《大数据分析》专题
-
grp — Unix 分组数据库
Querying All Groups # grp_getgrall.py import grp import textwrap # Load all of the user data, sorted by username all_groups = grp.getgrall() interesting_groups = { g.gr_name: g for g in all_g
-
 数据分析24暑期实习总结(3)-淘天数分oc
数据分析24暑期实习总结(3)-淘天数分oc写在前面 bg:9本+水硕,投递时实习经历:中厂数分+大厂数据产品+大厂数分本身数学统计基础很差,ml相关基础也差,求职意向主要为业务向数分手动加粗:希望认出的大佬手下留情,私聊就好,社恐害怕评论区掉马甲。也欢迎各位牛友交流哇!打破信息差~ ---分割线--- 岗位:淘天-天猫事业部-数据分析 tl:3.19投递-4.6一面-4.7二面-4.12oc-5.17再次oc。。 ---分割线--- 一面
-
为什么H2数据库文件大小的增长超过了数据大小
我有一个h2数据库文件,文件大小已经增长到5GB。我删除了一些数据以缩小文件的大小。但即使从数据库中删除了一半记录,文件大小仍然保持不变。 我已经尝试了以下所有选项来减少数据库大小,但没有一个对我有用。 我的连接字符串如下所示: 注: 我们正在结清我们已经开始的交易 文件中没有5GB的数据 有人能给我建议一些解决方法或修复方法来减少我的数据库大小吗
-
Spring数据排序操作超出最大大小
我是相当新的Spring和MongoDB,并有一个问题,从我的MongoDB拉数据。我试图获得相当大的数据量,并收到以下异常: 执行器错误:操作失败:排序操作使用超过最大33554432字节的RAM。添加索引,或指定一个较小的限制。;嵌套异常是com.mongodb.MongoExc0019: Execator错误:操作失败:排序操作使用超过内存的最大33554432字节。添加索引,或指定较小的限
-
Neo4j查找数据库的最大字节大小
我找到了关于如何计算neo4j数据库大小的以下信息:https://neo4j.com/developer/guide-sizing-and-hardware-calculator/#_disk_storage
-
加载大于 h2o 中内存大小的数据
我正在尝试在h2o中加载大于内存大小的数据。 H2o博客提到: 下面是连接到h2o 3.6.0.8的代码: 给 我试着把一个169 MB的csv加载到h2o中。 这抛出了一个错误, 这表示内存溢出错误。 问:如果H2opromise加载大于其内存容量的数据集(如上面的博客引述所说的交换到磁盘机制),这是加载数据的正确方法吗?
-
 兴金数金,大数据实习面经
