《欢聚时代》专题
-
如何在Calcite中将项目,过滤,聚合下推到TableScan
问题内容: 我正在使用Apache Calcite来实现分布式OLAP系统,该数据源是RDBMS。所以我想将树中的项目/过滤器/聚合推到。在,得到推。最后,生成对源数据库的查询。同时,应移动或修改原始树中的项目/过滤器/集合。 据我所知,方解石不支持此功能。 当前的局限性:JDBC适配器当前仅下推表扫描操作。所有其他处理(过滤,联接,聚合等)都在方解石内部进行。我们的目标是尽可能减少对源系统的处理
-
在多模块项目中聚合checkstyle报表的Gradle任务
我的目标是生成一个包含来自这两个模块的信息的聚合checkstyle报告。当我运行“Gradle CheckStyleMain”时,聚合的html报告只包含来自module2的checkstyle报告信息,而忽略module1信息。
-
具有自定义对象数据类型的Kafka Stream聚合
我有一个处理器,它从主题中获取json字符串,类型为GenericRecord。现在我把这条河分成两条支流。我采用第一个分支,并将(key,value)映射为2个字符串,其中包含一个特定的json字段和该字段的值,然后按key分组。到目前为止,一切都很好。现在,我必须用用户定义的新类型聚合流,并收到一个异常。 这里是代码: 新类型: 好流: 问题是: 这是例外: 我如何解决这个问题? 更新 ---
-
Cassandra有多个具有相同派生和聚类键的行
有一个由5个节点组成的Cassandra集群。最近进行了从2.2.7到3.9版本的逐节点更新。更新是按照Datastax描述的过程进行的:升级指令。一切都很顺利。整个过程耗时约1小时。然而,几个小时后,我发现了以下问题:在更新期间,有些数据不一致,即对于特定的分区键和聚类键,只返回一行。但是对于同一个查询,有时返回一个,有时返回两个。 结果示例: 因此,正如您所看到的,第一行有字段:field3和
-
如何用maven将lombok和JPAMetalModel处理器凝聚在一起
如何在maven构建中激活JPAMetaModelEntity处理器注释处理器时使用Lombok。 Maven配置: 在构建过程(mvn clean install)中,元模型对象被正确地生成,但似乎Lombok注释处理器不再添加到Javac编译中。所有@Getter,@Setter,。。。不起作用。
-
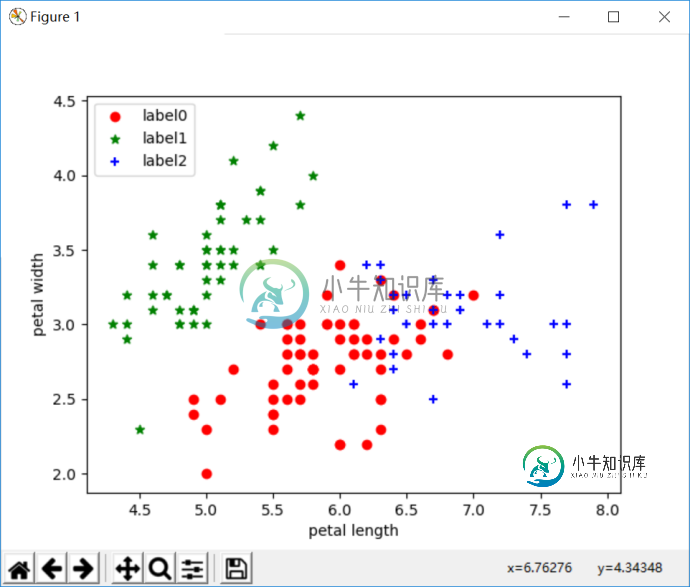 python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)本文向大家介绍python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan),包括了python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)的使用技巧和注意事项,需要的朋友参考一下 一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。 3.对每个点确定其聚类中心点。 4.再计算其聚类
-
SQL查询聚合可能不会出现在WHERE子句中
问题内容: 我有此SQL语句,并且SQL Server给我以下错误: 除非聚合不在HAVING子句或选择列表中包含的子查询中,否则它可能不会出现在WHERE子句中。 在where子句中,我只想提取最旧的未付款帐单日期大于DelinquentDaysThreshhold(以天为单位)或PastDueAmount(计算值)大于DelinquentAmountThreshold的记录。 由于某些原因,S
-
如何在同一条语句中使用填充和聚合?
