《阿里云分布式块存储》专题
-
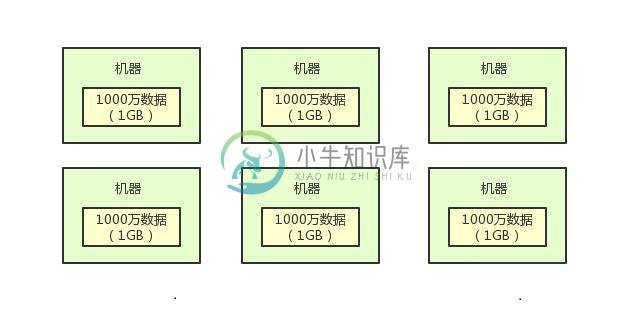 什么是分布式计算系统?如何设计分布式系统?
什么是分布式计算系统?如何设计分布式系统?主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
 阿里大文娱_阿里影业_前端实习_一二三面
阿里大文娱_阿里影业_前端实习_一二三面部门:阿里影业 base上海 面试平台:钉钉 一面 24.05.28 50mins 一分钟自我介绍 虚拟dom的作用是什么 js的基础数据类型 如何判断数据类型 css选择器优先级 css如何避免样式污染 es6新出的map和set是什么,具体应用场景 webpack的loader和plugin ts的范型 封装组件和npm发包相关 面向对象编程的思想 面向对象编程和函数式编程 软件工程的设计理念
-
 阿里智能信息二面挂,至此暑期无缘阿里
阿里智能信息二面挂,至此暑期无缘阿里阿里信息二面 6.1--- 最汗流浃背的一集,先是自我介绍,然后问了一下职业规划。 ①一个线程和协程之间区别 ②协程的两种类型(这我真不会) 之后就是两道场景题手撕 ①给定一个input文件,文件中有大量的不重复的数字,数字的范围不超过七位数,内存空间只给2MB,如何排序后输出到一个ouput文件中。 这里我首先说用归并排序的思想来做,每次从文件中读取2MB数据到内存中进行排序,再将文件输出到一个
-
 阿里数分15分钟就面完了,是不是稳挂了
阿里数分15分钟就面完了,是不是稳挂了就做了自我介绍,然后问了实习经历,考了一个sql的题目和一个sql的运行顺序 就直接结束了,说了解的也了解完了,也没有工作经验,也不知道可以问什么了 两段实习已经不能算工作经验了吗
-
在哪里为Artifactory发布指定存储库元素?
我试图在Artifactory存储库中发布一个项目。这是一个依赖于我的主项目的项目,所以我想把pom、.jar和sources.jar放在artifactory存储库中。 settings.xml文件存储在maven目录中: 我已经使用以下maven命令标记了版本: 那么,如果我尝试: ,我得到了错误: [信息][错误]未能在项目上执行目标org.apache.maven.plugins:mave
-
 分享阿里实习算法0326笔试编程题
分享阿里实习算法0326笔试编程题1. 送分题:考场上有n种类型题目,输入是每种题目的题数和得分,算在最多做出k题的情况下,最大得分是多少。 2. 给一个有根树,和每个节点的权值,求所有子树里第k大的子数权值。一个子树权值是其所有节点权值之和。 3. 取数游戏,甲先取,如果某个人取了奇数,那么另一个人必须跳过下一个数取后面的;如果某个人取了偶数,那后面那个人可选择跳或者不跳再取数,注意可以连续跳大于1个。输入一个数组和它的长度,输
-
 阿里淘天行业运营面试问题分享
阿里淘天行业运营面试问题分享1、自我介绍 2、详细介绍某段实习内容:包括具体工作内容和数据结果。 追问:运营前后的数据表现如何?你认为达到这种效果最有效的策略是什么? 追问:你在其中最大的收获是什么? 追问:你在团队中扮演什么角色? 3、详细介绍另一段相关实习:包括具体工作内容和数据结果。 追问:你认为新品品牌成长到有销量过程中最重要的是什么?为什么? 追问:怎么将新品运营成为优质品?(从产品侧、运营侧、价格侧、营销侧、购买
-
分布式计算框架 —— MapReduce
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
6.6 分布式配置管理
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
6.4 分布式搜索引擎
在Web一章中,我们提到MySQL很脆弱。数据库系统本身要保证实时和强一致性,所以其功能设计上都是为了满足这种一致性需求。比如write ahead log的设计,基于B+树实现的索引和数据组织,以及基于MVCC实现的事务等等。 关系型数据库一般被用于实现OLTP系统,所谓OLTP,援引wikipedia: 在线交易处理(OLTP, Online transaction processing)是指
-
6.1 分布式 id 生成器
有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id。以支持业务中的高并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。 在插入数据库之前,我们需要给这些消息、订单先打上一个ID,然后再插入到我们的数据库。对这个id的要求是希望其中能带有一些时间信息,这样即使我
-
第6章 分布式系统
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
其他 - 分布式manager节点
为了保证manager节点的容错性,我们最好将manager节点个数设定为奇数个。在网络被划分成2个部分情况下,奇数个manager节点能够较高程度的保证有投票结果的可能性。如果网络被划分成2个部分以上,投票有结果的可能性将不能被保证。 Swarm节点数 法定票数 允许manager不可用个数 1 1 0 2 2 0 3 2 1 4 3 1 5 3 2 6 4 2 7 4 3 8 5 3 9 5
-
分布式锁和同步器
Lock Redisson 分布式可重入锁,实现了 java.util.concurrent.locks.Lock 接口并支持 TTL。 RLock lock = redisson.getLock("anyLock"); // Most familiar locking method lock.lock(); // Lock time-to-live support // releases loc
-
 分布式集群Hadoop和Hbase
分布式集群Hadoop和Hbase我有两个节点的完全分布式Hadoop和Hbase实例。HDFS在主机和从机上工作良好。但是HBase shell只在节点名格式化之后工作一次,并且集群是新的,之后我得到错误:error:org.apache.hadoop.HBase.PleaseHoldException:Master is initializing HBase 我也不能通过hbase shell从slave连接我总是得到错误连接