兴金数金,大数据实习面经一,上来就问了项目里日志的处理量,50w 100M左右 二,问项目里如何解决Hbase的热点问题,面试官没听明白,后面就直接问热点问题如何解决的 答的就举年份例子,加盐,预分区 三,Kafka里是如何leader和follow是如何实现同步的 具体怎么实现同步我确实不知道,我就答的是offset在follow和leader挂了后如何在实现同步的,面试官说我似乎说了又没说明白,后面查了一下,下
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
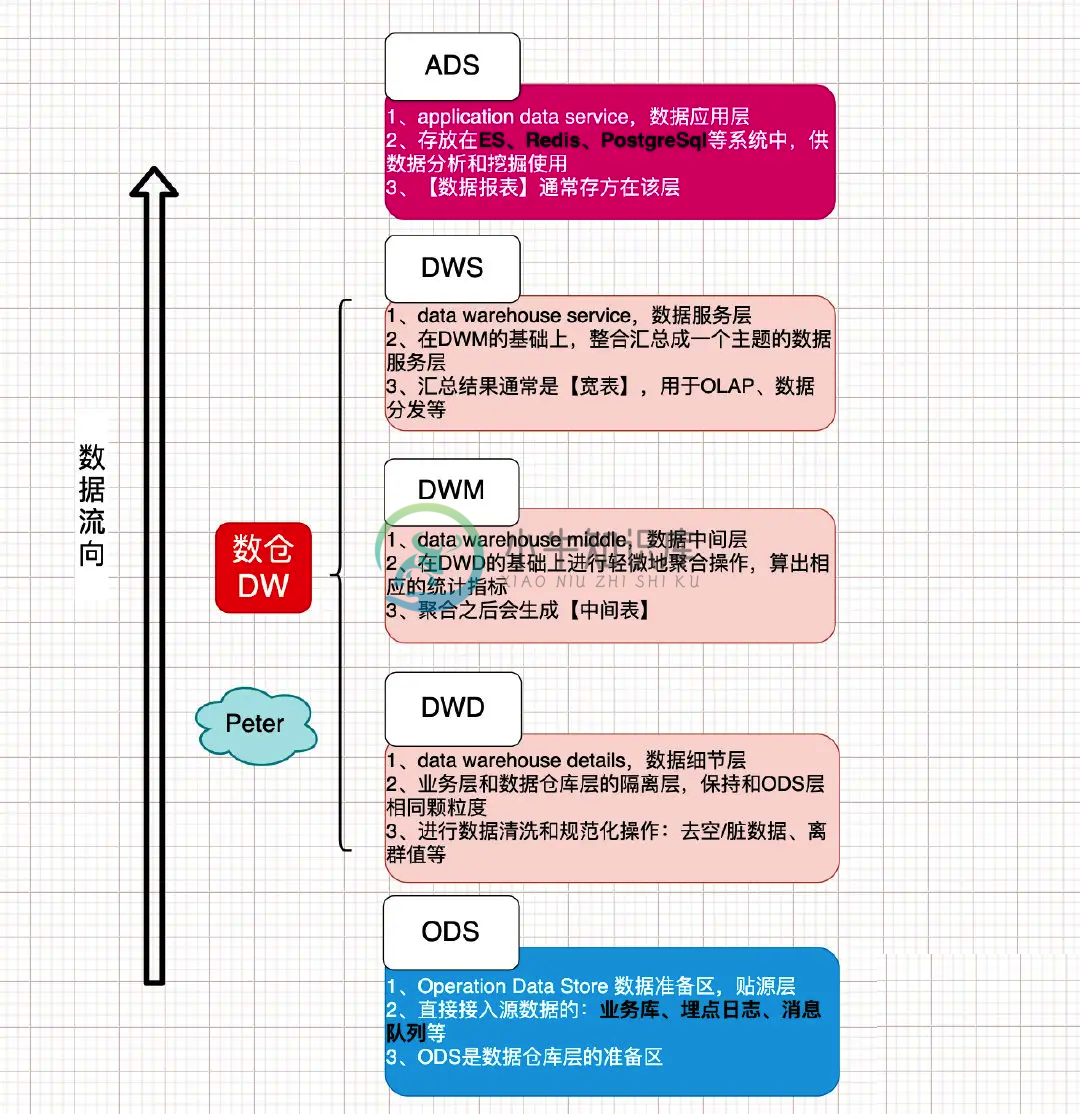 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
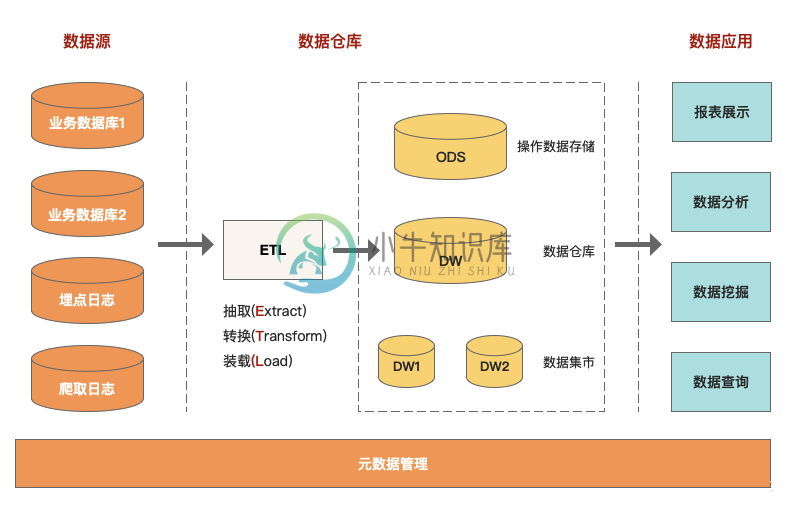 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
Python-将数据框拆分为多个数据框
问题内容: 我有一个非常大的数据框(大约一百万行),其中包含来自实验的数据(60位受访者)。我想将数据框分成60个数据框(每个参与者一个数据框)。 在数据帧(称为=数据)中,有一个名为“名称”的变量,它是每个参与者的唯一代码。 我已经尝试了以下方法,但是没有任何反应(或者一小时内没有停止)。我打算做的是将数据帧(数据)拆分为较小的数据帧,并将其附加到列表(数据列表)中: 我没有收到错误消息,脚本似
-
kafaka 生产数据时数据的分组策略
本文向大家介绍kafaka 生产数据时数据的分组策略相关面试题,主要包含被问及kafaka 生产数据时数据的分组策略时的应答技巧和注意事项,需要的朋友参考一下 生产者决定数据产生到集群的哪个 partition 中 每一条消息都是以(key,value)格式 Key 是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个 partition
-
删除数据库中的数据。分离实例
当我尝试从数据库中删除数据时: 我得到一个错误: 但当我换成: 数据被删除了。为什么? 我想看看实体是否得到了管理: 我看到了真实。 那为什么呢? 在一种情况下会产生错误?
-
 深入分析python数据挖掘 Json结构分析
深入分析python数据挖掘 Json结构分析本文向大家介绍深入分析python数据挖掘 Json结构分析,包括了深入分析python数据挖掘 Json结构分析的使用技巧和注意事项,需要的朋友参考一下 json是一种轻量级的数据交换格式,也可以说是一种配置文件的格式 这种格式的文件是我们在数据处理经常会遇到的 python提供内置的模块json,只需要在使用前导入即可 你可以通过帮助函数查看json的帮助文档 json常用的方法有load