《数据分析工程师》专题
-
事件分派线程如何工作?
问题内容: 在人们的帮助下,我能够获得以下简单的GUI倒数的工作代码(它仅显示一个倒数秒的窗口)。我的这段代码的主要问题是东西。 据我了解,它将任务发送到事件分发线程(EDT),然后EDT在“可以”时执行该任务(无论如何)。 那正确吗? 据我了解,代码的工作方式如下: 在方法中,我们用来显示窗口(方法)。换句话说,显示窗口的代码将在EDT中执行。 在该方法中,我们还启动,计数器(通过构造)在另一个
-
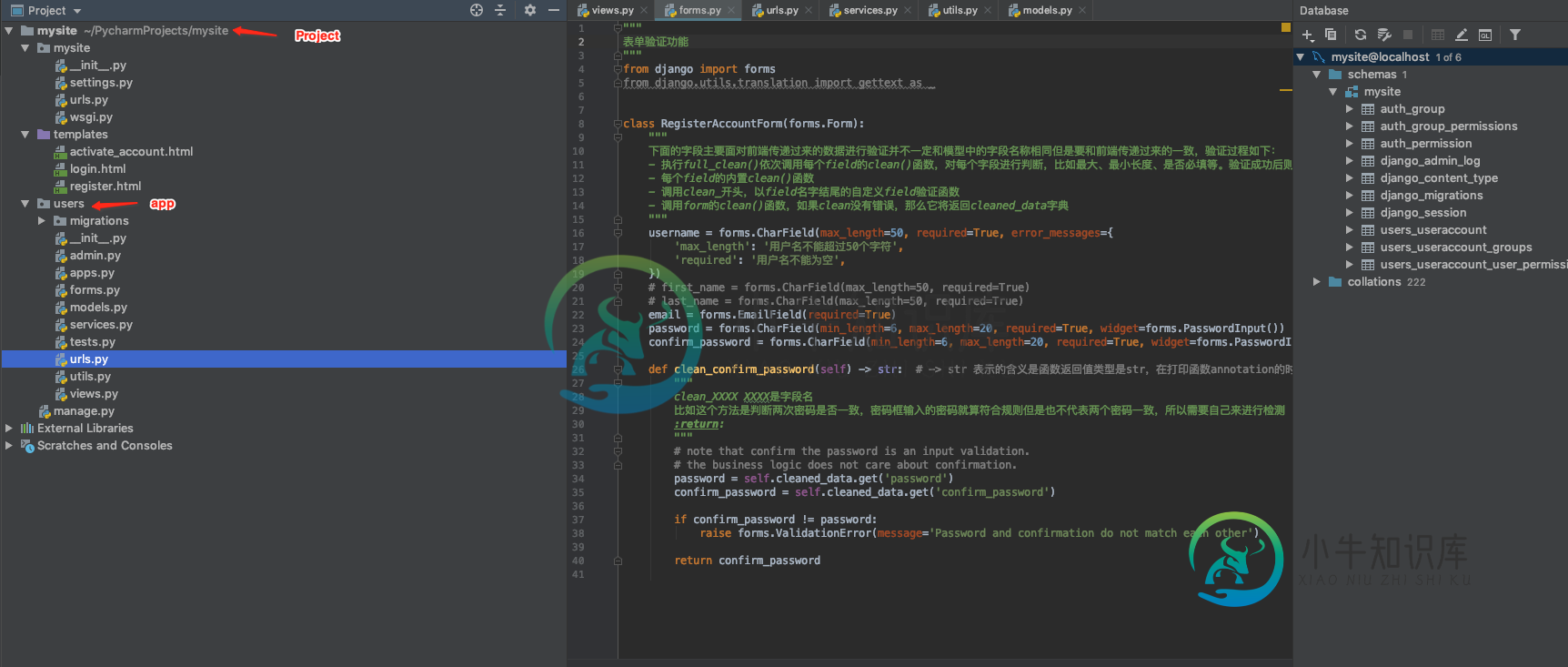 Django工程的分层结构详解
Django工程的分层结构详解本文向大家介绍Django工程的分层结构详解,包括了Django工程的分层结构详解的使用技巧和注意事项,需要的朋友参考一下 前言 传统上我们都知道在Django中的MTV模式,具体内容含义我们再来回顾一下: M:是Model的简称,它的目标就是通过定义模型来处理和数据库进行交互,有了这一层或者这种类型的对象,我们就可以通过对象来操作数据。 V:是View的简称,它的工作很少,就是接受用户请求换句话
-
如何拆分部分数据,但部分数据在MySQL、PSQL中保持不变
我将列的一些数据保存如下: 我需要的是所有的中文单词,我们不需要英文单词和'-',但不是所有的值都是带和英文单词的,所以我不能用SQL下面,有没有人知道怎么实现?
