《数据挖掘》专题
-
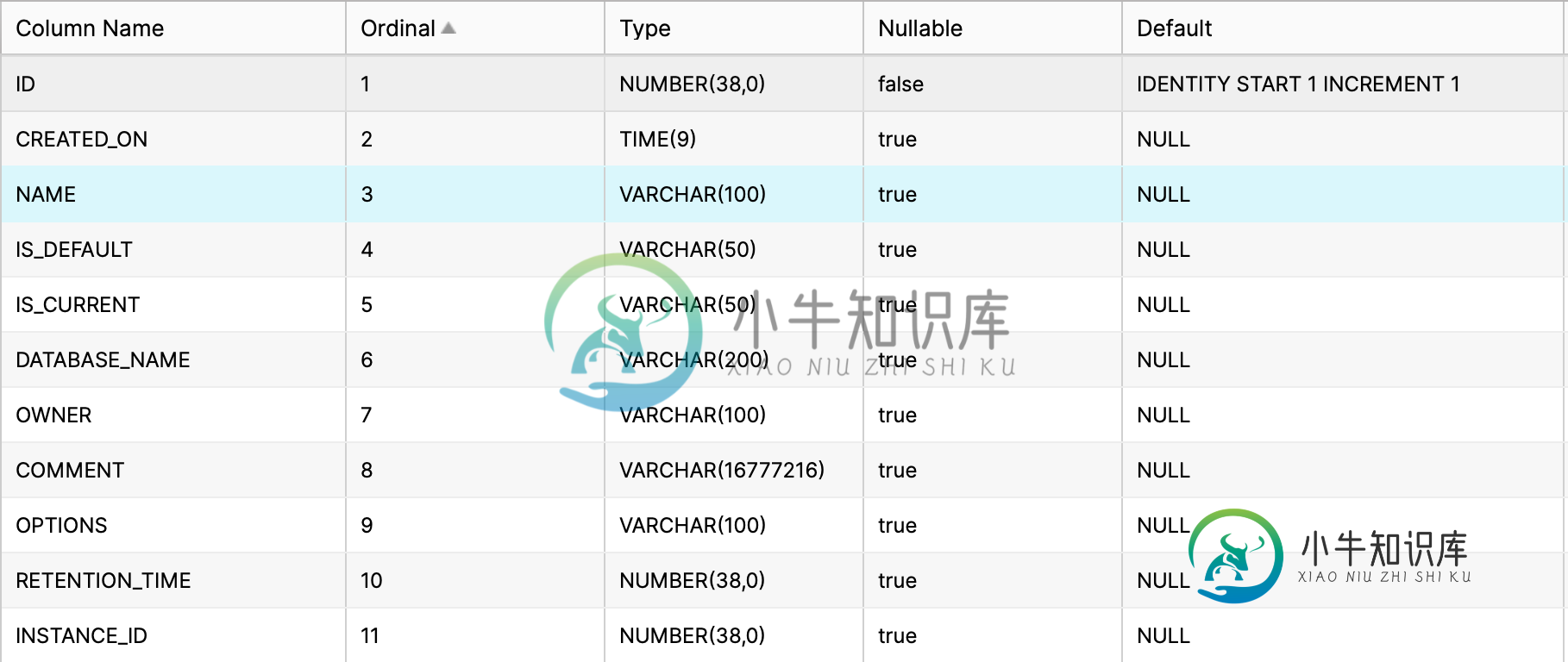 尝试使用SQLAlchemy将数据插入Snowflake数据库表
尝试使用SQLAlchemy将数据插入Snowflake数据库表我创建了一个模型使用在sql炼金术如下所示。 然后我将同一个模型移植到Snowflake数据库。 该模型有一个字段,声明为和。当我尝试插入数据到表使用雪花控制台。我必须提供,否则它不会插入数据并返回错误。 查询(成功执行,其中提供了)- 查询(当我完全忽略列时成功执行)- 查询(执行失败,其中为空)- 它返回了一个错误- 此方法的任务是将数据插入上述数据库表中。 来自SQLAlChemy的错误-
-
 滴滴-国际化数据部-大数据开发面经
滴滴-国际化数据部-大数据开发面经2023春招找实习的同学跟我分享了他的面试经历,在这里我进行了一些总结梳理,然后发出来供大家学习 注意这是日常实习!!! 1.自我介绍 2.刷题 冒泡排序 3.八股文 3.1 JVM JVM的内存结构 类的加载过程 静态代码块和代码块初始化的顺序,以及静态代码块在哪个阶段被加载【初始化】 垃圾回收器 一个方法报错了,怎么进行分析,比如A方法调用B方法,B方法调用C方法....【没太懂】 3.2 并
-
 博观大数据(数据分析岗位一面面经)
博观大数据(数据分析岗位一面面经)1.自我介绍; 2.有做过落地的实际项目没; 3.介绍一下xgboost与GBDT的关系; 4.介绍一下常用的聚类算法(K-means); 5.了解NLP吗,介绍一下BERT的结构(模型结构、任务); 6.如何缓解数据稀疏、冷启动等问题; 7.反问(主要做什么业务,具体需要使用哪些算法); 8.总结:面试过程简单,没有算法题,一面过了就说线下走流程,已拒绝;
-
5.2 新榜如何使用金数据做数据管理
在所有媒体都转型,人人都做自媒体的时代,新榜(NEWRANK.CN),作为新媒体以及整个内容生态圈最大,最专业的服务平台,在这个风口上持续服务着无数顶尖的内容创作者。新榜有着非常大量的数据收集工作,他们从一开始便选择使用互联网表单工具处理着各项需求,在对比多个工具之后,金数据成为他们最可靠的数据收集工具。 用表单做社群管理 为了更好服务于内容创业者,新榜建立了 30 个多个微信社群,并且每个社群都
-
G 数据透视表的数据源控制与刷新
G.1 数据源的刷新与更改 我们可以使用数据透视表功能,在数据源的基础上生成各种不同的报表,以满足不同层次的需求。但当我们使用数据透视表生成报告后,如果数据源变化了,数据透视表报告的信息会不会自动跟着变化呢?当更改数据源后,默认情况下数据透视表并不会自动更新。当数据源的值更改过以后,我们可以通过数据透视表的“选项”工具面板里的“数据”组的“刷新”命令来刷新数据透视表。这样数据透视表报告就变成最新的
-
第22篇 数据库(二)编译MySQL数据库驱动
导语 在上一节的末尾我们已经看到,现在可用的数据库驱动只有两类3种,那么怎样使用其他的数据库呢?在Qt中,我们需要自己编译其他数据库驱动的源码,然后当做插件来使用。下面就以现在比较流行的MySQL数据库为例,说明一下怎样在QtCreator中编译数据库驱动。 环境:Windows Xp + Qt 4.8.4+Qt Creator2.6.2 目录 一、查看怎样编译数据库驱动 二、下载MySQL 三、
-
第21篇 数据库(一)Qt数据库应用简介
导语 下面十节讲解数据库和XML的相关内容。在学习数据库相关内容前,建议大家掌握一些基本的SQL知识,应该可以看懂基本的SELECT、INSERT、UPDATE和DELETE等语句,因为在这几篇教程中使用的都是非常简单的操作,所以即便没有数据库的专业知识也可以看懂! 环境:Windows Xp + Qt 4.8.4+Qt Creator2.6.2 目录 一、数据库简介 二、数据库驱动 三、简单的数
