能。它还为我们提供了有关应用程序线程的详细信息。VisualVM 工具用于测量 Java 应用程序分析。 什么是 VisualVM? 它是一个可视化工具,已与 JDK 以及 Java 6 或更高版本捆绑在一起。它适合初学者,并提供有关我们应用程序性能的详细信息。 配置 在 Windows
-
 Java HashMap原理分析
Java HashMap原理分析主要内容:1 什么是哈希(散列)(Hashing),2 HashMap hashCode()方法,3 HashMap equals()方法,4 HashMap 存储桶,5 HashMap的索引计算过程,6 HashMap get()方法,7 HashMap原理分析完整代码本文主要介绍HashMap工作原理,了解哈希算法的计算过程。 1 什么是哈希(散列)(Hashing) 哈希是通过使用方法hashCode() 将对象转换为整数形式的过程。必须正确编写hashCode() 方法,以提高HashM
-
7.21.Dijkstra 算法分析
最后,让我们看看 Dijkstra 算法的运行时间。我们首先注意到,构建优先级队列需要 $$O(V)$$ 时间,因为我们最初将图中的每个顶点添加到优先级队列。 一旦构造了队列,则对于每个顶点执行一次 while 循环,因为顶点都在开始处添加,并且在那之后才被移除。 在该循环中每次调用 delMin,需要 $$O(logV)$$时间。 将该部分循环和对 delMin 的调用取为 $$O(Vlog(V
-
6.14.查找树分析
随着二叉搜索树的实现完成,我们将对已经实现的方法进行快速分析。让我们先来看看 put 方法。其性能的限制因素是二叉树的高度。从词汇部分回忆一下树的高度是根和最深叶节点之间的边的数量。高度是限制因素,因为当我们寻找合适的位置将一个节点插入到树中时,我们需要在树的每个级别最多进行一次比较。 二叉树的高度可能是多少?这个问题的答案取决于如何将键添加到树。如果按照随机顺序添加键,树的高度将在 $$log2