《不内卷》专题
-
Cocoa AutoLayout:内容拥抱与内容抗压缩优先
有人能解释一下它们的用法和区别吗?
-
脚本使用JVM的堆内存或系统内存
我的问题是,如果我从java代码调用Shell脚本,脚本使用的内存,是从JVM堆空间分配,还是使用系统内存空间。
-
将 EhCache 磁盘存储内容加载到内存中
如EhCache留档所述: 实际上,这意味着持久性内存中缓存将启动,其所有元素都将在磁盘上。[...]因此,Ehcache设计不会在启动时将它们全部加载到内存中,而是根据需要懒惰地加载它们。 我希望内存缓存启动时将所有元素都存储在内存中,我该如何实现? 这是因为我们的网站对缓存执行了大量的访问,所以我们第一次访问网站时,它的响应时间非常长。
-
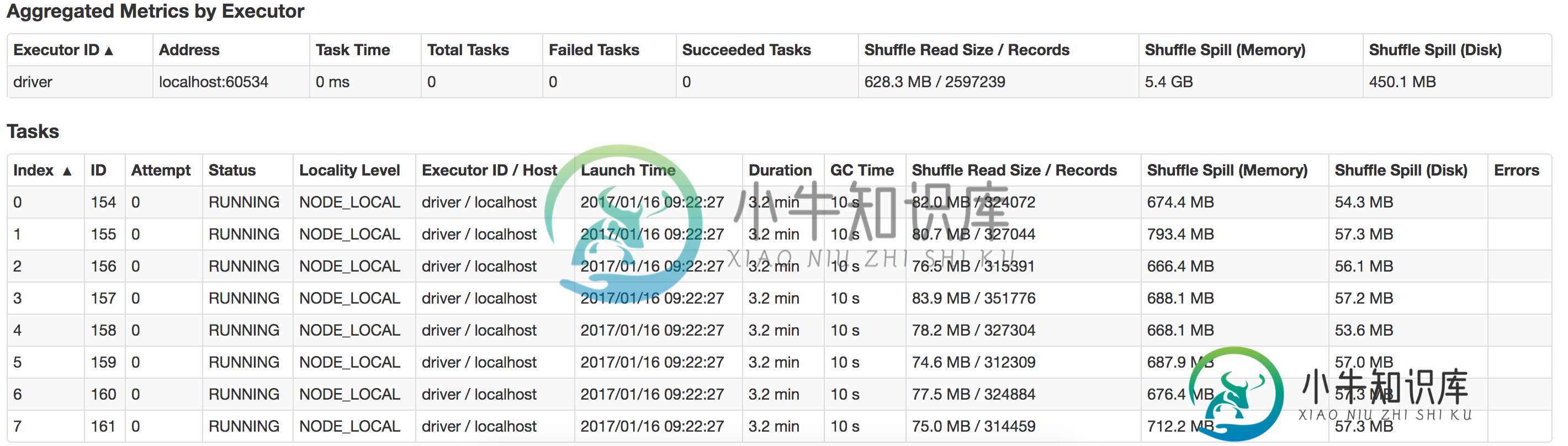 火花驱动程序内存和执行器内存
火花驱动程序内存和执行器内存我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
我如何用Python刮取'sorting_1'类内部的内容?
我接到了一个制作covid追踪器的项目。我决定在该站点(https://www.worldometers.info/coronavirus/)中添加一些元素。我对python很陌生,所以决定用BeautifulSoup。我能够刮出基本元素,比如总案例,活动案例等等。然而,每当我试图获取国家名称或数字时,它返回一个空列表。即使存在一个类'sorting_1',它仍然返回一个空列表。有人能指引我哪里错
-
从内存流中提取(字符串)文件内容
我有一个位于Azure Data Lake Store上的文件,我正在编写一个apiendpoint以将该文件的内容作为字符串检索。我遇到的问题是,当我尝试读取流时,我得到一个空字符串。这是我正在使用的: 目前,返回文件的响应工作正常,我可以在PC上打开文件并读取其内容。使用StreamReader返回文件内容的响应返回空字符串。
-
RSS轨迹是保留内存还是提交内存?
为了降低RSS,我正在Java8上运行不同jvm选项的实验: > 用于Rss跟踪的脚本: 用于设置java进程的JVM args: 与JCMD进行差异:
-
默认库伯内特斯Pod内存使用?[重复]
我定义了一个StatefulSet,里面有一个容器,它会启动。列出了CPU限制和请求,但我从未为内存指定相同的限制。我现在正在运行pod,但我不知道它们占用了多少内存。不管是什么,它都太多了,所以我想降低它。我如何知道它是什么?