-
 字节 Data 大数据开发工程师1 2 3 4面 已挂
字节 Data 大数据开发工程师1 2 3 4面 已挂1面(1h)8.2 项目介绍 MapReduce提交作业流程 MapReduce和spark的区别 HDFS架构 HDFS写流程 groupByKey和reduceBykey的区别 算法题(实现一个类,插值(已存在就false,不存在就插入),删除值(不存在这个值就返回false,存在就删除),随机获取已存储的值,三个功能时间复杂度为O(1)) 2面(45min)8.10 项目介绍 数仓理解 ja
-
 23秋招 补录 阿里 数据研发工程师 面经 已offer
23秋招 补录 阿里 数据研发工程师 面经 已offer准备面试过程中搜数据开发岗面经还是费了点劲的 所以在此记录一下攒人品 之后各位uu能多一点参考 背景 阿里的数据研发(不是大数据研发)校招的时候对技术要求不高比较随意 所以我这种数据分析岗位背景的人简历也是秒过 还有蚂蚁的某些数据开发也是这样的 之前找过我说现有的技术栈没问题 但我因为自我感觉不行+对数据分析的执着给拒了!!大家不要学我可以多看看机会 数据分析岗位基本趋于饱和 只看大公司+数据分析
-
 10.22 大数据工程师 阿里国际 百度 面经(带答案)
10.22 大数据工程师 阿里国际 百度 面经(带答案)数据库底层索引的优劣势? 数据库底层索引的优势和劣势主要取决于具体的索引类型和使用场景: 优势: 提升查询性能:索引可以加快数据库的查询速度,通过跳过不需要的数据块,减少了磁盘I/O操作。 加速排序:索引可以帮助数据库对查询结果进行排序,从而提高排序的效率。 支持唯一性约束:索引可以保证某一列或多列的唯一性,保证数据的完整性。 提高并发性能:索引可以减少数据的锁竞争,提高数据库的并发性能。 支持数
-
 理想 智能驾驶数据运营工程师一面 base北京
理想 智能驾驶数据运营工程师一面 base北京11.17投递-11.21一面 面试+反问一共1h20min,目前一周了无后续,感觉可能寄了,就分享一下。 自我介绍。 深挖字节数据运营的经历。 深挖腾讯综合项目管理的经历。(挖到这里时间就已经过去了50min。。。 建筑学专业为什么投递这个岗位? 因为我上一个问题表示不喜欢建筑行业喜欢压着ddl工作的模式,于是面试官说这边也会有ddl,问对ddl的看法。(我补充说明ddl是要有的,建筑行业的问题
-
 2022暑期实习-面试-美的集团-数据挖掘工程师
2022暑期实习-面试-美的集团-数据挖掘工程师公司:美的集团 岗位:数据挖掘工程师 形式:视频面试 视频面试平台:腾讯会议 面试官:技术负责人和 HR 时长:20分钟 流程: 0、面试官自我介绍 1、自我介绍 技术负责人(13分钟) 2、介绍一个项目(用户购买行为预测)。具体是怎么做预测的? 3、对于 AdaBoost 和 XGBoost 的理解?什么时候用?为什么用? 4、(另一个项目)介绍一下怎么开展的项目?简单介绍一下设计思路。 5、对
-
 字节跳动 大数据开发工程师一面面经 (社招)
字节跳动 大数据开发工程师一面面经 (社招)1、自我介绍 2、跳槽理由 3、介绍团队 4、自己感觉做的最好的项目(扣的很细,聊了很久) 5、遇到过的技术问题 6、数据倾斜如何解决 7、缓慢变化维怎么解决 8、周期变化事实数据,比如七天累计订单表应该放哪一层?为什么? 9、什么数仓才算一个好的数仓 10、雪花模型跟星型模型区别 11、写sql题 12、反问 面了三家 淘天、字节、pdd,都offer了,这个草稿也是当时写的一直忘发了,后面有空
