《欢聚时代》专题
-
WordPress 启用最受欢迎的社交网络
本文向大家介绍WordPress 启用最受欢迎的社交网络,包括了WordPress 启用最受欢迎的社交网络的使用技巧和注意事项,需要的朋友参考一下 示例 您将在仪表板中获得以下文件: 这就是您在代码中检索它的方式
-
为什么JVM的GC喜欢不变对象?
-
所选示例 - 我们最喜欢的秘籍
原文:Our Favorite Recipes 这里是一个简短的教程,示例和代码片段的集合,展示了一些有用的经验和技巧,来制作更精美的图像,并克服一些 matplotlib 的缺陷。 共享轴限制和视图 通常用于使两个或更多绘图共享一个轴,例如,两个子绘图具有时间作为公共轴。 当你平移和缩放一个绘图,你想让另一个绘图一起移动。 为了方便这一点,matplotlib 轴支持sharex和sharey属
-
欢迎来到云联壹云文档中心
安装部署 介绍云联壹云产品的安装部署,云联壹云采用容器化部署方式部署在Kubernetes集群上。 点击查看 管理手册 介绍产品部署流程,帮助管理员快速搭建环境。 点击查看 快速上手 介绍如何快速搭建多云环境,管理多云资源。 点击查看 用户手册 介绍云联壹云平台上功能的使用指导和注意事项等。点击查看 常见问题 介绍云联壹云产品常见问题及解答。点击查看 开发手册 介绍平台API的使用方法。 点击查
-
 上海欢乐互娱游戏测开一面
上海欢乐互娱游戏测开一面有段时间没更新了因为到了期末周准备了一下考试,然后又回到家玩了两三天 最近没啥面试了可能到年底的原因?也没再投了,随缘吧要是没有实习的话寒假就继续学习等春招吧 自我介绍 面试官看我简历像是开发的然后很热心的为我介绍了一下测试的分类和工作日常 问项目 渲染管线 手撕代码 给你你一个日期比如2001.02.15将他输出成二零零一年二月二十五日 问职业规划 反问 我问了问进公司有没有可能内部转岗的问题
-
第9章 案例分析:图像聚类 - 9.1 图像聚类简介
图像分类源于机器视觉,其根据图像可见内容对图像进行分类。例如,某个图像算法可能会用来告诉你该图片中是否有人。虽然检测人可能是很简单的事情,但能将图像进行准确分类的算法,仍然是目前的所要面临的挑战。 BoW模型通常会用于文本分类或自然语言处理。BoW模型中每个词出现的频度都会作为一个训练参数传入对应的机器学习算法中。除了进行文本分类,BoW也可以应用于图像。为了让BoW能对图像进行分类,我们需要从图
-
有哪些不算特别流行的产品是你特别喜欢的吗?说说你喜欢的原因。
本文向大家介绍有哪些不算特别流行的产品是你特别喜欢的吗?说说你喜欢的原因。相关面试题,主要包含被问及有哪些不算特别流行的产品是你特别喜欢的吗?说说你喜欢的原因。时的应答技巧和注意事项,需要的朋友参考一下 ChangePro 优点: 1、专业化的内容分类,每周更新的主题视频集合 内容浏览路线清晰,用户查找相关视频路径短、匹配度高 2、基于热度的视频的排行榜 针对热门视频,提供周排行、月排行和总排行,
-
jQuery Dialog 打开时自动聚焦的解决方法(两种方法)
本文向大家介绍jQuery Dialog 打开时自动聚焦的解决方法(两种方法),包括了jQuery Dialog 打开时自动聚焦的解决方法(两种方法)的使用技巧和注意事项,需要的朋友参考一下 下面给大家介绍两种方法解决jQuery Dialog 打开时自动聚焦问题。具体实现方法大家可以参考下本文。 方法一: 方法二: 在要焦点的的控件加上 autofocus 如:第一个控件为 datepicker
-
为组织O365帐户授权Microsoft“聚合”OAuth时出现错误AADSTS90093
我正在开发一个在apps.dev.Microsoft上注册的应用程序。com使用新的“聚合”OAuth2流https://azure.microsoft.com/en-us/documentation/articles/active-directory-v2-protocols-oauth-code/. 我正在请求范围<code>用户的授权。请阅读</code>。具体来说,这是授权URL: 我希望
-
如何发送时间窗口KTable的最终kafka-streams聚合结果?
我想做的是: < li >消费数字主题中的记录(Long的) < li >聚合(计数)每个5秒窗口的值 < li >将最终聚合结果发送到另一个主题 我的代码如下: 看起来一切都像预期的那样工作,但聚合被发送到每个传入记录的目标主题。我的问题是如何仅发送每个窗口的最终聚合结果?
-
使用脚本转换Elasticsearch聚合以转换要聚合的字段值
问题内容: 我目前有类似的东西: 但是,myfield的值为“ alpha 1.0”,“ alpha 2.0”,“ beta 1.0”。现在,我只想聚合值“ alpha”,“ beta”。我怎么做?我试过了: 但我想这里没有拆分功能。欢迎任何建议! 问题答案: 我设法通过粘贴在问题中的链接来完成此任务:
-
SQL Server中的聚集索引和非聚集索引之间的区别
本文向大家介绍SQL Server中的聚集索引和非聚集索引之间的区别,包括了SQL Server中的聚集索引和非聚集索引之间的区别的使用技巧和注意事项,需要的朋友参考一下 索引是与实际表或视图相关联的查找表,数据库使用该查找表来改善数据检索性能的计时。在index中, 键存储在结构(B树)中,该结构使SQL Server可以快速有效地查找与键值关联的一行或多行。如果在表上定义了主键和唯一约束,则会
-
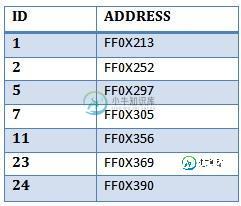 为什么非聚簇索引扫描比聚簇索引扫描更快?
为什么非聚簇索引扫描比聚簇索引扫描更快?问题内容: 据我所知,堆表是没有聚簇索引并且没有物理顺序的表。我有一个具有12万行的堆表“扫描”,并且正在使用以下选择: 如果为“ id”列创建非聚集索引,则将获得 223次物理读取 。如果删除非聚集索引并更改表以使“ id”成为主键(以及聚集索引),则将获得 515次物理读取 。 如果聚集索引表如下图所示: 为什么聚簇索引扫描的工作方式类似于表扫描?(或者在检索所有行的情况下更糟)。为什么不使用
-
Elasticsearch聚合:如何使用术语聚合的“其他”结果获取bucket?
我使用聚合从嵌套字段收集数据并卡住了一点 文件示例: ES允许通过rectangle.attributes._id来分组数据,但是有没有办法让一些“其他”桶把没有添加到任何组中的文档放在那里?或者,也许有一种方法可以通过创建查询来为文档创建桶。我认为桶将是完美的,因为我需要使用“其他”文档进行进一步的聚合。或者也许有一些很酷的解决方法 我使用这样的查询进行聚合 然后得到这个结果 这样的结果将是完美
-
弹性搜索:深度嵌套聚合下的reverse_nested聚合不起作用
Elasticsearch版本:2.3.3 基本上,标题说明了一切。如果二个嵌套聚合下使用reverse_nested,尽管文档似乎通过限定范围(请参阅结果中的最后一个字段),但其后面的聚合不会以某种方式工作。 这里我准备了一个例子——一个文档是一个学生的注册日期和考试历史。 映射: 试验文件: 聚合查询(无实际意义): 结果是: ...您可以在其中看到聚合“newest_exam_date”不起