《数据分析实习》专题
-
 联想-DT数字化转型-数据分析工程师-一二面面经(oc)
联想-DT数字化转型-数据分析工程师-一二面面经(oc)一面9.18 群面,而且和mkt、市场等背景的同学,海外高校居多,还有位清华本硕小姐姐惊呆我了。 选一个行业,讨论行业转型的痛点和方案及价值 (本以为过不了,不过从这次从其它岗位的同学上学到了很多群面的技巧,有时间再系统总结一下) 二面9.25 介绍实习 公司类型倾向 有没有数据质量的处理经历 base天津,一次非传统的面试经历?一般联想这个岗位好像也不会群面,后来oc发现是捞起来给了
-
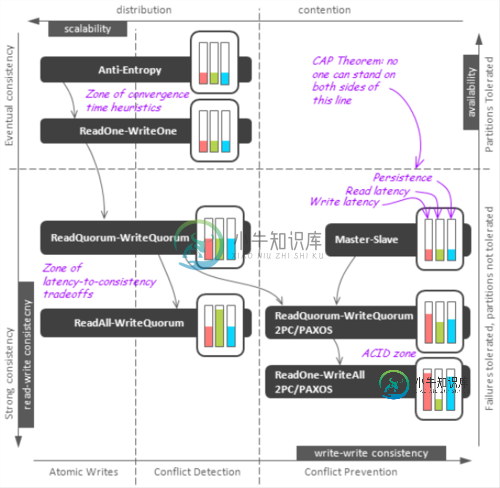 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
IC角色,用于创建物理表,分析SAP HANA中的数据
本文向大家介绍IC角色,用于创建物理表,分析SAP HANA中的数据,包括了IC角色,用于创建物理表,分析SAP HANA中的数据的使用技巧和注意事项,需要的朋友参考一下 要创建物理表,需要上传数据并创建信息视图IC_MODELER角色。如果仅为这些用户分配IC_PUBLIC角色,则他们可以查看其他用户创建的信息视图,但不能创建自己的视图。
-
将聚类分析结果转换为数据。R中的帧格式
这篇文章来自于这个主题,使用R对单词中的相同模式进行分类。解决方案很好,但是我需要数据帧格式。数据是相同的 我们来进行聚类分析 代码完成后,如何将结果转换为data.frame? 预期产出 s=as。数据(函数(…,row.names=NULL,check.rows=FALSE,check.names=TRUE)中的frame(拆分(文本,集群))错误:参数表示行数不同:7,1,2 所以理想的输出
-
用Java进化生物学库(JEBL)分析数据注释树节点
我使用JEBL和跌跌撞撞的API,因为我找不到非常清晰的留档或示例。 我想做的是在一棵树上阅读,树上的树枝标注了长度,节点也标注了长度。然后,我应该能够获取树叶并向上遍历树,同时检查节点的注释(使用JEBL遍历很容易,我的问题实际上是注释)。 它们是系统发育树,其中每个节点都是一个物种,注释将标记特定节点上是否存在某些基因,并且可能有足够少的基因,一个字符串就足够了(例如,如果有三个基因a、B和C
-
 上海银行-数据分析与应用工程师一面面经
上海银行-数据分析与应用工程师一面面经关于数分的面经好像很少,发一下积攒一下人品,面完的友友可以互通一下有无呀,许愿能有二面~ 时间点:9.21投递,9.29收到笔试,9.30笔试,晚上收到约10.5面试的邮件(上银前面好像比较快,会在一个星期左右发笔试,要是还没收到估计是凉了) 楼主是搞深度学习的,对数分可能不太熟悉,面前一直准备复习SQL,之前一直找的算法岗,一直没怎么问过数据结构,所以回答的不是很好,害 腾讯会议的形式,一共五个
-
 上海招商银行信用卡中心数据分析岗避雷
上海招商银行信用卡中心数据分析岗避雷职位名为数据分析 看到职位要求的:excel,python,Java,爬虫,数据分析等硬性技能,还有一些项目管理这些 当时没有把项目管理这些放在心上 后来证明这是一个大坑 我就去面试了 到了地方 先花几分钟写了一个简历,然后做了半个小时的性格测试 性格测试120道题,选项在手机上,题干是语音播报的,需要自己听 个人评价:纯属浪费时间 工作人员引我去了一个小会议室,面试官在开会,等了10分钟面试官
-
 蔚来数据分析工程师一面面经(惨遭挂版本
