《数据分析面试》专题
-
 快手数据分析实习(凉经)
快手数据分析实习(凉经)👥 面试题目 投递渠道:实习僧,方向:电商的用户增长 下面就是面试问题啦: 1.基本工作情况确认(时间,时长) 2.现场手撕代码(这部分花的久):用户信息、用户行为两个表 问题一:筛选四月日活跃用户,不同性别groupby 问题二:筛选次日留存用户(前一日活跃、后一日也活跃) 3.问我对电商的理解 4.反问:我问了此岗位对于电商的工作内容,编程和业务的占比 面试感受:很直,对简历没有深挖,直接上
-
 网易互娱游戏数据分析
网易互娱游戏数据分析下午一面,能得到这个机会还是很惊喜的,但感觉自己大概率过不了,没有过实习,机器学习半吊子水平,就当做和面试官聊天吧,增长一点见识为以后去中小厂做准备,希望能和面试官好好聊聊 凉面分享 两个面试官(一个偏技术一个偏hr?),面试前10分钟蓝牙耳机出了问题,迫不得已用打游戏的头戴式耳机去面试了,md回头才发现全是杂音,面完感觉凉透了(大概时长30分钟) 自我介绍 技术相关面试(好像我菜了,没多的东西能
-
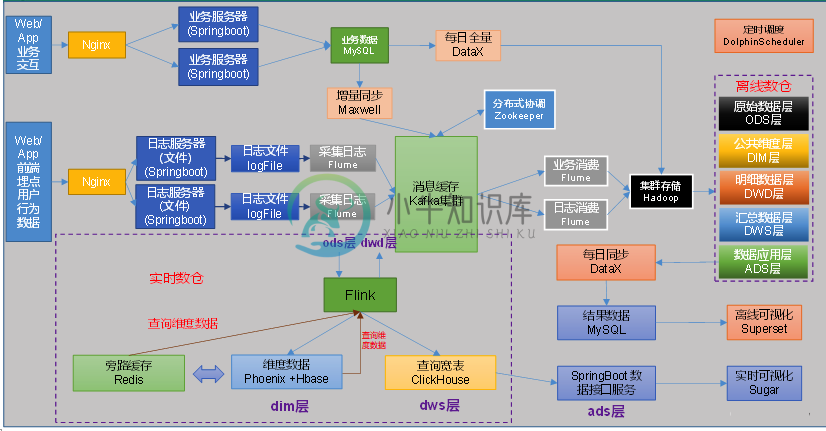 数据仓库建模过程分析
数据仓库建模过程分析主要内容:1.数据仓库概述,2.数据仓库建模概述,3.维度建模理论之事实表,4.维度建模理论之维度表,5.数据仓库设计1.数据仓库概述 1.1 数据仓库概念 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。 1.2 数据仓库核心架构 2.数据仓库建模概述 2.1 数据仓库建模的意义 数据模型就是
-
 拼多多数据分析师凉经
拼多多数据分析师凉经一面: 1.涉及过数据挖掘的项目讲一讲,这里分错的样本有没有研究一下为什么会分错。 2.讲一讲SVM、XGBOOST原理。 3.知不知道决策树剪枝,具体怎么做的,在哪一步做 4.知不知道LightGBM 5.深度学习有没有了解? 6.过拟合的L1范数和L2范数有什么区别? 7.mapreduce原理和过程 8.给key,value两列,找出每个key里第二大的值并输出。用python自己定义一个数
-
 数据分析面试题|如何提升app的用户参与度
数据分析面试题|如何提升app的用户参与度******************* 春招保驾护航! 参考回答: - 第一步:定义指标。几乎所有的产品案例研究都从一个模糊的目标开始,第一步是将此目标转化为可以优化的指标。 比如。 "我将小红书上用户的参与度定义为每天至少采取一项行动的用户比例,其中行动意味着与网站互动,即发布、喜欢、上传图片等" 。 - 在指标确定之后,选择我们认为对该指标起到影响的变量特征。比如用户特
-
 2023暑期实习-面试-美的集团-数据分析工程师
2023暑期实习-面试-美的集团-数据分析工程师公司:美的集团 岗位:数据分析工程师-大数据 形式:视频面试 视频面试平台:腾讯会议 面试官:数据分析师、HR 时长:22分钟 流程: 1、自我介绍。 2、介绍一段实习经历。 3、(实习项目深挖)提到的这些指标如何影响最终的决策? 4、(实习项目深挖)你刚才提到会有其他方面的影响因素,如何排除这些影响因素? 5、了解哪些常用的业务分析方法? 6、Hive SQL的熟练度怎么样? 7、报表开发过程中
-
 滴滴数据分析面试3~5|日常实习面经国际化部门
滴滴数据分析面试3~5|日常实习面经国际化部门面经3 9月7日笔试:SQL题,要求30分钟内完成。给一个表,查询用户数、订单总额、统计留存率。 一面,9月8日,25分钟 1. 自我介绍。 2. 深挖实习+项目。 3. 留存率公式。 4. 搭建一个数据指标体系。 5. 大数定理与中心极限定理。 6. 假设检验。 7. AB实验相关。 8. 反问。 面经4 1. 自我介绍+项目与简历介绍。 2. 为什么想来滴滴? 3. 学过哪些数据分析相关的课程
-
7.1.5剖面分析
