《数据分析》专题
-
将一列数据分成三列
我在excel中有一个列,其中包含名字、姓氏和职位名称的混合。唯一可以观察到的模式是——在每一组3行中,每第1行是名字,第2行是姓氏,第3行是工作标题。我想创建3个不同的列,并隔离此数据示例数据: 我想要:约翰,布什,经理,作为一行,分别放在名字,姓氏和职务下面的三个不同的栏中。像- 我们如何才能完成这项任务?
-
javascript数据类型示例分享
本文向大家介绍javascript数据类型示例分享,包括了javascript数据类型示例分享的使用技巧和注意事项,需要的朋友参考一下 前面我们介绍了javascript的数据类型,今天我们通过一些例子再来温故一下,希望大家能够达到知新的地步。 END 童鞋们是否对javascript的数据类型有了新的认识了呢,希望大家能够喜欢。
-
Spring数据可分页和LIMIT/OFFSET
我正在考虑将我们传统的jpa/道解决方案迁移到Spring Data。 但是,我们的前端之一是SmartGWT,它们的数据库组件仅使用限制/偏移逐步加载数据,这使得难以使用Pagable。 这会导致问题,因为无法确定限制/偏移量最终是否可以转换为页码。(这可能因用户滚动方式、屏幕大小等而异)。 我查看了切片等,但无法找到在任何地方使用限制/偏移值的方法。 想知道有没有人有什么建议?最理想的情况是,
-
数据分支和应用转换
我刚刚开始使用数据流,对于如何实现分支,我没有什么问题。
-
Cassandra中的数据重新分区
作为卡桑德拉数据分区的后续,我得到了vNodes的想法。感谢“西蒙·丰塔纳·奥斯卡森” 当我尝试使用vNodes进行数据分区时,我有几个问题, 我尝试观察2节点中的分区分布() 因此,根据我在两个节点中的观察,随着一个范围的扩展,节点61的值从-9207297847862311651到-9185516104965672922。。。 注意:分区范围从9039572936575206977到90199
-
属性的Spring数据Rest分页
我有两个使用分页和排序存储库定义的资源: 画廊/{id} 一般来说,这两种资源的分页都是根据使用的存储库类型提供的。 画廊本身包含一个图像列表 我现在可以通过 画廊/1/图片 是否也可以为这些子列表启用分页?或者,处理这些大列表的REST样式是什么。 事先谢谢你,圭多
-
火花数据帧范围分区
[新加入Spark]语言-Scala 根据文档,RangePartitioner对元素进行排序并将其划分为块,然后将块分发到不同的机器。下面的例子说明了它是如何工作的。 假设我们有一个数据框,有两列,一列(比如“a”)的连续值从1到1000。还有另一个数据帧具有相同的模式,但对应的列只有4个值30、250、500、900。(可以是任意值,从1到1000中随机选择) 如果我使用RangePartit
-
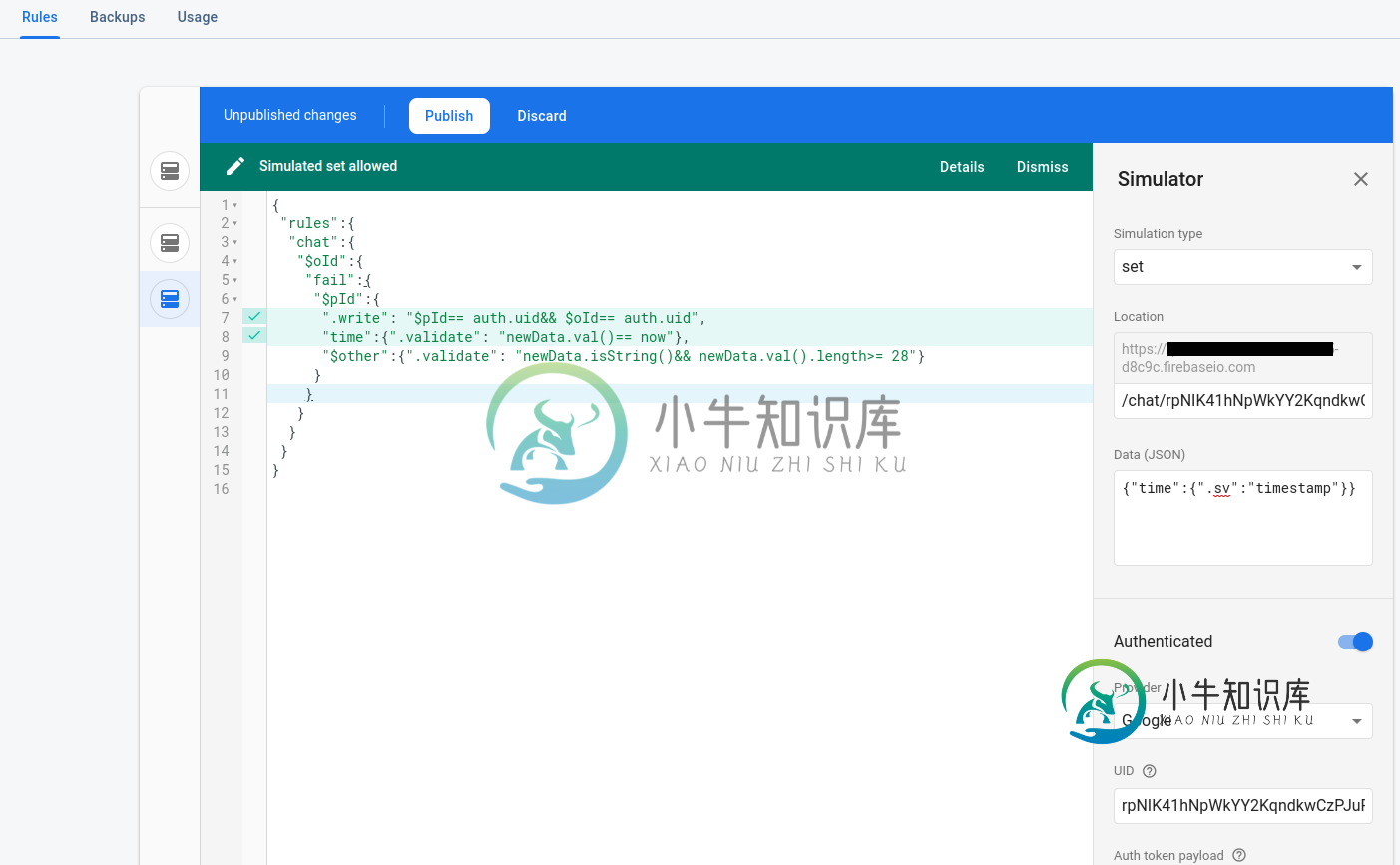 Firebase实时数据分片规则
Firebase实时数据分片规则更新2019-11-03:添加了错误的实时最小复制。在Chrome中加载链接后,点击ctrl shift i并选择控制台以查看输出。我已经尽力确保这正是我最初的项目代码所做的;我们看看情况是否如此,嗯?碎片的规则文件与下面的原始帖子相同。该源代码可在GitHub上获得。 原文: 这些规则在模拟器中工作,但在我真正的网络应用程序中不工作。模拟器路径和有效负载与下面数据库日志输出中显示的相同。 (将两
-
数据结构与算法 - 分治
