
为什么非聚簇索引扫描比聚簇索引扫描更快?

据我所知,堆表是没有聚簇索引并且没有物理顺序的表。我有一个具有12万行的堆表“扫描”,并且正在使用以下选择:
SELECT id FROM scan
如果为“ id”列创建非聚集索引,则将获得 223次物理读取 。如果删除非聚集索引并更改表以使“ id”成为主键(以及聚集索引),则将获得
515次物理读取 。
如果聚集索引表如下图所示:
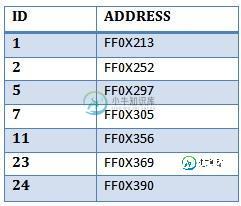
为什么聚簇索引扫描的工作方式类似于表扫描?(或者在检索所有行的情况下更糟)。为什么不使用块较少且已经具有所需ID的“聚集索引表”?
问题答案:
-
本文向大家介绍详解MySQL 聚簇索引与非聚簇索引,包括了详解MySQL 聚簇索引与非聚簇索引的使用技巧和注意事项,需要的朋友参考一下 1、聚集索引 表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。 从物理文件也可以看出 InnoD
-
主要内容:一、索引的种类及常用术语,二、聚簇索引,三、InnoDB索引的数据结构,四、源码,五、总结一、索引的种类及常用术语 索引种类有很多种,象前面提到的聚集索引和非聚集索引(聚集和聚簇等同),还有多个条目生成的联合索引,非聚集索引又可以叫做二级索引,辅助索引(其它还有什么普通索引,唯一索引,全文索引都可以通过看具体的上下文场景来明白怎么回事),还有一些数据库默认在主键上建立主键索引,一般来说,一个数据库只有一个聚集索引,一个主键索引。 本篇主要分析取簇索引,一般来说,索引的深度不会超过4层,
-
问题内容: 我有以下查询 当我运行它并检查实际的执行计划时,我可以看到最昂贵的运算符是聚集索引扫描(索引位于a.pred上) 但是,如果我按以下方式更改查询 消除了索引扫描,并使用了索引查找。 有人可以解释为什么吗?在我看来,这与以下事实有关:变量中的值可以是任何值,因此SQL不知道如何计划执行。 有什么办法可以消除表扫描但仍然可以使用变量?(PS,它将转换为以@StartDate和@EndDat
-
主要内容:SciPy中实现K-Means,用三个集群计算K均值K均值聚类是一种在一组未标记数据中查找聚类和聚类中心的方法。 直觉上,我们可以将一个群集(簇聚)看作 - 包含一组数据点,其点间距离与群集外点的距离相比较小。 给定一个K中心的初始集合,K均值算法重复以下两个步骤 - 对于每个中心,比其他中心更接近它的训练点的子集(其聚类)被识别出来。 计算每个聚类中数据点的每个要素的平均值,并且此平均向量将成为该聚类的新中心。 重复这两个步骤,直到中心不再移动或
-
问题内容: 我知道索引在内部是B树或类似的树结构。假设索引是为3列构建的,我希望Postgres执行以下操作: 在该B树中找到键[a = 10,b = 20,c = 30], 扫描下10个条目并返回它们。 如果索引只有一列,则解决方案显而易见: 但是,如果有更多的列,解决方案将变得更加复杂。对于2列: 3栏: 请注意查询: 是 不正确的 ,因为它将例如过滤掉[a = 11,b = 10,c = 1
-
本文向大家介绍sql 聚集索引和非聚集索引(详细整理),包括了sql 聚集索引和非聚集索引(详细整理)的使用技巧和注意事项,需要的朋友参考一下 聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索