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:CTO线-数据产品与技术部 岗位:数据研发工程师 形式:电话面试 时长:22分钟 流程: 1、自我介绍。 2、介绍一下实习的工作。 3、这个项目中有几个人? 4、在项目中遇到了什么困难? 5、实习的公司有没有类似数据中台的部门? 6、在数据预处理方面做了哪些事情?怎么保障数据的规范性和准确性? 7、介绍一下建模的工作。 8、学校里有没有学过数据挖掘相关的课程? 9、对于分类和
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:信贷事业群-风险管理部 岗位:数据研发工程师 形式:电话面试 时长:31分钟 流程: 1、自我介绍。 2、对数据开发岗有了解吗? 3、实习的时候接触到的数据来自哪里? 4、你是怎么理解数据仓库这个岗位的? 5、你刚才提到了数据沉淀,那你觉得有哪些方法来做数据沉淀? 6、如果让你做数据ETL的话你有兴趣吗? 7、对大数据的技术栈哪些比较熟悉? 8、传统的数据仓库和关系型数据库有
-
数据框架-连接/分组依据-聚集-分区
我可能对加入/组By-agg有一个天真的问题。在RDD的日子里,每当我想执行a. groupBy-agg时,我曾经说reduceByKey(PairRDDFunctions)带有可选的分区策略(带有分区数或分区程序)b.join(PairRDDFunctions)及其变体,我曾经有一种方法可以提供分区数量 在DataFrame中,如何指定此操作期间的分区数?我可以在事后使用repartition(
-
Apache Scala/Python Spark 2.4.4:按年份范围分组数据以生成/分析新特性
下面是我为特性工程生成的数据框架,现在为了驱动另一个特性,我试图创建列,其中我希望创建一个具有3年范围的列,并通过聚合值。 例如:对于项目编号7010032,我们将在新的列和列中有一个具有1995-1996-1997值的行,这些年的PurchaseRatio值将在相应的行中汇总。接下来,我将在接下来的3年中也这样做,即1996-1997-1998,1997-1998-1999等。 此外,该项目有一
-
分析Android L的数据失败。不支持的主要部分。次要版本51.0
在为Eclipse安装了ADT插件之后,我尝试制作了一个新的Hello world Android应用程序。 但我在尝试打开一个新的Android应用程序时遇到了以下错误。我正在使用JDK7.0和JRE7.0。我最初使用的是JDK6.0,但遇到了同样的错误,因此我卸载了它,安装了JDK7.0,并分别更改了路径设置。 错误显然是: 为Android L(预览版)加载数据遇到了问题。分析Android
-
 分享一些最近数据分析/产品方向实习面试的题目吧~
分享一些最近数据分析/产品方向实习面试的题目吧~面了三家互联网,b站携程小红书,拿了一家实习offer,问的比较多的题记录分享一下。 一开始都是先自我介绍,然后就是做题。。 首先是SQL题。 1.左连接和右连接的区别 2.union 和 union all的区别 3.熟悉开窗函数吗?讲一下row_number和dense_rank的区别。 4.hive行转列怎么操作的 5.要求手写的题主要考了聚合函数和开窗,row_number(),sum()