-
jQuery EasyUI 数据网格与树插件 – Datagrid 数据网格
pre { white-space: pre-wrap; } jQuery EasyUI 插件 扩展自 $.fn.panel.defaults。通过 $.fn.datagrid.defaults 重写默认的 defaults。 数据网格(datagrid)以表格格式显示数据,并为选择、排序、分组和编辑数据提供了丰富的支持。数据网格(datagrid)的设计目的是为了减少开发时间,且不要求开发人员具
-
数据库设计 - 数据库中顺序码的问题?
向表中插入数据,记录中有一个字段涉及到当前记录是当前租户下第几个插入的,也就是顺序码,如何维护这个顺序码,在保证线程安全的情况下,不同租户的记录都保存在同一张表下, 目前的做法是插入数据的时候不插入该字段,获取该表记录列表的时候按照插入时间排序,然后判断对应字段是否为空,如果为空则插入
-
数据库 - mysql数据迁移到pgsql的最佳实践?
目前需求就是将mysql的表结构及数据迁移到pgsql. 我用的方案是使用navicate 同步数据及结构到pg, 有如下问题: mysql中的索引直接丢失了 不知道为啥一直报错表找不到 对于默认值 pgsql也丢失了 请问大家有什么好的实践吗? 我考虑的是 直接使用数据库迁移 将数据库脚本转化为pg的语法
-
后端 - 数据库统计符合条件数据优化?
场景:在一个业务流程中需要去mysql表中距离现在超过三个月的数据条数,但是如果在表格中数据较多的情况下,通过 select count(*)方法来进行统计是比较耗时的操作,同时也会影响数据的插入。 想请问一下各位前辈,有没有比较好的方案,来实现这样的功能? 我现在想的是建立一张额外的表去记录扫描的起始范围,然后通过定时器,定时移动起始范围,扫描统计。
-
数组/数据集构造函数问题
我正在创建一个程序,该程序获取用户的信息并输出最小值,最大值,平均值,总和,并计算其中有多少个值。我真的很难弄清楚如何创建100个项目的默认构造函数以及用户应该定义的数组大小。 > 创建新的数据集对象。创建对象的客户端指定可以添加到集中的最大项数。(编写一个具有一个 int 参数的构造函数。 还要编写一个默认构造函数,该构造函数创建一个能够处理100个项目的DataSet。 将整数数据项添加到数据
-
有没有办法根据条件从数据帧中提取数据?[副本]
我有一个数据框,比如说一些投资数据。我需要根据某些条件(比如说,U类型)从这个数据帧中提取数据。有许多可用的基金类型,我只需要提取与特定基金类型匹配的数据。 funding_type有风险、种子、天使、股权等价值。我只需要数据匹配资金类型比如种子和天使 我试着跟着 这里MF1是我的数据帧。这将提供与种子基金类型相关的所有数据 我需要的条件有点像 MF1[MF1['funding_round_typ
-
根据来自其他数据帧的多行替换数据帧中的值
我有3个数据帧。第一数据帧(例如df1)具有多行和多列。第二和第三数据帧(例如df2和df3)仅具有来自DF1的一行和列的子集。df2和df3中的列名相同。所以我要做的是将df1中的每一行与df2和DF3中的单行进行比较。如果来自df1的单元格的值与df2的单元格内容匹配,则将df1中单元格的值替换为1;如果来自df1的单元格的值与df3匹配,则将df1中单元格的值替换为2;如果df2的单元格内容
-
从JSON数组中提取数据
问题内容: 我知道它是一个数组,但是我对JSON完全陌生,需要帮助理解它的结构,这是我提取数据的尝试: 我拥有的JSON数据如下所示: 我对这些东西的掌握并不强,因此感谢所有帮助。 问题答案: 这是个主意: 它应该可以工作(如果有编译错误,请随时投诉)