《数据分析工程师》专题
-
以编程方式分析jar文件
问题内容: 我需要以编程方式计算给定jar文件中已编译类,接口和枚举的数量(因此我需要三个单独的数字)。哪个API对我有帮助?(我不能使用第三方库。) 我已经尝试过非常棘手的方案,这似乎并不总是正确的。即,我将每个ZipEntry读入byte [],然后将结果提供给我的自定义类加载器,该加载器扩展了标准CalssLoader并将此byte []发送到ClassLoader.defineClass(
-
 三一重工23届校园提前批大数据开发工程师岗笔试
三一重工23届校园提前批大数据开发工程师岗笔试三一重工笔试大家都说挺简单的,还是提前批,所以最近也没抽时间来复习,直接上来裸考。 题目全是选择题,有三十道单选题,十道多选题。笔试限时一小时做完,实际上不到十分钟大部分就选完了。以下凭记忆记录几个题目,当然我也很多没做对~ 算是查缺补漏了。 1. hadoop 环形缓冲区大小? 2. spark 行动算子和转换算子识别? 参考链接: https://blog.csdn.net/weixin_
-
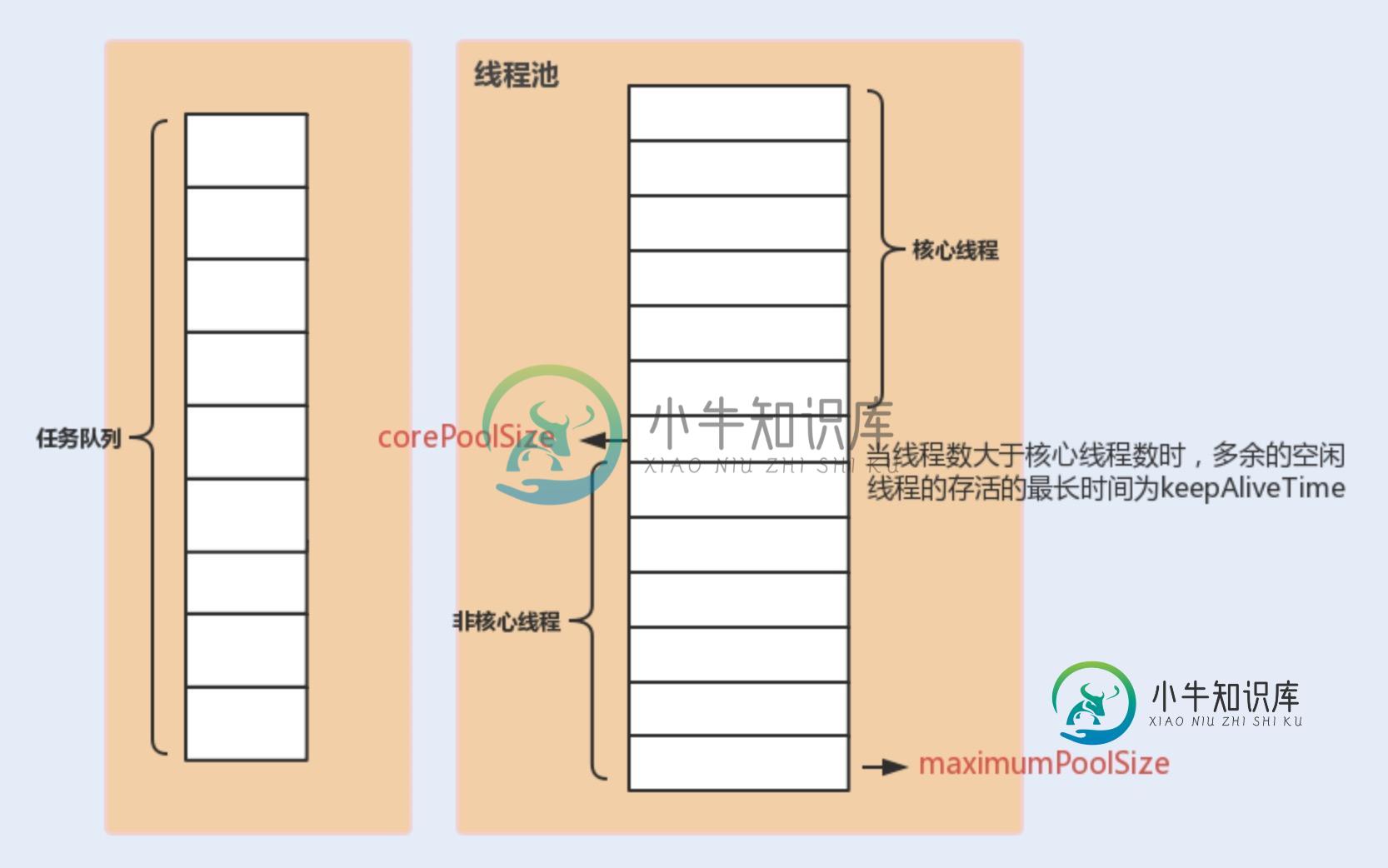 ThreadPoolExecutor 构造函数重要参数分析?
