《大数据分析》专题
-
Python标准库,用于发布多部分/表单数据编码的数据
问题内容: 我想发布多部分/表单数据编码的数据。我已经找到了执行此操作的外部模块:http : //atlee.ca/software/poster/index.html 但是我宁愿避免这种依赖性。有没有办法使用标准库来做到这一点? 谢谢 问题答案: 标准库当前不支持该功能。有一些食谱,其中包括您可能只想复制的一小段代码,以及对替代方法的长时间讨论。
-
分布式(非关系型数据库)数据库中的一致性效应
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
如何检查到Oracle数据库的最大允许连接数?
问题内容: 使用SQL检查Oracle数据库允许的最大连接数的最佳方法是什么?最后,我想显示当前的会话数和允许的总数,例如“当前使用80个连接中的23个”。 问题答案: 确定Oracle数据库支持的连接数时可能会有一些不同的限制。最简单的方法是使用SESSIONS参数和V $ SESSION,即 数据库配置为允许的会话数 当前活动的会话数 但是,正如我所说,在数据库级别和操作系统级别,以及是否已配
-
具有对数插入/删除和"no-大于"的数据结构
我现在正在解决一个编码挑战,我有一个解决方案,但是为了让它工作,我需要一个支持四个操作的数据结构: 插入O(对数(N)) 我尝试使用Java的来解决它,它可以通过添加,,和(并检查最后两个的大小)来支持这些操作。但是这个解决方案太慢了。我还没有检查时间复杂性,但是我有一种感觉,不能在对数时间内运行(或者运行效率低下)。 有人知道我可以实现一个数据结构来支持这些操作吗?这可能吗?如果它是树形的,最好
-
 科大讯飞——大数据开发工程师(最汗流浃背的一集)
科大讯飞——大数据开发工程师(最汗流浃背的一集)面试内容 一面: 1、对那些数据库比较熟悉? 2、mysql优化? 3、数仓的架构,每一层的作用? 4、你做的项目中数据清洗放在哪一层? 5、数据怎么接入数仓的? 6、实时项目也做过?说一下flink处理数据的流程 7、任务断了,有重复数据怎么办?(我以flink为例说了怎么避免) 二面:不问技术 1、之前实习交过社保没? 2、从之前的上司那里学到了什么?只说一点 3、对未来的规划? 4、整体的实
-
数据库元数据
表元数据 下面这些方法用于获取表信息: 列出数据库的所有表 $this->db->list_tables(); 该方法返回一个包含你当前连接的数据库的所有表名称的数组。例如: $tables = $this->db->list_tables(); foreach ($tables as $table) { echo $table; } 检测表是否存在 $this->db->table_
-
 pandas数据分组groupby()和统计函数agg()的使用
pandas数据分组groupby()和统计函数agg()的使用本文向大家介绍pandas数据分组groupby()和统计函数agg()的使用,包括了pandas数据分组groupby()和统计函数agg()的使用的使用技巧和注意事项,需要的朋友参考一下 数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据