分治和回溯其实本质上就是递归,只不过它是递归的其中一个细分类。可以认为 分治和回溯 最后就是 一种特殊的递归 或者是较为复杂的递归即可。 分治算法,即分而治之(divide and conquer,D&C),把 一个复杂问题 分成 两个或更多 的相同或相似 子问题,直到最后子问题可以简单地直接求解,最后将子问题的解合并为原问题的解。 分治法的核心思想就是,将原问题分解成小问题来求解,只要遵循三个步
-
图像分类数据集(Fashion-MNIST)
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST [1]。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST [2]。 获取数据集 首先导入本节
-
绘制分类数据(Plotting Categorical Data)
在前面的章节中,我们学习了散点图,hexbin图和kde图,用于分析研究中的连续变量。 当研究中的变量是分类时,这些图不适合。 当研究中的一个或两个变量是分类时,我们使用像striplot(),swarmplot()等那样的图。 Seaborn提供了这样做的界面。 分类散点图 在本节中,我们将了解分类散点图。 stripplot() 当研究中的一个变量是分类时,使用stripplot()。 它表示
-
可视化数据集的分布
在处理一组数据时,您通常想做的第一件事就是了解变量的分布情况。本教程的这一章将简要介绍seaborn中用于检查单变量和双变量分布的一些工具。 您可能还需要查看[categorical.html](categorical.html #categical-tutorial)章节中的函数示例,这些函数可以轻松地比较变量在其他变量级别上的分布。 import seaborn as sns import m
-
 华为OD机试数据分类
华为OD机试数据分类数据分类 对一个数据a进行分类,分类方法为:此数据a(四个字节大小)的四个字节相加对一个给定的值b取模,如果得到的结果小于一个给定的值c,则数据a为有效类型,其类型为取模的值;如果得到的结果大于或者等于c,则数据a为无效类型。 比如一个数据a=0x01010101,b=3,按照分类方法计算(0x01+0x01+0x01+0x01)%3=1,所以如果c=2,则此a为有效类型,其类型为1,如果c=1,
-
 Spark 2.3数据帧分区想要在n个分区中的密钥上对数据进行分区
Spark 2.3数据帧分区想要在n个分区中的密钥上对数据进行分区我需要spark(scala)数据帧分区方面的帮助。我需要按一个键列划分成n个分区,与同一个键相关的所有行都应该在同一个分区中(即,键不应该分布在整个分区中) 注意:我的钥匙可能有几百万 例如:假设我有下面的数据框 等等等等 正如您所看到的,许多值共享相同的键。我想将此数据集划分为"n"个分区,其中相同的键应该在相同的分区中,并且键不应该分布在分区之间。多个键驾驶室位于同一分区,键不可排序。 提前
-
 蔚来-数字系统数据分析师-一面面经
蔚来-数字系统数据分析师-一面面经7月18号约面试,7月19号下午面试。面试官挺和蔼的,但是我感觉是kpi面试。 面试内容:1、自我介绍。 2、因为简历没有实习经历,面试官询问了一下。 3、问会什么编程软件,Python,Sql,介绍了一下会的库和算法。 4、反问环节面试官介绍了一下工作内容等。 有友友投了一样的岗位可以一起交流呀! #蔚来面试##数据分析#