《Qualcomm高通》专题
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
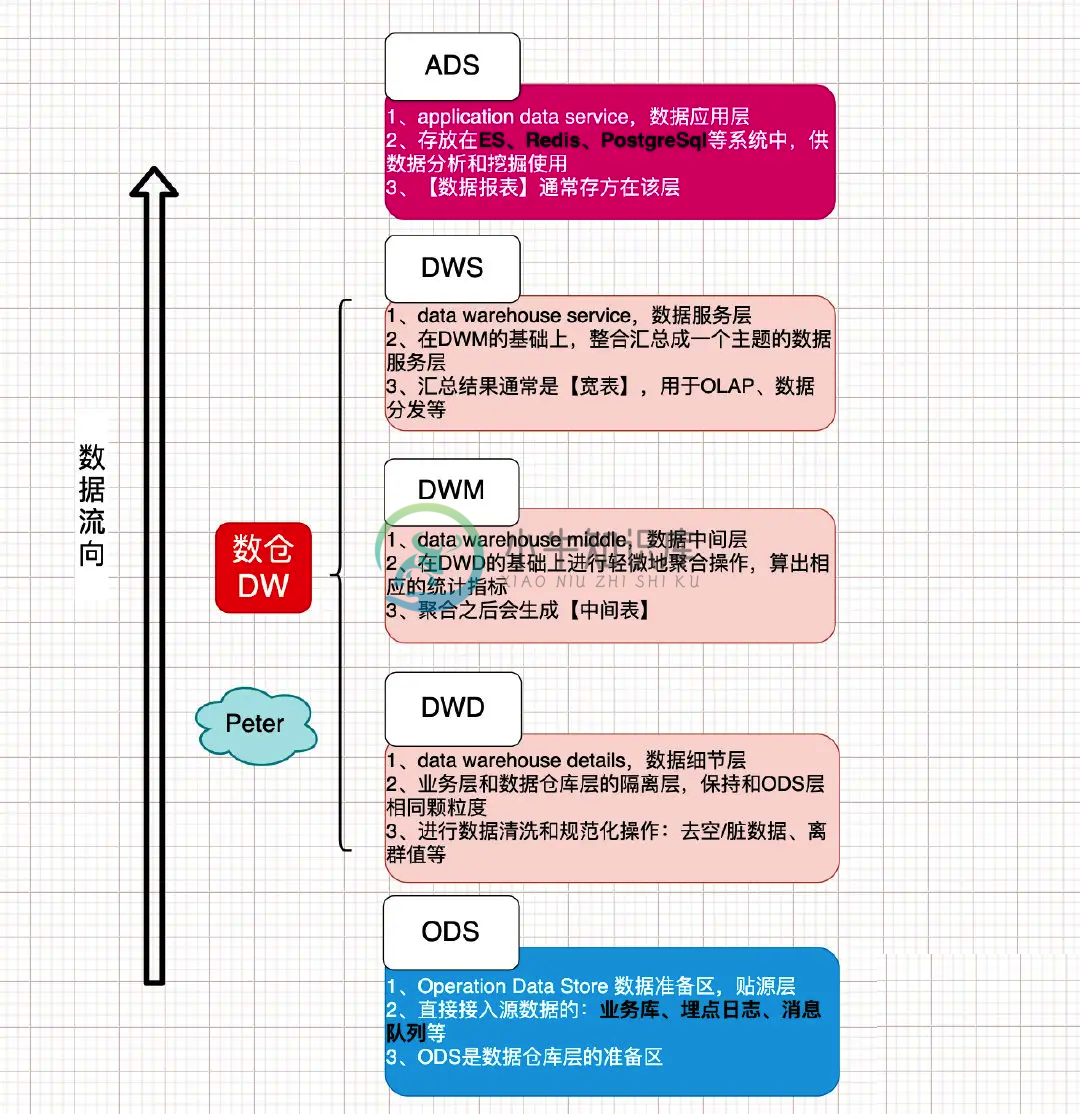 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
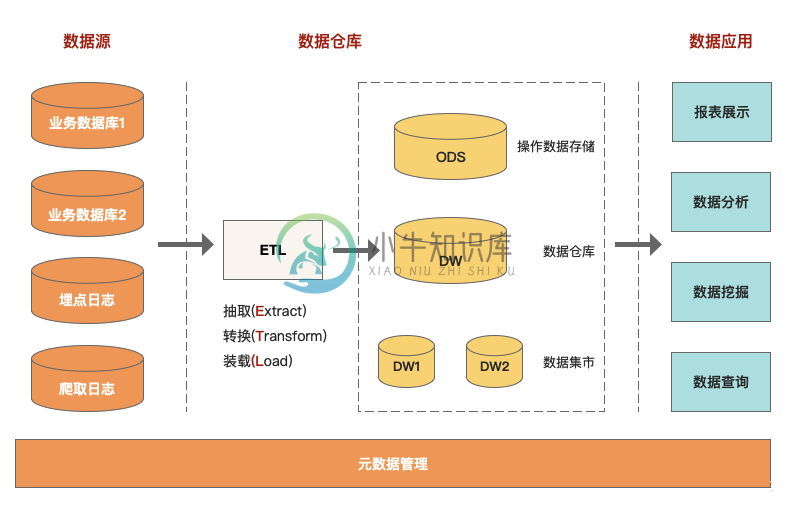 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
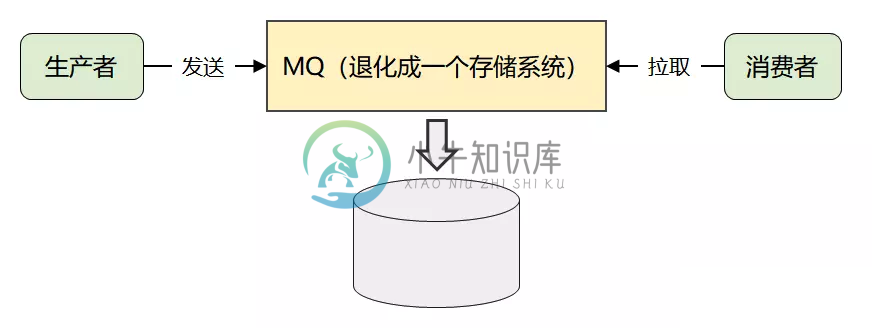 Kafka高性能设计之架构设计
Kafka高性能设计之架构设计主要内容:1.Kafka 的技术难点,2.Kafka 架构设计,3.Kafka的宏观架构设计,4.Kafka 的整体架构1.Kafka 的技术难点 Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行
-
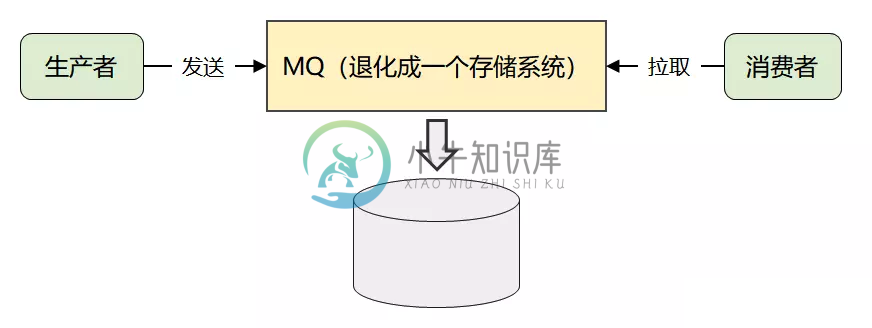 Kafka高性能设计之存储设计
Kafka高性能设计之存储设计主要内容:1.Kafka存储难度,2.Kafka 的存储选型分析,3.Kafka 的存储设计Kafka使用的是Logging(日志文件)这种很原始的方式来存储消息 对于存储设计有一些知识点: Append Only、Linear Scans、磁盘顺序写、页缓存、零拷贝、稀疏索引、二分查找等等。 Append Only Data Structures 的一些存储系统比如HBase, Cassandra, RocksDB 1.Kafka存储难度 Kafka 通过简化消息模型,将自己退化成了一
-
高仿微信打飞机-功能完善
