《数据分析》专题
-
 JavaEE中用response向客户端输出中文数据乱码问题分析
JavaEE中用response向客户端输出中文数据乱码问题分析本文向大家介绍JavaEE中用response向客户端输出中文数据乱码问题分析,包括了JavaEE中用response向客户端输出中文数据乱码问题分析的使用技巧和注意事项,需要的朋友参考一下 Web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象,和代表响应的response对象。request和response对象既然代表请求和响应,那我们要获取
-
 顺丰-大数据挖掘与分析工程师-一二三面面经(oc)
顺丰-大数据挖掘与分析工程师-一二三面面经(oc)一面 简历面,如果过往实习项目由机器学习等,比较关心其中数据预处理和特征处理,没有问coding和模型延伸问题(八股) 二面 对于项目中涉及的某个优化算法特别感兴趣,深挖概念、流程、优点、公式等 (第一次也是目前唯一被问到这个细节,真的要对简历熟悉) 压力大的时候喜欢干什么 hr面 为什么想来深圳 深圳还投了哪些公司 十一前发意向 总体觉得顺丰的问题难度很看分配到的面试官,和身边同学交流,有的就会
-
 快手电商数据分析实习面经(一面+二面,最终去向)
快手电商数据分析实习面经(一面+二面,最终去向)一面(7.4) 自我介绍 介绍一个数据分析的项目 你是什么时候做的这个项目 分析一下交易总额下降的原因 说一下抖音和快手的不同 写一个SQL # 1.每日活跃用户 select dt, count(*) activate_number from active_user_di where dt between '2022-11-01' and '2022-11-30' group
-
 广州银行信用卡中心策略数据分析实习生面试
广州银行信用卡中心策略数据分析实习生面试刚刚面试完,第一部分自我介绍,第二部分根据简历提问,第三部分反问。 重点第二部分,问得好细,从学校专业开始问(俺经管的),为什么会选择数据分析;第二部分揪比赛经历,也问的好细,那个比赛都是老历史了,俺真的不记得那么多了,问我比赛选题的自变量有哪些,y是啥多重结果?真的,现在让我翻聊天记录都找不到答案。第三个是实习经历,问了我写在简历上的每一个字!!!问的我都以为他想跳槽去我前东家的工作了 中间的过
-
 滴滴数据分析面试7|秋储-日常实习-提前批两面
滴滴数据分析面试7|秋储-日常实习-提前批两面滴滴秋储R-Lab,已oc,一面leader,二面部门领导 1. 自我介绍。 2. 对数据分析师的认识? 3. 分析滴滴订单量减少的原因? 4. 如何评价地铁的运营情况?(用户体验,安全,覆盖率等),虽然我出发点是从收入和成本去考虑的,但最后听面试官说指标差不太多。 5. 估计北京每天有多少单外卖? 6. 反问。 滴滴国际化部门数据分析日常实习,两面挂 1. 自我介绍。 2. 数据分析业务还是技术
-
 数据分析面经|字节跳动第6篇|暑期实习三面Offer
数据分析面经|字节跳动第6篇|暑期实习三面Offer一面,3月28日,40分钟 1. 自我介绍。 2. 深挖简历上的一个游戏数据项目。 3. 介绍简历上的数据爬虫和可视化项目是如何做的? 4. 如何对缺省值进行处理? 5. 对某案例挑战赛是如何估算出5%的销售额提升的? 6. 辛普森悖论。 7. 两道SQL:窗口函数以及group by。左连接和内连接的区别。 8. 机器学习的使用经历。 9. 反问。 二面,3月28日,40分钟 1. 自我介绍。
-
Firebase数据库未从Firebase数据库引用中提取数据
一切正常,但DatabaseReference无法获取数据,这就像是忽略了我的代码运行,就像我的internet无法运行一样,请帮助我,我是这个社区的新手,下面是我的代码和图片。 以前它是工作的,但由于我只是更改了一些代码,使只有currentVersion>=vCode,这样即使数据库中的值是 firebase数据库映像 mainactivity.java manifest.xml 依赖关系
-
如何根据Firebase数据库中的项目数筛选数据
我正在编写一个android聊天应用程序,并试图使用自定义FirebaceRecyclerAdapter在RecyRCleView中使用Firebase数据库实现无休止的滚动。对于第一个消息加载,我使用对数据排序的查询从Firebase数据库获取数据。orderByChild()和。limitToFirst(specificCount)到目前为止还不错。但当用户滚动到最后一个可见项时,我必须获取消
-
虚数与复数数据
当语句是作(plot)复变量时,虚部是忽略的,除非作图给出一个单复变元。对于这种特殊情况,有一捷径的命令来画出实部以及与之对应的虚部。因此, plot(Z) 其中Z是复向量或矩阵,其等价于 plot(real(Z),imag(Z)) 例如, t = 0:pi/10:2*pi; plot(exp(i*t),'-o') axis equal 作出一个二十边形并用小圆标记顶点,命令axis equ
-
使用SQL脚本创建用户,映射到数据库并将角色分配给该数据库
问题内容: 我之前已经做过,但是没有通过脚本来完成。我必须在SQL Server(SQL身份验证)中创建一个新用户,并将该用户映射到数据库,然后使用SQL脚本将该用户的角色分配给该数据库。 我该怎么做? 问题答案: 尝试: 显然将“用户名”,“域\用户名”和数据库角色更改为您希望授予其权限和访问级别的用户名,例如“ db_datareader”
-
如何通过jQuery将“多部分/表单数据”(图片、pdf等)保存到mysql数据库mediumblob中?