在“分析”菜单栏中点击“剖面分析”,有绘制线和选择线两个选项,这里讲绘制线。分析的精度由地形数据的精度决定。 在三维地形上绘制一条想要进行剖面的线路,绘制完成后自动弹出默认采样间距(默认计算的合理值)的分析剖面示意图如下,重新设置采样点采样间距后,再点击“分析”,可重新生成剖面示意图。 点击“分析”键右侧的收放按键可显示出各个采样点数的经度纬度和高程值信息
-
9.2.5剖面分析
在“分析”菜单栏中点击“剖面分析”,有绘制线和选择线两个选项,这里讲绘制线。分析的精度由地形数据的精度决定。 在三维地形上绘制一条想要进行剖面的线路,绘制完成后自动弹出默认采样间距(默认计算的合理值)的分析剖面示意图如下,重新设置采样点采样间距后,再点击“分析”,可重新生成剖面示意图。 点击“分析”键右侧的收放按键可显示出各个采样点数的经度纬度和高程值信息
-
 快手电商数据分析实习面经(一面+二面,最终去向)
快手电商数据分析实习面经(一面+二面,最终去向)一面(7.4) 自我介绍 介绍一个数据分析的项目 你是什么时候做的这个项目 分析一下交易总额下降的原因 说一下抖音和快手的不同 写一个SQL # 1.每日活跃用户 select dt, count(*) activate_number from active_user_di where dt between '2022-11-01' and '2022-11-30' group
-
 Hibernate框架数据分页技术实例分析
Hibernate框架数据分页技术实例分析本文向大家介绍Hibernate框架数据分页技术实例分析,包括了Hibernate框架数据分页技术实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Hibernate框架数据分页技术。分享给大家供大家参考,具体如下: 1.数据分页机制基本思想: (1)确定记录跨度,即确定每页显示的记录条数,可根据实际情况而定。 (2)获取记录总数,即获取要显示在页面中的总记录数,其目的是根据该数来确
-
 分享一些最近数据分析/产品方向实习面试的题目吧~
分享一些最近数据分析/产品方向实习面试的题目吧~面了三家互联网,b站携程小红书,拿了一家实习offer,问的比较多的题记录分享一下。 一开始都是先自我介绍,然后就是做题。。 首先是SQL题。 1.左连接和右连接的区别 2.union 和 union all的区别 3.熟悉开窗函数吗?讲一下row_number和dense_rank的区别。 4.hive行转列怎么操作的 5.要求手写的题主要考了聚合函数和开窗,row_number(),sum()
-
 联想-DT数字化转型-数据分析工程师-一二面面经(oc)
联想-DT数字化转型-数据分析工程师-一二面面经(oc)一面9.18 群面,而且和mkt、市场等背景的同学,海外高校居多,还有位清华本硕小姐姐惊呆我了。 选一个行业,讨论行业转型的痛点和方案及价值 (本以为过不了,不过从这次从其它岗位的同学上学到了很多群面的技巧,有时间再系统总结一下) 二面9.25 介绍实习 公司类型倾向 有没有数据质量的处理经历 base天津,一次非传统的面试经历?一般联想这个岗位好像也不会群面,后来oc发现是捞起来给了
-
 数据模型面试题与解析1
数据模型面试题与解析1面试高频题1: 题目:介绍一下k-means,你的数据如何处理,模型的输出是什么? 答案解析: 介绍kmeans: 第一步:数据归一化、离群点处理后,随机选择k个聚类质心 第二步:所有数据点关联划分到离自己最近的质心,形成k个簇; 第三步:重新计算每个簇的质心; 重复第二步、第三步,直到簇不发生变化或达到最大迭代次数; 数据如何处理: 为了防止均值和方差大的维度将对数据的聚类产生决定性影响,所以在
-
 数据处理面试题与解析1
数据处理面试题与解析1面试高频题1: 题目:处理噪声数据方法 答案解析: 1、分箱 分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。所谓“分箱”,实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。在采用分箱技术