之前有开发者发布的高仿微信打飞机游戏的代码(http://www.oschina.net/p/ios-wechat-plane),虽然模仿得惟妙惟肖,但有两点不足,一是没有背景音乐,二是不能暂停。这份代码“站在巨人的肩膀上”,根据之前的打飞机代码改进了这两点。具体改进地方如下: 1.整理代码成块; 2.添加跟为详细的注释,更方便大家看懂代码; 3.添加打斗的音乐(原来是无声音的),更像微信的打飞机
-
高仿败家姐手机淘宝客sdk
高仿百思不得姐App的败家姐模块。通过使用cuzysdk,可以快捷地在iOS平台和Android平台集成和加入淘宝客功能。代码在持续更新中,最新代码可在(https://github.com/TheIndex/Cuzy-iOS-demo)中下载。 cuzySDK(http://www.cuzy.com)是一个为移动开发者提供淘宝客模块的平台。开发者通过使用cuzy,可以便捷地将淘宝客模块集成到各移
-
高仿新百度贴吧列表效果
高仿百度贴吧App列表效果。特效包括:往上拖拉列表,下面新载入的列表行(cell)会有从大到小的动画效果(仅支持iOS6.0)。 下拉刷新和上拉加载更多会出现小熊图案,基本和新百度贴吧App效果一致。 [Code4App.com]
-
 高德Java后端社招面经(二面
高德Java后端社招面经(二面二面 自我介绍,并深入挖掘项目细节;RTree索引的构建方法;最近读了哪些书;Redis乐观锁的应用场景,并举例说明;编程题:多个线程从Redis获取一个数,进行随机累加,要求保证一致性,写出程序;算法题:给定发车时间和延误区间,判断当前时间能赶上的最近的车;Q&A环节,聊了高德的业务。 (已挂
-
 高德算法实习生(一面)面经
