《欢聚时代》专题
-
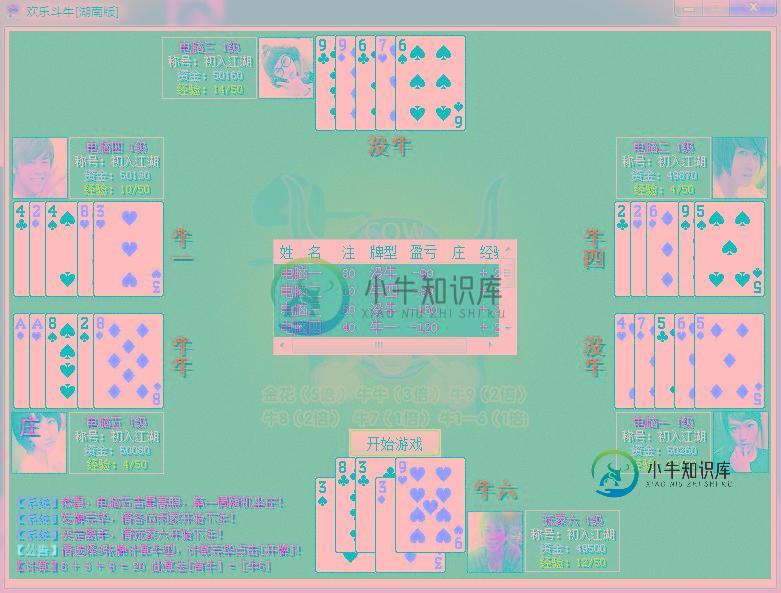 易语言制作欢乐斗牛单机版游戏源码
易语言制作欢乐斗牛单机版游戏源码本文向大家介绍易语言制作欢乐斗牛单机版游戏源码,包括了易语言制作欢乐斗牛单机版游戏源码的使用技巧和注意事项,需要的朋友参考一下 DLL命令表 自定义数据类型表 欢乐斗牛单机版 运行结果: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相关链接
-
 一看就喜欢的loading动画效果Android分析实现
一看就喜欢的loading动画效果Android分析实现本文向大家介绍一看就喜欢的loading动画效果Android分析实现,包括了一看就喜欢的loading动画效果Android分析实现的使用技巧和注意事项,需要的朋友参考一下 还是比较有新意,复杂度也不是非常高,所以就花时间整理一下,我们先一起看下原gif图效果: 从效果上看,我们需要考虑以下几个问题: 1.叶子的随机产生; 2.叶子随着一条正余弦曲线移动; 3.叶子在移动的时候旋转,旋转方向随机
-
Microsoft Bot中的相同线程正在复制欢迎消息
我已将欢迎消息配置为在第一次启动bot时出现在MessagesController中。 当我调试时,似乎在开始时,两个线程正在运行bot,并且都在Post方法中执行,因此都在调用HandleSystemMessage。这对我来说是一个问题,因为有两个线程执行该方法,我的欢迎消息将在屏幕上打印两次。 我试图锁定打印msg并将其中一个线程Hibernate,但没有一个工作。我不知道为什么有两个线程开始
-
例子:在欢迎界面添加安装方式的选择
引用脚本的内容: SetCompressor /SOLID lzma SetCompressorDictSize 32 XPStyle on Name "Welcome_setuptype" OutFile "Welcome_setuptype.exe" !include "MUI.nsh" !include "LogicLib.nsh" !include "WinMessages.nsh" I
-
 尊嘟假嘟?原来hr喜欢这样的自我介绍!!!
尊嘟假嘟?原来hr喜欢这样的自我介绍!!!一、无实习经验,以校园经历为主 尊敬的面试官,您好!很荣幸可以参加贵公司的本次面试。请允许我先做一段自我介绍。 (个人基础信息) 我叫鲲鲲,毕业于XX大学XX专业。尽管我的所学专业与投递岗位关联度不高,也没有丰富的运营相关经验,但我了解,虽然行业不同但基础的逻辑思维和底层能力是相似的。 (个人经验举例1) 例如工作经验,我个人觉得工作能力的表现主要体现在思维方式、发现问题与解决问题的能力以及自主学
-
 安得广厦千万间,大庇天下寒士俱欢颜
安得广厦千万间,大庇天下寒士俱欢颜今天百度后端二面排序挂,没hc了,这周目前没有任何一个面试了,boss上沟通了一堆测开也没人鸟,就这样吧,爱咋地咋地吧,宿命如此,人何以违?安得hc千万个,大批天下寒士俱欢颜
-
在页面加载时开始输入时,在输入字段中添加字符,而不对输入进行聚焦
这是我的代码 null null 在页面加载时,如果用户开始键入,焦点将聚焦输入,但不允许用户输入键入的字符。到目前为止,焦点是工作的,但当用户连续键入时,它并不像预期的那样工作。请帮帮我。任何帮助都将不胜感激。
-
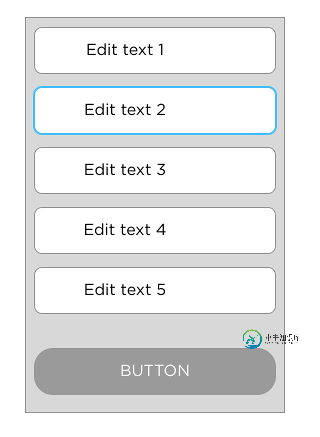 Android:聚焦时,如何将滚动视图中的EditText置于另一个视图之上?
