《汇量科技Mobvista》专题
-
与Yii STAT分组汇总?
问题内容: 我有一个Yii STAT关系 ,该关系被定义为提供分组结果, 但是,当我在View中访问该关系时 , 唯一的值是最新的单个值,而不是每个值 。 例如,这是我的关系: 这将生成以下SQL: 手动运行该结果集为: 但是,我认为,如果执行以下操作: 结果很简单:,而我期望它是一个包含3个元素的数组。 是仅以STAT关系的工作方式返回1值,还是我需要做其他事情? 有可能做我想做的事吗? 问题答
-
jQuery鼠标事件汇总
本文向大家介绍jQuery鼠标事件汇总,包括了jQuery鼠标事件汇总的使用技巧和注意事项,需要的朋友参考一下 鼠标事件是在用户移动鼠标光标或者使用任意鼠标键点击时触发的。 1、click事件:点击鼠标左键时触发 $('p').click(function(){}); 示例: 2、dbclick事件:迅速连续的两次点击时触发 $('p').dbclick(function(){}); 示例
-
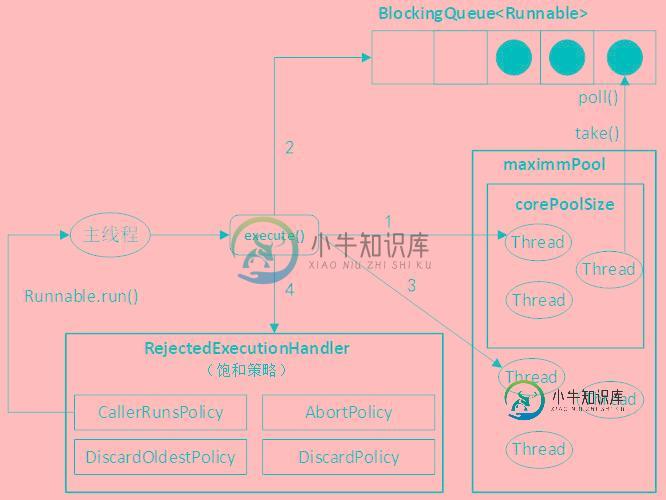 java中ThreadPoolExecutor常识汇总
java中ThreadPoolExecutor常识汇总本文向大家介绍java中ThreadPoolExecutor常识汇总,包括了java中ThreadPoolExecutor常识汇总的使用技巧和注意事项,需要的朋友参考一下 线程池技术在并发时经常会使用到,java中的线程池的使用是通过调用ThreadPoolExecutor来实现的。ThreadPoolExecutor提供了四个构造函数,最后都会归结于下面这个构造方法: 这些参数的意义如下: co
-
destoon各类调用汇总
本文向大家介绍destoon各类调用汇总,包括了destoon各类调用汇总的使用技巧和注意事项,需要的朋友参考一下 根目录、模板目录和样式目录: 导入头脚: 对应模块首页: 对应模块列表页: 发布某模块信息: 调用广告: 时间函数: 控制字符数: 版权信息: 客服电话: ICP备案号: 本月: 供应: 求购: 行情: 公司: 展会: 资讯: 招商: 品牌: 人才: 知道: 专题: 图库: 视频:
-
第3章 汇编语言
能跑就行,不行加机器。——rfyiamcool & 爱学习的孙老板 跟对人,做对事。——Rhichy Go语言中很多设计思想和工具都是传承自Plan9操作系统,Go汇编语言也是基于Plan9汇编演化而来。根据Rob Pike的介绍,大神Ken Thompson在1986年为Plan9系统编写的C语言编译器输出的汇编伪代码就是Plan9汇编的前身。所谓的Plan9汇编语言只是便于以手工方式书写该C语
-
JSON相关知识汇总
本文向大家介绍JSON相关知识汇总,包括了JSON相关知识汇总的使用技巧和注意事项,需要的朋友参考一下 JSON:JavaScript 对象表示法(JavaScript Object Notation) JSON 语法规则 数据在名称/值对中 数据由逗号分隔 花括号保存对象 方括号保存数组 JSON有6种类型的值: 对象、数组、字符串、数字、布尔值、null JSON对象是一个
-
jQuery插件开发汇总
本文向大家介绍jQuery插件开发汇总,包括了jQuery插件开发汇总的使用技巧和注意事项,需要的朋友参考一下 一、jQuery插件开发两个底层方法 jQuery.extend([deep ], target [, object1 ] [, objectN ] ) 将两个或更多对象的内容合并到第一个对象。 1、deep 如果是true,合并成为递归(又叫做深拷贝) 2、target 一个对象,如果
-
javascript基本算法汇总