高德算法实习生(一面)面经2024年3月29日高德算法实习生岗位的一面面试。 这次面试主要是为了积累经验,虽然有些问题没有答上来,但还是希望能为大家提供一些参考。 面试过程 请介绍一段与算法相关的项目经验。 请解释Xgboost和GBDT的区别。 回答:两者都是梯度提升模型,但Xgboost使用二阶泰勒展开,而GBDT使用残差进行训练。Xgboost的决策树可以是回归树或分类树,训练速度较快,因为可以并行训练。 你有进行调
-
 高德地图 暑期实习 nlp 一面
高德地图 暑期实习 nlp 一面1.问项目 2.八股 因为在项目里面涉及了多模态的工作,问的时候也问了一点关于多模态的八股 CLIP的损失,图像和文本是怎么编码的? BLIP的损失 transformer为什么要用layernorm QK为什么要除dk Lora的原理 llama和chatglm的区别#面试经验##算法面试经验分享#
-
 高顿教育java实习一面面经
高顿教育java实习一面面经多线程创建方式 线程池参数 mysql事务 防止幻读 手写懒汉式单例模式 懒汉式和饿汉式效率哪个高 ioc和aop spring事务传播特性 没问项目 聊了聊个人的规划 大概半个小时左右
-
java - 如何提高BufferedInputStream的转换速度?
小弟对io流很陌生,请问大佬下面的代码怎么优化?图片5Mb的时候要等8sm,怎么提高加载速度?
-
elasticsearch - ElasticSearch 高效匹配邻近关键字?
elasticSearch搜索:比如,我有一个关键字是“北京地铁”,但是我只想搜索挨着的关键词,比如搜索【北京】或者搜索【地铁】或者在搜索【北京地铁】这种的可以保证能匹配到,但是如果隔词搜索就不让他显示出来,比如:【北地】,【京铁】,这种隔词了,就不让搜索出来如何处理,不采用match_phrase的方法,还有没有更加高效的方法? 我尝试过使用match_phrase可以做到我要的结果,但是mat