《商业分析》专题
-
将按客户IP地址的搜索添加到商业订单搜索
我一直试图找到解决办法,但没能找到。 Woocommerce在创建订单时保存客户IP地址。 但是,无法通过IP地址搜索订单。 如何将此功能添加到商业订单搜索?
-
为商业筛选器添加\u重写\u规则\u不起作用
我正在尝试获取具有某些类别和属性的产品列表。Dirrect链接工作正常,但自定义规则无法按预期工作。是的,我在管理面板中重新加载永久链接。请帮我找到解决办法。吴哥商业产品清单。 如果我打开index.php?product_cat=oil
-
如何以程序化的方式获得商业中的所有产品?
我想获取WooCommerce中的所有产品数据(产品sku、名称、价格、库存、可用性等),我可以使用wp查询吗?
-
 字节跳动大数据研发实习生-商业化技术凉经
字节跳动大数据研发实习生-商业化技术凉经1. 自我介绍,项目介绍 2. 自我介绍的时候问我这些东西是自己学的还是学校讲的。 内心:在说什么。。。 3. 因为简历上第一个写的是使用爬虫进行数据挖掘,但是没用flume进行数据采集,所以就简单的说一下当时是把数据采集成csv或者data格式的文件,直接上传到的Hdfs,直接使用load path加载到hive当中。 并且当时介绍了数据集的大小,以及介绍了可能会产生的问题, 4. 面试
-
 字节跳动 商业化技术 大数据开发实习生 面经
字节跳动 商业化技术 大数据开发实习生 面经### 一面技术面 自我介绍 四道算法 前两题是sql,其中一个难点的就是求连续登录2天以上的用户 一道快排 一道求二叉树是否是对称二叉树,就是左右节点是对称的 问实习经历(问的很细) 工作中的难点 维度建模过程 聊到数据仓库工具箱这本书的内容,我都不会。。。 数据倾斜(我从原理,场景,解决方案三个角度回答的) 问到一些常用函数,UDF,UDAF,UDTF概念 hive的概述 hadoop,hiv
-
 2023暑期实习-大数据开发面试-字节商业化-HR面
2023暑期实习-大数据开发面试-字节商业化-HR面1、 面试官直接自我介绍,说HR面,开始问我问题。 2、 看专业是大数据相关的,你这是定向保研吗? 3、 你为什么选择大数据开发这个岗位? 4、 平常你怎么学习这些技术的? 5、 新技术看文档、博客、源码这些? 6、 经过两轮技术面,你对自己的评价? 7、 什么时候能来实习? #找实习多的是你不知道的事#
-
 字节跳动一面:后端开发商业技术与产品岗位
字节跳动一面:后端开发商业技术与产品岗位一篇字节跳动一面面经,难度很大。 cloud_wang
-
Kafka主题分区重新分配时,Flink作业持续失败
Kafka1.0.1 我使用200个分区的主题。flink使用这个主题。 最近,我进行了手动分区重新分配。 当我重新分配分区时,Flink连续失败并出现此错误。 错误1。 错误2. 错误3。 当我重新启动失败的作业时,这个错误会不断发生。 所以我重新启动了所有mesos和flink集群,并获得了动物园管理员的许可<有什么原因需要寻找吗?