ThreadPoolExecutor 构造函数重要参数分析?本文向大家介绍ThreadPoolExecutor 构造函数重要参数分析?相关面试题,主要包含被问及ThreadPoolExecutor 构造函数重要参数分析?时的应答技巧和注意事项,需要的朋友参考一下 : : 核心线程数线程数定义了最小可以同时运行的线程数量。 : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。 : 当新任务来的时候会先判断当前运行的线程数量是否
-
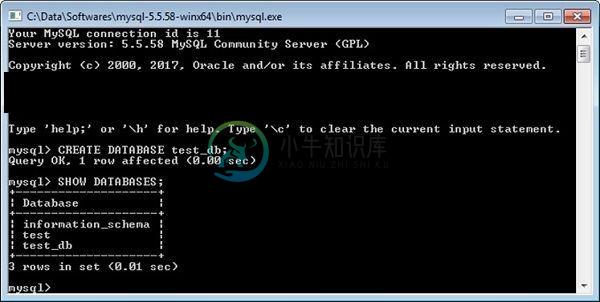 Intellij Idea 数据库工具
Intellij Idea 数据库工具主要内容:创建数据库,连接到数据库,创建表,插入数据,查询数据IntelliJ 提供了数据库工具,允许您从 IDE 本身执行数据库相关操作。它支持所有主要数据库,如 MySQL、Oracle、Postgress、SQL 服务器等等。在本章中,我们将讨论 IntelliJ 如何支持 MySQL 数据库。 我们假设读者熟悉数据库概念,并且在您的系统上安装和配置了所需的数据库工具。 创建数据库 首先,我们将创建一个数据库: test_db。在命令提示符下执行以下命
-
数据库工具(Database Tools)
PyCharm支持各种类型数据库的接口支持。 一旦用户授予对创建的数据库的访问权限,它就会使用提供代码完成的SQL编写工具提供数据库的架构图。 在本章中,我们将重点介绍MySQL数据库连接,这将涉及以下步骤。 添加数据源 重要的是要记下PyCharm支持各种数据库连接。 Step 1 打开数据库工具窗口View -》 Tool Windows -》 Database》并打开名为Data Sourc
-
数据库迁移工具
数据库迁移工具 首先通过 composer 安装 composer require topthink/think-migration 注意事项,不支持修改文件配置目录 在命令行下运行查看帮助,可以看到新增的命令 php think migrate migrate:create Create a new migration migrate:rollback Rollback t
-
Redis数据查看工具
Redis 数据查看工具,是一个方便查询 Redis 中数据的工具目前只支持查看功能,不支持修改、删除(太危险)
-
分析或未分析,选择什么
问题内容: 我仅使用kibana搜索ElasticSearch,并且我有几个只能接受几个值的字段(最坏的情况,服务器名,30个不同的值)。 我确实了解分析对像这样的更大,更复杂的字段执行的操作,但是对于那些简单的小字段,我却无法理解分析/未分析字段的优点/缺点。 那么,对于“有限的一组值”字段(例如,服务器名:server [0-9] *,没有特殊字符可以打破),使用analyd和not_anal
-
反向工程mysql数据库以创建Django应用
问题内容: 我基本上想采用由php应用程序(codeigniter框架)创建和使用的现有mysql数据库结构,并将其反向工程为django应用程序。有一些工具可以做到这一点吗?南迁徙也许? 问题答案: 创建一个项目,然后将设置指向@数据库 然后跑 这将为您指向的数据库打印出python模型文件 您可以通过执行以下操作将其输出到文件中 然后,您可以将文件移动到最合适的位置,并根据需要进行编辑。