蔚来数据分析工程师一面面经(惨遭挂版本9月8号一面的,当时觉得表现的还行也挂了哈哈,有点失去斗志了,还是去提升提升自己多准备点赛道了~ 面了50多分钟,一位面试官,自动驾驶部分的 问题一:介绍一下研究生的一些专业课 问题二:针对一段实习的提问,详细介绍了做的东西之后,相关衍生了两三个小问题,我的实习是做的销量预测,面试官比较关注特征挖掘那部分,比如换成其他产品的销量预测怎么再去挖掘特征 问题三:针对另一段实习的提问,问了看板搭建那部分
-
 数据分析面试题|如何提升app的用户参与度
数据分析面试题|如何提升app的用户参与度******************* 春招保驾护航! 参考回答: - 第一步:定义指标。几乎所有的产品案例研究都从一个模糊的目标开始,第一步是将此目标转化为可以优化的指标。 比如。 "我将小红书上用户的参与度定义为每天至少采取一项行动的用户比例,其中行动意味着与网站互动,即发布、喜欢、上传图片等" 。 - 在指标确定之后,选择我们认为对该指标起到影响的变量特征。比如用户特
-
 中移在线营销服务江苏中心数据分析三面
中移在线营销服务江苏中心数据分析三面1、自我介绍;2、校内情况;3、项目经历;4、为什么选择数据分析岗。整体感觉像是在唠嗑,问的都很宽。
-
 北京锐安科技数据分析师一面面经(秋招1)
北京锐安科技数据分析师一面面经(秋招1)2024/8/10 面试官是一位很板正的小姐姐,说话问答都有一种公安的感觉。整体面试感觉不错,但是现在还没回信。 1.自我介绍 2.项目拷打 3.了解数据治理吗? 4.数据挖掘支持决策的流程 5常见的分类模型有哪些? 6.F1-score的公式是什么 7.期望的薪资大概是多少? 8.最早什么时间可以入职? 9.出差三个月才可以申请回来,可以接受吗 反问:主要项目流程是什么呢?
-
 京东数据分析面试3|秋招两面社交电商部
京东数据分析面试3|秋招两面社交电商部京东社交电商APP+小程序京喜,对标拼多多。 一面 1. 自我介绍+项目与实习提问。 2. 你学的这个专业,你认为对你影响最大的是什么? 3. 最大的成长或收获是什么呢?为什么?举个最近实际的例子? 4. 详细问是例子中是怎么想、怎么做、怎么实现的? 5. 运用数据分析,分析一下酒店的漏水情况?(和面试官一来一往提出假设,具化问题,分析讨论) 6. 你SQL怎么样? 7. 你有什么问题? 二面 1
-
Grails:在运行时更改数据源url以实现多租户数据库分离
我正在用Grails构建一个多租户应用程序,我想保持独立的数据库。我需要在运行时动态更改url以将GORM指向不同的数据库。 我有一个前端充当平衡器,将请求分发到后端主机集群。每个后端主机运行一个Grails 2.3.5实例和一个带有多个数据库的mysql服务器(每个租户一个)。我希望动态更改数据源,以便GORM可以访问正确数据库上的域实体。 有什么想法吗? 谢啦
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
1.5.3.2.13.3 选址分区分析
选址分区分析是为了确定一个或多个待建设施的最佳或最优位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅是一个选址过程,还要将需求点的需求分配到相应的新建设施的服务区中,因此称之为选址与分区。 设置选址分区分析参数,包括交通网络分析通用参数、途径站点等。 //设置设施点的资源供给中心 var supplyCenterType_FIXEDCENTER = SuperMap