问题内容: 这是我的约会集合: 我用聚合得到以下结果 像这样: 我该如何填充我做到这一点但没有用的患者文档……。 换句话说,我可以在同一条语句中使用填充和聚合吗 任何帮助请 问题答案: 使用最新版本的猫鼬(mongoose> = 3.6), 可以 但需要第二次查询,并且使用不同的填充方式。汇总后,请执行以下操作: 有关更多信息,请访问Mongoose API 和Mongoose文档。
-
不能将$ match与猫鼬和聚合框架一起使用
问题内容: 这是我的架构: 这是代码: 在包含了用户的。 该代码有效,除非添加了。我使用来过滤结果,仅获取我关注的用户的图片,但是console.log向我显示搜索结果是不确定的,但是当我不编写查询时,就会得到图片,但我会获取所有图片,而不仅是我关注的用户的图片。 有什么解决方案吗…? 谢谢前进! 编辑: 编辑: 问题答案: Mongoose不会对的参数进行任何基于模式的转换,因此您需要将字符串I
-
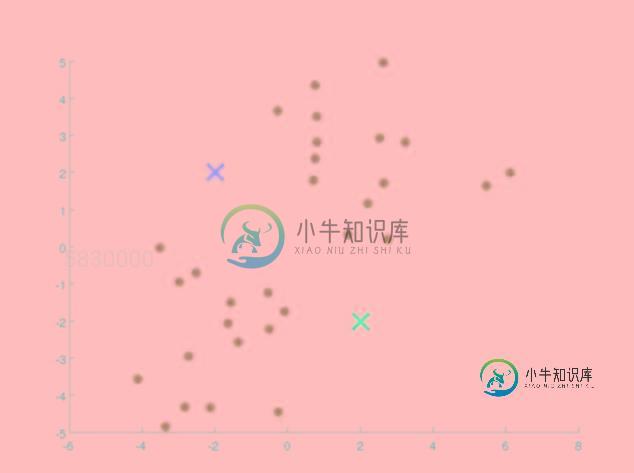 Kmeans均值聚类算法原理以及Python如何实现
Kmeans均值聚类算法原理以及Python如何实现本文向大家介绍Kmeans均值聚类算法原理以及Python如何实现,包括了Kmeans均值聚类算法原理以及Python如何实现的使用技巧和注意事项,需要的朋友参考一下 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两
-
PostgreSQL聚合或窗口函数仅返回最后一个值
问题内容: 我在PostgreSQL 9.1中使用带有OVER子句的聚合函数,并且只想返回每个窗口的最后一行。该窗口的功能听起来像它可能做我想做的- 但事实并非如此。它为窗口中的每一行返回一行,而我希望每个窗口仅一行 一个简化的例子: 我希望它返回一行: 问题答案: [](http://www.postgresql.org/docs/current/interactive/sql- select.
-
如何在熊猫数据框架中聚合数据?[副本]
我用熊猫数据框来处理数据。现在我需要聚合数据,并想知道如何聚合数据。 我有: 我想用打印创建:
-
ElasticSearch-带有数组字段的子术语聚合的问题
问题内容: 我有以下两个文件: 和: 我想基于两个字段执行聚合:casting.name和casting.category。 我尝试使用基于Cast.name字段的termsaggregation和子聚合,这是另一个基于casting.category字段的termsaggregation。 问题在于,对于“ Chris Evans”条目,ElasticSearch为所有类别(演员,生产者)设置了
-
MongoDB聚合/数学运算求和特定学生的分数
本文向大家介绍MongoDB聚合/数学运算求和特定学生的分数,包括了MongoDB聚合/数学运算求和特定学生的分数的使用技巧和注意事项,需要的朋友参考一下 总计,请与$sum一起使用。让我们创建一个包含文档的集合- 在方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是特定学生的汤姆总和查询分数- 这将产生以下输出-
-
谷歌工作表筛选聚合表后梳理几个表
我正在尝试在google sheets中组合几个工作表,然后在生成的组合工作表上应用过滤器。 我有名为、等的工作表。我想将它们组合成一个名为的工作表,然后根据几个条件筛选工作表中的特定列。 我试过这个,但不起作用: =筛选器({filter({jan!A1:E500};{feb!A1:E500}},{{jan!A1:A500};{feb!A1:A500}} 第一个过滤器正常工作,但第二个过滤器出现