《数据仓库与数据分析实习》专题
-
Laravel Database 数据库 - Laravel Database——查询构造器与语法编译器源码分析(中)
join 语句 join 语句对数据库进行连接操作,join 函数的连接条件可以非常简单: DB::table('services')->select('*')->join('translations AS t', 't.item_id', '=', 'services.id'); 也可以比较复杂: DB::table('users')->select('*')->join('contacts',
-
Laravel Database 数据库 - Laravel Database——查询构造器与语法编译器源码分析(上)
前言 在前两个文章中,我们分析了数据库的连接启动与数据库底层 CRUD 的原理,底层数据库服务支持原生 sql 的运行。本文以 mysql 为例,向大家讲述支持 Fluent 的查询构造器 query 与语法编译器 grammer 的原理。 DB::table 与 查询构造器 若是不想使用原生的 sql 语句,我们可以使用 DB::table 语句,该语句会返回一个 query 对象: publi
-
 很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)
很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)本文向大家介绍很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码),包括了很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)的使用技巧和注意事项,需要的朋友参考一下 Mysql数据库、数据库表、数据基础操作笔记分享给大家,供大家参考,具体内容如下 一、数据库操作 1.创建数据库 Create database db name[数据库选项]; tip:语句要求使用语句结束符"
-
Spark数据帧的分区数
有人能解释一下将为Spark Dataframe创建的分区数量吗。 我知道对于RDD,在创建它时,我们可以提到如下分区的数量。 但是对于创建时的Spark数据帧,看起来我们没有像RDD那样指定分区数量的选项。 我认为唯一的可能性是,在创建数据帧后,我们可以使用重新分区API。 有人能告诉我在创建数据帧时,我们是否可以指定分区的数量。
-
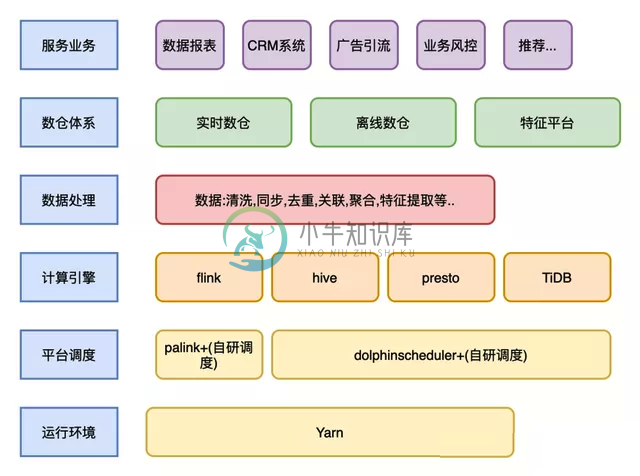 实时数仓之 Kappa 架构与 Lambda 架构
实时数仓之 Kappa 架构与 Lambda 架构主要内容:1.数据仓库概念,2.离线大数据架构,3.Lambda 架构,4.Kappa 架构,5. Lambda 架构与 Kappa 架构的对比1.数据仓库概念 数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。 数据仓库概念是 Inmon 于 1990 年提出并给出了完整的建设方法。随着互联网时代来临,数据量暴增,开始使用 大数据工具 来替代经
-
如何获得总计数的数据从在aws appinc分页的动态数据库?
我正在使用aws放大网络应用程序。我使用Appsync GraphQL作为Web服务器。但是我不知道如何通过aws appinc从Dynamodb获得数据总数。请帮帮我。
-
javax.naming.NoInitialContextException与mysql数据源
问题内容: 尝试连接到MySQL数据库 和堆栈跟踪: 由行引起:ctx.bind(“ jdbc / wczasy”,mysqlDs); 我被困住了,有人可以帮我吗?谢谢。 问题答案: 这是因为未实现接口。 如果您不在容器中,则可以使用rmi注册表。就像是:
-
1.3.2 数据与方法
当一个 Vue 实例被创建时,它向 Vue 的响应式系统中加入了其data对象中能找到的所有的属性。当这些属性的值发生改变时,视图将会产生“响应”,即匹配更新为新的值。 // 我们的数据对象 var data = { a: 1 } // 该对象被加入到一个 Vue 实例中 var vm = new Vue({ data: data }) // 获得这个实例上的属性 // 返回源数据中对应
-
2.1. 表单与数据
2.1. 表单与数据 在典型的PHP应用开发中,大多数的逻辑涉及数据处理任务,例如确认用户是否成功登录,在购物车中加入商品及处理信用卡交易。 数据可能有无数的来源,做为一个有安全意识的开发者,你需要简单可靠地区分两类数据: l已过滤数据 l被污染数据 所有你自己设定的数据可信数据,可以认为是已过滤数据。一个你自己设定的数据是任何的硬编码数据,例如下面的email地址数据: $email
-
数据与模型篇
无论是MVC、MVP或者MVVP,都离不开这些基本的要素:数据、表现、领域。 数据 信息源于数据,我们在网站上看到的内容都应该是属于信息的范畴。这些信息是应用从数据库中根据业务需求查找、过滤出来的数据。 数据通常以文件的形式存储,毕竟文件是存储信息的基本单位。只是由于业务本身对于Create、Update、Query、Index等有不同的组合需求就引发了不同的数据存储软件。 如上章所说,View层
-
 蔚来-数字系统数据分析师-一面面经
蔚来-数字系统数据分析师-一面面经7月18号约面试,7月19号下午面试。面试官挺和蔼的,但是我感觉是kpi面试。 面试内容:1、自我介绍。 2、因为简历没有实习经历,面试官询问了一下。 3、问会什么编程软件,Python,Sql,介绍了一下会的库和算法。 4、反问环节面试官介绍了一下工作内容等。 有友友投了一样的岗位可以一起交流呀! #蔚来面试##数据分析#
-
有关数据库SQL递归查询在不同数据库中的实现方法
本文向大家介绍有关数据库SQL递归查询在不同数据库中的实现方法,包括了有关数据库SQL递归查询在不同数据库中的实现方法的使用技巧和注意事项,需要的朋友参考一下 本文给大家介绍有关数据库SQL递归查询在不同数据库中的实现方法,具体内容请看下文。 比如表结构数据如下: Table:Tree ID Name ParentId 1 一级 0 2 二级 1 3 三级 2 4 四级 3 SQL S
-
Spring数据r2dbc和分组依据
我正在使用DatabaseClient执行sql查询,我不知道如何通过以下方式进行分组:
-
python数据分析:关键字提取方式
本文向大家介绍python数据分析:关键字提取方式,包括了python数据分析:关键字提取方式的使用技巧和注意事项,需要的朋友参考一下 TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴。使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性。 TF-IDF的概念 TF-IDF有两部
-
如何进行探索性数据分析(EDA)?
本文向大家介绍如何进行探索性数据分析(EDA)?相关面试题,主要包含被问及如何进行探索性数据分析(EDA)?时的应答技巧和注意事项,需要的朋友参考一下 EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info