本文向大家介绍javascript基本算法汇总,包括了javascript基本算法汇总的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了五个javascript算法,供大家参考,具体内容如下 1. 线性查找 2.二分查找 3.冒泡排序 4.阶乘 5.输出奇偶数控制 以上就是本文的全部内容,希望能够帮助大家更好的学习javascript程序设计。
-
PHP运行模式汇总
本文向大家介绍PHP运行模式汇总,包括了PHP运行模式汇总的使用技巧和注意事项,需要的朋友参考一下 PHP运行模式有4钟: 1)cgi 通用网关接口(Common Gateway Interface)) 2) fast-cgi 常驻 (long-live) 型的 CGI 3) cli 命令行运行 (Command Line Interface) 4)web模块模式 (apache等web服务
-
 C#各类集合汇总
C#各类集合汇总本文向大家介绍C#各类集合汇总,包括了C#各类集合汇总的使用技巧和注意事项,需要的朋友参考一下 集合(Collection)类是专门用于数据存储和检索的类。这些类提供了对栈(stack)、队列(queue)、列表(list)和哈希表(hash table)的支持。大多数集合类实现了相同的接口。 平常在工作中List<T>集合是用的最多的,其次是Array(数组).今天整理一下各类形式的集合,不用就
-
 什么是汇编语言
什么是汇编语言本文向大家介绍什么是汇编语言,包括了什么是汇编语言的使用技巧和注意事项,需要的朋友参考一下 汇编语言(assembly language)是一种用于电子计算机、微处理器、微控制器或其他可编程器件的低级语言,亦称为符号语言。在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址。在不同的设备中,汇编语言对应着不同的机器
-
JQuery工具函数汇总
本文向大家介绍JQuery工具函数汇总,包括了JQuery工具函数汇总的使用技巧和注意事项,需要的朋友参考一下 在jQuery中,工具函数是指直接依附于jQuery对象,针对jQuery对象本身定义的方法,即全局性的,我们统称为工具函数,或Utilites函数 主要作用于:字符串、数组、对象 API:工具函数 调用格式: $.函数名()或jQuery.函数名() 字符串操作: $.trim
-
Java常用命令汇总
本文向大家介绍Java常用命令汇总,包括了Java常用命令汇总的使用技巧和注意事项,需要的朋友参考一下 这篇文章就主要向大家展示了Java编程中常用的命令,下面看下具体内容。 1、javac 将文件编译成.class文件 2、java 执行 .class文件,若类中没有main函数,则不能执行。 3、jar 主要用于打包jar文件 4、javadoc 主要用于生成帮助文档。 5、javah 主要是
-
 JavaScript调试工具汇总
JavaScript调试工具汇总本文向大家介绍JavaScript调试工具汇总,包括了JavaScript调试工具汇总的使用技巧和注意事项,需要的朋友参考一下 现在的JavaScript事实上已然成为了流行的web语言,即使它并不完美。很多程序员不喜欢用JavaScript写代码,是因为写到后来总会出现各种莫名其妙的bug,而且在开发大型应用程序的过程中很容易犯错。而且鉴于当今此类工具的现状,要想在浏览器上做JavaScript
-
C++ STL库应用汇总
本文向大家介绍C++ STL库应用汇总,包括了C++ STL库应用汇总的使用技巧和注意事项,需要的朋友参考一下 1、std::max_element的使用 std::min_element类似,求最小 升级可以用到任务队列管理中,通过任务优先级,选择优先级最高的任务 知识点扩展: C++ 的标准模板库(Standard Template Library,STL)是泛型程序设计最成功应用的实例。ST