《龙湖集团》专题
-
 SQL Server集合操作符
SQL Server集合操作符本节将学习如何使用集合运算符(包括:,和)来组合输入查询中的多个结果集。 这几个集合操作符的详细说明和用法,可通过以下链接学习: UNION - 将两个或多个查询的结果集合并到一个结果集中。 INTERSECT - 返回两个或多个查询的结果集的交集。 EXCEPT - 查找两个输入查询的两个结果集之间的差集。
-
GitLab持续集成简介
主要内容:特征,优点GitLab CI(持续集成)服务是GitLab的一部分,它负责管理项目和用户界面,并允许对每次提交进行单元测试,并在构建失败时显示警告消息。 特征 它集成在GitLab界面中。 由于使用简单,结果更快等原因,在过去几年里它已经赢得了更多的人气。 它允许项目团队成员每天整合他们的工作。 整合错误可以通过自动构建轻松识别。 它可以在多种平台上执行,例如Windows,Unix,OSX和其他支持Go编
-
Guava 集合应用示例
Guava 引入了许多基于开发人员在应用程序开发工作中的经验的高级集合。下面给出了一个有用的集合列表: 集合名称 描述 Multiset Set 接口的扩展以允许重复元素。 Multimap Map 接口的扩展,以便其键可以一次映射到多个值。 BiMap Map 接口的扩展以支持逆操作。 Table Table表示一个特殊的映射,其中可以以组合方式指定两个键来引用单个值。
-
Java12 垃圾收集增强
主要内容:JEP 189 : Shenandoah:一个低暂停时间的垃圾收集器(实验性),JEP 346 : 及时返回未使用的已提交内存,JEP 344:可中止的混合集合Java 12 为其垃圾收集算法引入了多项增强功能。 JEP 189 : Shenandoah:一个低暂停时间的垃圾收集器(实验性) 引入了一个实验性的低暂停时间垃圾收集器 Shenandoah 以减少 GC 暂停时间。它与运行 Java 线程并行工作。这有助于减少 GC 对堆大小的依赖性并使其保持一致。现在垃圾收集暂停时间对于
-
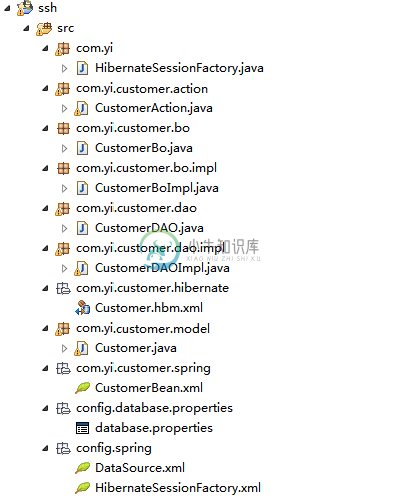 Struts2+Spring+Hibernate集成实例
Struts2+Spring+Hibernate集成实例主要内容:1. 工程文件夹结构,2. MySQL表结构结构,3. Hibernate相关配置,5. Struts2相关,6. Spring相关配置,7. JSP 页面,8. struts.xml,9. Struts 2 + Spring,10. 运行实例,参考在本教程中,它显示的集成 “Struts2 + Spring + Hibernate“,请务必检查以下之前继续学习教程。 Struts2 + Hibernate集成实例 Struts2 + Spring 集成实例 参见集成步骤总结: 获取所
-
要列出的结果集
问题内容: 我想将结果集转换为JSP页面中的列表。并希望显示所有值。这是我的查询: 我已经执行,使用 PreparedStatement的 ,并得到了 结果集 。但是如何将其转换为 列表 并希望显示如下结果: 问题答案: 您需要在循环中逐行遍历 ResultSet 对象,以提取每个列值:
-
集的伪随机遍历
问题内容: 我一直在阅读《 游戏编码完成》(第4版) ,但在理解第3章“有用的东西的袋子”一节中的“一组伪随机遍历”路径时遇到一些问题。 您是否想过CD播放器上的“随机”按钮如何工作?它会随机播放CD上的每首歌曲,而不会播放同一首歌曲两次。这是一个非常有用的解决方案,可确保游戏中的玩家在有机会再次看到相同功能之前,先看到最广泛的功能,例如对象,效果或角色。 在描述之后,将继续讨论我尝试用Java实
-
Spring 4和Rest WS集成
问题内容: 我一直在做Spring4和RestWS集成的POC。我对这两者都是陌生的,仅仅接触了一周。我正在按照博客的指示进行操作。我了解到,在Spring 4和restWS设置中,将使用jackson-core / anotation / databind 2进行JSON <-> Java对象的正确消息转换。也用于消息转换。我满足了所有这些要求。但是,当我尝试启动应用程序时,出现bean创建异常
-
持续集成服务器
问题内容: 我的公司正在考虑更改连续集成服务器(我不会说我们现在拥有哪台服务器,因此无论如何我都不会歪曲您的回答:))我想知道是否有人提出建议?最佳的用户体验,维护难度等… 我们的代码全部使用Java,并且我们将ANT用作构建工具。 问题答案: 我最近实现了哈德森服务器。以前使用过Cruise Control, 我对Hudson感到非常满意,并且对它的易于设置和使用印象深刻。 与Cruise Co
-
Jenkins中的集成测试
-
 万集科技二面8.26
万集科技二面8.261.自我介绍 2.简单介绍项目里面一个功能实现 3.追问了一下项目细节实现 4.yolo模块用opencv的dnn来实现,了解opencv吗? 5.一个线程读缓存,一个线程写缓存,读完缓存需要删除缓存,有什么问题? 6.TCP收到的数据可靠吗? 7.怎么看TCP数据有没有断包、连包、粘包? 8.研究方向是什么领域? 9.C++接触多久了? 然后直接结束了。。。 #万集科技#
-
查询集方法参考
本文档描述了QuerySet API的详细信息。它建立在模型和数据库查询指南的基础上,所以在阅读本文档之前,你也许需要首先阅读这两部分的文档。 本文档将通篇使用在数据库查询指南中用到的Weblog 模型的例子。 何时对查询集求值(要写到程序里的字段麻烦不要自作聪明翻译谢谢) 在内部,可以创建、过滤、切片和传递查询集而不用真实操作数据库。在你对查询集做求值之前,不会发生任何实际的数据库操作。 你可以
-
HBase 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Regin Server。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。 二、前置条件
-
Storm 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nim
-
弹性式数据集 RDD
一、RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性: 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,