-
从其他多分支管道触发多分支管道作业
我有一个场景,但我有两个项目(a和B),都在Jenkins中配置了多分支管道作业,问题是项目B依赖于项目a。 所以我发现有时候当我在项目A中签入代码时,我也需要在项目A构建后构建项目B。现在,在我开始调查管道构建之前,我将每个分支都有一个作业,然后在Jenkins中为相应的分支触发项目B的适当作业。 我想在Jenkins文件中设置什么,这样当ProjectA/develop执行时,它就会触发Pro
-
 毕业生一分钟自我介绍10篇
毕业生一分钟自我介绍10篇主要内容:毕业生一分钟自我介绍【篇1】,毕业生一分钟自我介绍【篇2】,毕业生一分钟自我介绍【篇3】,毕业生一分钟自我介绍【篇4】,毕业生一分钟自我介绍【篇5】,毕业生一分钟自我介绍【篇6】,毕业生一分钟自我介绍【篇7】,毕业生一分钟自我介绍【篇8】,毕业生一分钟自我介绍【篇9】,毕业生一分钟自我介绍【篇10】,毕业生一分钟自我介绍10篇范文 毕业生一分钟自我介绍的怎么写?有哪些?在面试过程中,有些面试官问一个问题,那就是你有什么优点?但是作为求职者的回答上,要尽量轻描淡写、语气平静,只谈事实,别
-
 中国农业银行广州分行一面
中国农业银行广州分行一面体验不是很好,要求很多,邮件说是10点半的面试,让提前半小时进一个腾讯会议房间,验证你的身份,给你一个编号和另外一个正式的面试腾讯会议房间号。问了面试官我大概排到了几点,说是正常时间,结果11点20还没排到我,中间会有人提示,多少号多少号准备,一直没写我我就没注意,结果突然拉我进去又踢出来了(当时在看手机,瞥见了腾讯会议图标亮了)。去私聊安排员,好家伙,意思听着像我等半个多小时无所谓,但是进去几十
-
了解mesos上spark作业的资源分配
我在Spark上从事一个项目,最近从使用Spark Standalone切换到使用Mesos进行集群管理。现在,我发现自己对在新系统下提交作业时如何分配资源感到困惑。 在独立模式下,我使用的是这样的东西(以下是Cloudera博客文章中的一些建议: 这是一个集群,其中每台机器有16个内核和大约32 GB RAM。 这样做的好处是,我可以很好地控制运行的执行器的数量以及分配给每个执行器的资源。在上面
-
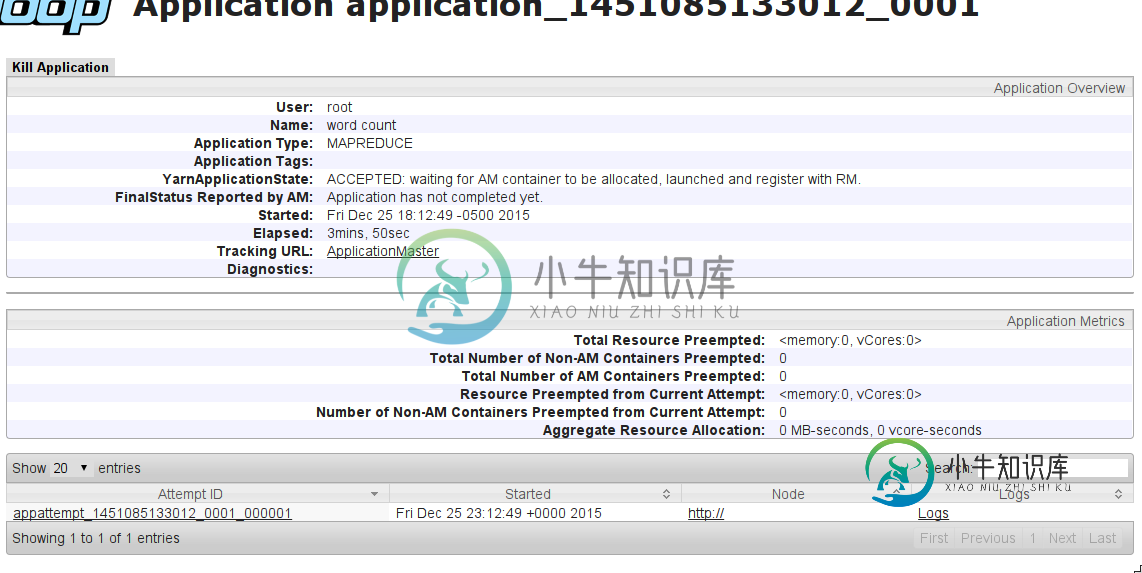 MapReduce作业挂起,等待分配AM容器
MapReduce作业挂起,等待分配AM容器我尝试将简单单词计数作为MapReduce作业运行。在本地运行时,一切工作都很好(所有工作都在Name节点上完成)。但是,当我尝试使用YARN在集群上运行它时(将=添加到mapred-site.conf),作业会挂起。 我在这里遇到了一个类似的问题:MapReduce作业陷入接受状态 作业输出: 会有什么问题? 编辑: 我在机器上尝试了这个配置(评论):NameNode(8GB RAM)+2x D
-
在Unix中以30分钟启动cron作业
我想从9:30到12点每两分钟运行一次cron作业。我该怎么做? 这是正确的吗?我应该在哪里加30?
-
Quartz Scheduler:如何将作业分组在一起?
我想问是否有人有同样的问题与石英调度器。我使用Trigger和JobKeys创建了作业,在这些作业中设置了groupnames。但当我打印出已设置的组时,它总是默认的。 如何设置此groupname以最终能够将作业分组在一起,最重要的是只取消指定的组?使用类似于下面这样的代码: 输出: