《欢聚时代》专题
-
与“旧”AdMob SDK相比,我们应该更喜欢谷歌Play服务中的AdMob吗
我刚意识到谷歌将AdMob嵌入最新的Google Play服务(4+) 我这么问的原因是,我发现谷歌Play服务的AdMob仍然很有问题。 这是我的观察。 从Java代码创建一个智能横幅,并将其放在滚动视图的中间。 每当智能横幅从Google服务器成功获取广告时,滚动视图将自动滚动以使智能横幅可见。 演示该bug的完整源代码可以在这里找到:来自Google Play服务的AdMob将执行不希望的自
-
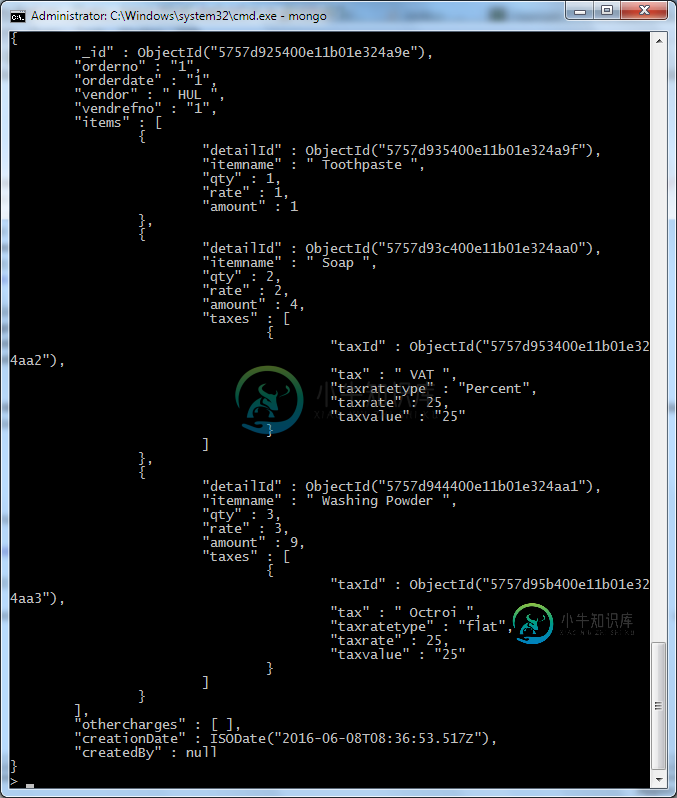 当尝试使用聚合查找和更新时,得到错误“管道元素3不是一个对象错误”
当尝试使用聚合查找和更新时,得到错误“管道元素3不是一个对象错误”我正在使用&试图更新文档中对象数组中的。 文档集合的架构如下: 我想要的是: 目前,我正在使用db.eval从node运行这个脚本,但是一旦我完成了同样的任务,稍后将对其进行更改。 获取此错误: {“name”:“mongoerror”,“message”:“error:command failed:{\n\t\”ok“:0,\n\t\”errmsg\“:\”管道元素3不是对象\“,\n\t\”c
-
聚合功能在Spark中使用groupBy计数使用情况
问题内容: 我试图在pySpark的一行代码中进行多项操作,但不确定我的情况是否可行。 我的意图是不必将输出另存为新的数据框。 我当前的代码非常简单: 我的意图是在使用后添加,以得到与每个 列值匹配的记录计数,这些记录打印\显示为输出。 尝试使用时,出现异常。 有什么方法可以同时实现和 .show()打印,而无需将代码拆分为两行命令,例如: 或更好的办法是将合并的输出输出到-额外的一栏,用于说明与
-
mongo的组聚合后是否可以重命名_id字段?
问题内容: 我有这样的查询(简体): 我从Java执行此查询,我想将其映射到我的课程上,但是我不希望将’_id’映射到’name’字段上。因为如果我做这样的事情: 然后,当我将数据保存回mongo(经过一些修改)后,我希望生成一个真实的ID时,数据将以名称’_id’保存。 那么,如何在$ group操作之后重命名“ _id”? 问题答案: 您可以通过 在管道的末尾添加一个阶段来实现此目的,如下所示
-
使用Java在Selenium WebDriver中聚焦元素的正确方法
问题内容: WebDriver 的等效功能是什么? 要么 我已经尝试了这两种方法,并且它们都起作用,但是哪一个将始终对所有元素起作用? 对于任何元素(例如按钮,链接等),哪种方法是正确的?这对我很重要,因为该功能将在不同的UI上使用。 问题答案: 以下代码- 尝试查找输入标签框以输入一些信息,而 更适用,因为它适用于图像元素,链接元素,下拉框等。 因此,使用 moveToElement() 方法将
-
从Python Pandas聚合结果格式化/抑制科学符号
问题内容: 如何对熊猫的groupby运算的输出进行格式修改,从而产生非常大的科学计数法? 我知道如何在python中进行字符串格式化,但是在这里应用它时我很茫然。 如果我转换为字符串,这会抑制科学计数法,但是现在我只是想知道如何设置字符串格式并添加小数。 问题答案: 当然,我在评论中链接的答案不是很有帮助。你可以像这样指定自己的字符串转换器。 我不确定这是否是首选的方法,但是可以。 仅出于美学目
-
带有嵌套聚合的Elasticsearch查询导致内存不足
问题内容: 我安装了16gb内存的Elasticsearch。我开始使用聚合,但是在尝试发出以下查询时遇到“ java.lang.OutOfMemoryError:Java堆空间”错误: query_string本身仅返回1266次匹配,因此OOM错误让我有些困惑。 我是否正确使用了聚合?如果没有,我该怎么做才能解决此问题?谢谢! 问题答案: 您正在将整个-,-和- 字段加载到内存中以进行汇总。这
-
NoSQL数据库如何对聚合函数(AVG,SUM等)执行