-
 腾讯云智暑期实习-数据工程 一面
腾讯云智暑期实习-数据工程 一面1.上来就是三个题 (1)sql:给出一个学生信息表,求出每个班级人数占全年级人数的比例; (2)hive sql:A表10亿条数据,B表10万条数据,都含有 uid 和 name 两个字段 1)求出A表与B表uid的差(A表中有,B表中没有); 2)求出B表中的所有uid。 (3)有list1= [2, 4 , 7], list2 = [3, 6, 9],都是升序排列,将其合并成一个新的升序链表
-
 腾讯视频-数据工程暑期实习一面
腾讯视频-数据工程暑期实习一面腾讯这次暑期实习没有笔试,做了测评之后,就发了面邀了,2024.03.19今天下午面试,时长一个半小时,面试官人很好,但是鼠鼠太菜了,估计要G,不过还是记录一下面试问题吧。 1.聊了一下研究生的方向以及跟着导师做的项目,大概沟通了下。 2.然后问了下实习经历,做了哪些事,遇到了哪些问题,怎么解决的。 3.平时使用到哪些组件,然后问了一些八股: 有没有遇到数据量过大,导致代码运行时间慢的问题?做过哪
-
 腾讯日常实习数据工程一面面经
腾讯日常实习数据工程一面面经原本投的后台开发,后面被数据工程捞了,因为隔了有一个多月没怎么准备所以状态很差。 一开始先自我介绍, 然后开始挖实习,实习简单的说了三个小任务,问的主要还是有关大数据的东西,全程push,脑子空白有点说不出来。 后面开始JAVA八股, 先说的JVM的分区,有什么堆栈,性能调优,垃圾回收机制, hotspot的新生代和老年代, 创建线程的方法,回答了继承thread和runnable接口,又说run
-
 快手 数据开发工程师 一面二面三面 凉经
快手 数据开发工程师 一面二面三面 凉经一面 50 min 一位技术很强的老哥 面试体验很好 0.开场热身 自我介绍 你以后的业务倾向于做哪一块? 1.项目相关 介绍下你的第一个Spark 项目 双流Join,讲一下过程 你的数据过期时间是多久?为什么这么设置? 双流 join 之后你的数据会从Redis 里面删除吗? 你说到了用Redis 来缓存延迟的数据,如果缓存存储的数据过多会出现什么问题,怎么解决? 猜:会出现OOM问题,我觉得
-
 美团 机器学习/数据挖掘算法工程师hr面
美团 机器学习/数据挖掘算法工程师hr面到这里为止,所有流程都走完了。 9月8日 一面,当天出结果 9月12日 二面,当天出结果 9月14日 三面,次日出结果 9月19日 hr面 1. hr上来先介绍了一下这个岗位未来具体做的事情,介绍的很详细。 2. 让我自己讲讲对这个岗位的理解 3. 自我介绍 4. 聊天 ①职业规划 ②你说你是美团的忠实用户,你可以聊聊你自己对美团的印象吗 (本人是究极吃货+旅游爱好者,出去旅游几乎全靠美团订酒店+
-
 美团 机器学习/数据挖掘算法工程师 三面
美团 机器学习/数据挖掘算法工程师 三面9月8日 一面,当天出结果 9月12日 二面,当天出结果 1. 自我介绍 2. 项目介绍,围绕项目出发询问一些相关的问题。这个过程在15分钟左右。 3. :你前面写题了吗 我:一面写了,二面没写 4. 在我以为要出题的时候,没有了……进入反问环节 我:啊!怎么这么快 :因为我们这个三轮的技术面是一个综合的评估,有些问题前两面面过了,就没必要再问了 后续流程:说本次面试的结果很快就会出。还剩最后一轮