-
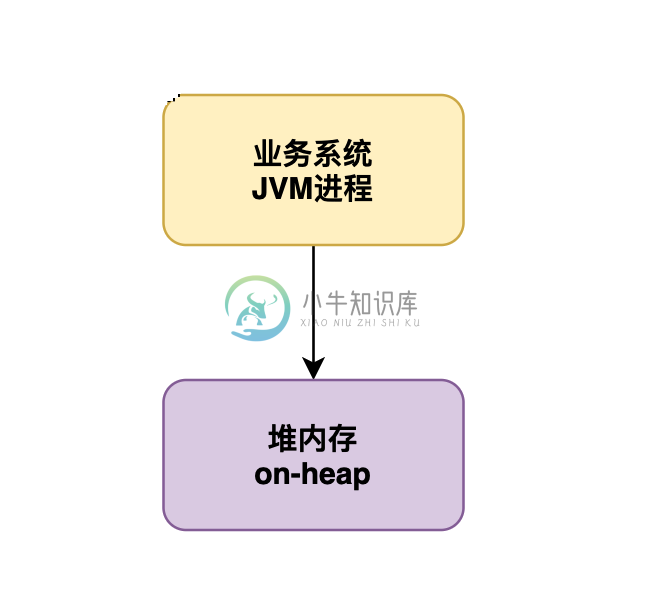 一文带你了解堆内存和堆外内存
一文带你了解堆内存和堆外内存主要内容:on-heap 堆内内存是什么?,JVM 堆内存是如何去划分的?,JVM 堆内存满了后会怎么样?,基于堆外内存解决系统 GC 卡顿问题今天给大家聊一个很有意思的知识,就是 off-heap 堆外内存,平时出去面试,或者研究一些技术的时候,经常可能会遇到 off-heap 堆外内存这个东西,但是很多人可能还不知道 off-heap 堆外内存到底是什么,所以今天就给大家来深入的分析一下。 on-heap 堆内内存是什么? 要说这个 off-heap 堆外内存,就得先说 on-heap 也就
-
第12章 内存管理 - JVM 内存模型 Stack Heap
Java虚拟机(Java Virtual Machine=JVM)的内存空间分为五个部分,分别是: 程序计数器 ava虚拟机栈 本地方法栈 堆 方法区 下面对这五个区域展开深入的介绍。 程序计数器 什么是程序计数器? 程序计数器是一块较小的内存空间,可以把它看作当前线程正在执行的字节码的行号指示器。也就是说,程序计数器里面记录的是当前线程正在执行的那一条字节码指令的地址。 注:但是,如果当前线程正
-
内存检查 - Rss与内存碎片增加问题
此时可以选择时间进行redis服务器的重新启动,并且注意在rss突然降低观察是否swap被使用,以确定并非是因为swap而导致的rss降低。 一个典型的例子是:http://grokbase.com/t/gg/redis-db/14ag5n9qhv/redis-memory-fragmentation-ratio-reached-5000
-
内存管理 - chrome devtools 如何检测内存优化?
chrome devtools 如何检测内存优化? 有哪些教程可以参考
-
在不改变位置的情况下反转字符串中的每个单词(不使用内置功能)
我想在不同的情况下反转Java中字符串的每个单词(不是整个字符串,只是每个单词)。 示例1:如果输入字符串是“这是一个测试”,那么输出应该是“sihT si a tset”。 示例2:如果输入字符串是“This is a test”,则输出应该是“sihT si a tset”。[当某些单词之间有多个空格时] 请同时提供算法以便于理解 到目前为止我都试过了
-
CUDA小内核二维卷积--怎么做
我如何用CUDA在一个相对较大的图像和一个非常小的内核(3x3)之间执行快速的2D卷积?
-
Java生成“随机”数字,该数字在2 ^ 48期间内不会重复
问题内容: 基本上,我想生成不会在很长一段时间内重复的随机数(我不想使用序列),例如java使用的LCG: 据我了解,这种情况下的种子只会在2 ^ 48次调用next之后重复出现,这是否正确? 所以据我了解,如果我做了类似的方法: 保证种子值在2 ^ 48次调用之前不会重复吗? 问题答案: 不适用于该LCG,因为每次调用时都会修改2 ^ 48(因此,周期/状态的长度最多为2 ^ 48)。如果您想要