问题内容: 我们需要定期处理相当大的数据集(30-40GB)。它有很多按时间排序的值(以及更多信息),但我们基本上需要按月执行一些数学运算。 我们的第一种方法是使用MySQL数据库来备份数据,因为我们对引擎和关系方法有一定的经验。但是,该过程耗时太长,我们想知道NoSQL方法是否可以做得更好。 基本上,我们需要表达的数据是: 我们处理此列表三次,执行简单的数学运算,当我说“处理”时,我的意思是遍历
-
如何在Calcite中将项目,过滤,聚合下推到TableScan
问题内容: 我正在使用Apache Calcite来实现分布式OLAP系统,该数据源是RDBMS。所以我想将树中的项目/过滤器/聚合推到。在,得到推。最后,生成对源数据库的查询。同时,应移动或修改原始树中的项目/过滤器/集合。 据我所知,方解石不支持此功能。 当前的局限性:JDBC适配器当前仅下推表扫描操作。所有其他处理(过滤,联接,聚合等)都在方解石内部进行。我们的目标是尽可能减少对源系统的处理
-
在多模块项目中聚合checkstyle报表的Gradle任务
我的目标是生成一个包含来自这两个模块的信息的聚合checkstyle报告。当我运行“Gradle CheckStyleMain”时,聚合的html报告只包含来自module2的checkstyle报告信息,而忽略module1信息。
-
具有自定义对象数据类型的Kafka Stream聚合
我有一个处理器,它从主题中获取json字符串,类型为GenericRecord。现在我把这条河分成两条支流。我采用第一个分支,并将(key,value)映射为2个字符串,其中包含一个特定的json字段和该字段的值,然后按key分组。到目前为止,一切都很好。现在,我必须用用户定义的新类型聚合流,并收到一个异常。 这里是代码: 新类型: 好流: 问题是: 这是例外: 我如何解决这个问题? 更新 ---
-
Cassandra有多个具有相同派生和聚类键的行
有一个由5个节点组成的Cassandra集群。最近进行了从2.2.7到3.9版本的逐节点更新。更新是按照Datastax描述的过程进行的:升级指令。一切都很顺利。整个过程耗时约1小时。然而,几个小时后,我发现了以下问题:在更新期间,有些数据不一致,即对于特定的分区键和聚类键,只返回一行。但是对于同一个查询,有时返回一个,有时返回两个。 结果示例: 因此,正如您所看到的,第一行有字段:field3和
-
如何用maven将lombok和JPAMetalModel处理器凝聚在一起
如何在maven构建中激活JPAMetaModelEntity处理器注释处理器时使用Lombok。 Maven配置: 在构建过程(mvn clean install)中,元模型对象被正确地生成,但似乎Lombok注释处理器不再添加到Javac编译中。所有@Getter,@Setter,。。。不起作用。
-
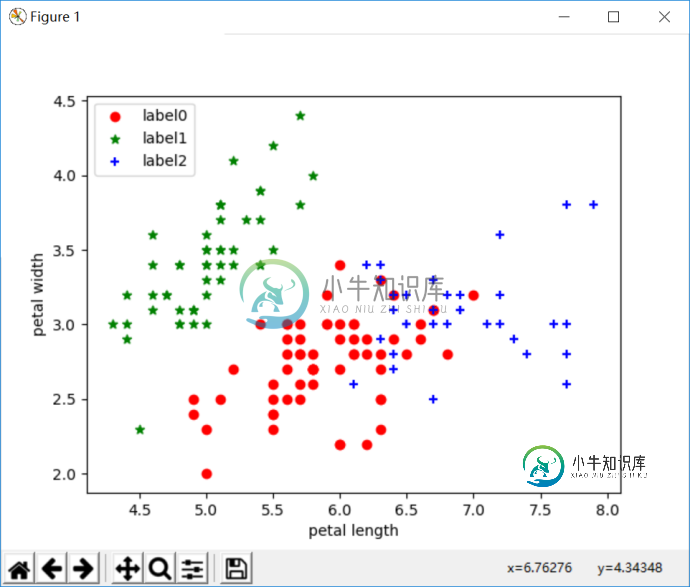 python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)本文向大家介绍python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan),包括了python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)的使用技巧和注意事项,需要的朋友参考一下 一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。 3.对每个点确定其聚类中心点。 4.再计算其聚类
-
SQL查询聚合可能不会出现在WHERE子句中
问题内容: 我有此SQL语句,并且SQL Server给我以下错误: 除非聚合不在HAVING子句或选择列表中包含的子查询中,否则它可能不会出现在WHERE子句中。 在where子句中,我只想提取最旧的未付款帐单日期大于DelinquentDaysThreshhold(以天为单位)或PastDueAmount(计算值)大于DelinquentAmountThreshold的记录。 由于某些原因,S