我正在建立一个评估工具。其逻辑是: > 在每个问题中,一旦我点击‘上传/查看文件',它会弹出一个模式;
-
为什么分报告中不同维度的数据相加会大于网站概况的数据
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么分报告中不同维度的数据相加会大于网站概况的数据 每个报告的分析维度不同,因此去重逻辑也不同。网站概况,以及趋势报告中的数据是以整个站点为维度去重的,是了解站点整体流量和访问量的地方。 例如:访客 X 通过百度搜索进入网站后又通过直接访问进入网站,此时,“搜索引擎”报告和“直接访问”报告会各记录一个独立访客数据,但是网站概况中只会记录一个独立访客数
-
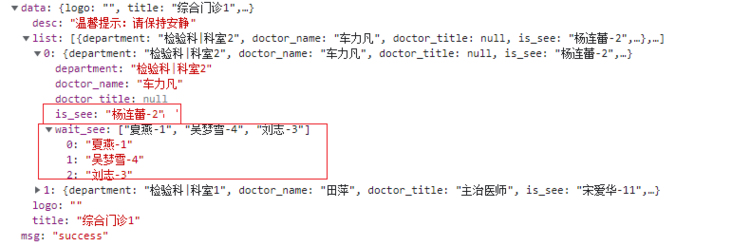 javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?
javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?这个是后端返回的数据,想把is_see和wait_see数据里面的名字和数字分开,然后分别把名字和数字渲染到页面上 这个是dom做遍历渲染 请问这个问题该怎么去弄呢?
-
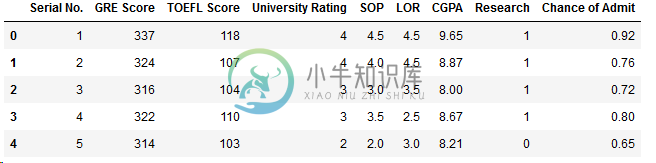 Python根据成绩分析系统浅析
Python根据成绩分析系统浅析本文向大家介绍Python根据成绩分析系统浅析,包括了Python根据成绩分析系统浅析的使用技巧和注意事项,需要的朋友参考一下 案例:该数据集的是一个关于每个学生成绩的数据集,接下来我们对该数据集进行分析,判断学生是否适合继续深造 数据集特征展示 1.导入包 2.导入并查看数据集 3.查看每个特征的相关性 结论:1.最有可能影响是否读硕士的特征是GRE,CGPA,TOEFL成绩 2.影响相对较小的
-
 快手数据研发一面(大数据、数仓、数开)
快手数据研发一面(大数据、数仓、数开)项目为sgg经典离线数仓 1. 自我介绍 2. 项目介绍(难点、亮点) 3. 根据难点亮点提问 4. 数据域是什么,如何划分数据域,为什么这样划分数据域 5. DIM层维度表的设计原则 6. DWD层事实表设计要点 7. mapreduce shuffle流程 8. maptask和reduce task 与哪些因素有关 9. 数据热点(数据倾斜)在哪些场景下出现,如何解决 10. spark是为