Android:聚焦时,如何将滚动视图中的EditText置于另一个视图之上?我的应用程序设计使我对每个表单视图都有这样的布局:视图底部有一个浮动按钮。我使用来动态设置按钮的高度,无论屏幕宽度如何,总是相同的左/右边距,所以我最终有这样的布局: (1)底部按钮高度的清晰视图,以免隐藏按钮隐藏的滚动视图底部视图 基本上,这就是它看起来的样子: 现在我遇到的问题是当我点击底部的编辑文本时,例如,这里的第四个: 编辑文本会在键盘上向上移动,但不会在浮动按钮上移动,并且经常被它隐藏
-
在Spring Cloud Stream上使用自定义serde序列化聚合状态存储时出错
我正在尝试用Spring Cloud Stream创建一个简单的函数bean,它处理来自KStream和GlobalKTable的消息,将它们连接起来,聚合它们,并将结果输出到一个新的流,但我在正确配置它所需的SERDE方面遇到了困难。 不用多说,以下是我的方法: 这是我的属性文件中的配置: 当我运行上面的代码时,我得到以下错误: 这个班的学生是com。包裹模型MyCustomJavaClass与
-
在数据帧分组用户中聚合时,无法执行用户定义的函数
我有一个数据帧如下,我试图得到最大(总和)的用户组名称。 下面是我用来为用户获取最大值(总和)的自定义项 当我运行udf时,它抛出了下面的错误 错误:无法执行用户定义的函数($anonfun$1:(数组)= 因为我需要在更大的数据集中实现这一点,所以如何以更好的方式实现这一点 预期的结果是
-
按enter键时,聚焦下一个cellEditor并在JTable中选择其中的所有文本
我希望enter键的作用类似于JTable上的tab键。我知道这个问题已经问过几次了,我使用了本页中找到的解决方案:使用Enter键就像JTable上的Tab键一样。 因此,当我按下tab键时,下一个单元格被聚焦,其中的文本被选中,但当我键入enter键时,第一次单元格松开焦点,第二次enter键时,下一个单元格获得焦点,其中的文本被选中。 所以我的问题是:有没有一种方法可以让第一个从单元格中输入
-
Android Material Components主题-聚焦字段时更改TextInputLayout/TextInputItemText标签和下划线的颜色
我试图切换到新的材质组件主题,有一件事我似乎不能改变,那就是标签和下划线的颜色。 当我使用AppCompat主题时,它使用了colorAccent,但是新的MaterialComponents主题使用了colorPrimary。 如何覆盖MaterialComponents主题以仅在该场景中使用色彩口音? 我尝试过的事情: 扩展小部件。MaterialComponents样式为TextInputL
-
 文本输入布局下划线颜色不适应聚焦时的自定义颜色
文本输入布局下划线颜色不适应聚焦时的自定义颜色不确定我遗漏了什么,但每次聚焦时,下划线颜色都不适合我设置的自定义颜色。这里是我的主题代码供参考 如您所见,我已将它们全部设置为白色,但不知何故,当聚焦时,下划线变为绿色 这是我的代码从布局
-
K均值聚类算法的Java版实现代码示例
本文向大家介绍K均值聚类算法的Java版实现代码示例,包括了K均值聚类算法的Java版实现代码示例的使用技巧和注意事项,需要的朋友参考一下 1.简介 K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重
-
通过代码在Cosmos DB中启用Mongo DB聚合管道
Azure Cosmos DB现在也支持聚合管道,这真的很好,这使它成为我们使用的一个可行替代品,而不是运行我们自己的Mongo DB容器,但我没有找到通过代码启用这些功能的方法(如何在门户中进行描述:https://azure.microsoft.com/en-gb/blog/azure-cosmosdb-extends-support-for-mongodb-aggregation-pipel