-
计算数据框列中每个值的百分位数
问题内容: 我正在尝试从DataFrame计算列中每个值的百分位数。 有没有更好的方法来编写以下代码? 我希望看到更好的性能。 问题答案: 似乎您想要: 性能:
-
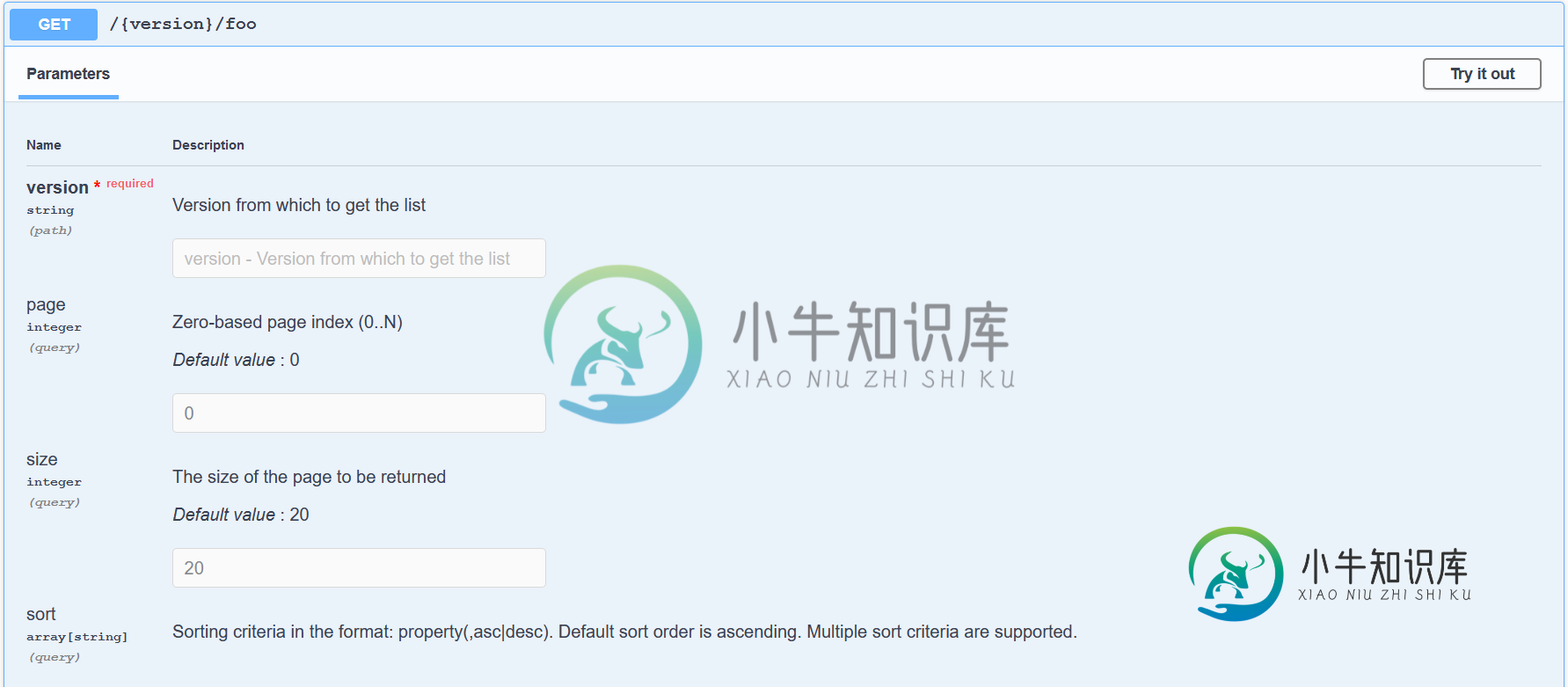 Springdoc数据REST忽略覆盖可分页参数名称
Springdoc数据REST忽略覆盖可分页参数名称在我的申请中。属性,我已覆盖可分页参数的名称: 但是当我去Swagger UI检查我的Swagger留档时,没有使用新的name参数: 这是我的职能部门的签名: 如何将新名称绑定到文档?我可以更改默认描述吗? 谢谢你的回答!
-
如何在Go中分配非恒定大小的数组
问题内容: 如何在Go中分配运行时大小的数组? 以下代码是非法的: 您会收到消息(或类似消息),但是效果很好: 问题是,我可能要等到运行时才能知道我想要的数组的大小。 问题答案: 答案是您不直接分配一个 数组 ,而是 在创建 slice 时 让Go为您分配一个 数组 。 内置的函数创建了一个切片 和它后面的阵列 ,并且没有(傻)上的值编译时间常数- 限制性和。正如Go语言规范中所说: 使用创建的切
-
kafka主题分区的最大复制系数是多少
我有Kafka集群有3经纪人和一对夫妇的主题,每个有5分区。现在我想为分区设置复制因子。 我可以为kafka主题的分区设置的最大复制因子是什么?
-
图具有多个连通分量时的最大边数
对于算法的最终审查,出现了这样一个问题: 由于连通组件本质上是图中的一个图,这意味着子图中的所有顶点必须从较大的图中移除,同时保持内部连通性。我能理解这种直觉,但很难把它转化成一个公式。 到目前为止,我得出的结论如下: 对于连通分量n,每个图Gn具有相应的顶点集{Vn},使得顶点集的内容在内部连接,而在外部保持不连接。 现在,每个{Vn}最多包含V*(V-1)条边。 如何用公式表示最大边数?
-
 字节数分一面压力面(大概率透心凉)
字节数分一面压力面(大概率透心凉)面试之前把牛客和小红书的面经的过了一遍 以为也会问我常用什么app然后对这个app做一些分析 没想到上来第一道是概统题,应该用贝叶斯定理就能解,但因为概统没有系统学扎实,算了很久算不出来,比较尴尬。 接下来根据简历询问了一些产品思维和商业化思维 比如京东为什么要做plus会员?对产品有什么价值?怎么通过数据做验证 最后问了一道指标构建相关的题 期间面试官多次觉得我没理解他的题意,疯狂打断我的回答,
-
分析大型Java堆转储的工具
问题内容: 我有一个HotSpot JVM堆转储,我想分析一下。VM运行时带有,堆转储文件的大小为48 GB。 我什至不会尝试,因为它需要大约五倍的堆内存(在我的情况下为240 GB),而且速度非常慢。 在分析了几个小时的堆转储后,Eclipse MAT崩溃了。 还有哪些其他工具可用于该任务?最好使用一套命令行工具,其中包括一个程序,该程序将堆转储转换为有效的数据结构以进行分析,再结合使用其他几个
-
HTML是否区分大小写?
问题内容: HTML是否区分大小写? 在一个示例中,我正在使用它说: 还是会有所不同(或根本没有)? 问题答案: 否,但是将HTML标记保持小写被认为是一种好习惯。