《农行省分》专题
-
从C ++程序调用python进行分发
问题内容: 我想从我的C ++程序中调用python脚本文件。 我不确定要分发给的人是否会安装python。 基本上,我正在寻找一个可以使用的具有Apache类似发行许可证的.lib文件。 问题答案: Boost有一个python接口库可以为您提供帮助。 Boost.Python
-
如何在MySQL中执行分组排名
问题内容: 所以我有一张桌子,如下所示: 然后,我需要对它们进行分组,排序和排序以给出: 现在,我知道您可以使用temp变量进行排名,例如此处,但是如何对分组集进行排名呢?感谢您的见解! 问题答案: 这以非常简单的方式起作用: 初始查询按第一,第二顺序排序。 并初始化为 用于测试是否输入下一组。如果的先前值(存储在中)不等于当前值(存储在中),则将其清零。否则增加。 分配了新值,并将在下一行的第3
-
如何在Elasticsearch中进行部分匹配?
问题内容: 我有一个类似于http://drive.google.com的链接,并且我想在该链接之外匹配“ google”。 我有: 但这仅在整个文本为“ google”时才匹配(不区分大小写,因此也匹配Google或GooGlE等)。如何匹配另一个字符串中的“ google”? 问题答案: 关键是您使用的ElasticSearch正则表达式需要 完整的字符串匹配 : Lucene的模式总是锚定的
-
如何在MySQL中进行连续分组?
问题内容: 我如何返回在MySQL中实际上是“连续的” GROUP BY。换句话说,GROUP BY是否尊重记录集的顺序? 例如,从下表中,col1是唯一的有序索引: 返回: 但我需要返回以下内容: 问题答案: 采用: 这里的关键是创建一个允许分组的人为值。 以前,更正了Guffa的答案:
-
使用JavaScript进行多个左侧分配
问题内容: 这等效于: 我相当确定这是定义变量的顺序:var3,var2,var1,这等效于此: 有什么方法可以用JavaScript确认吗?可能使用一些分析器? 问题答案: 其实, 是 不是 等同于: 区别在于范围: 实际上,这表明分配是正确的关联。该示例等效于:
-
如何使用Android对Firestore进行分页?
问题内容: 我阅读了Firestore文档以及Internet(stackoverflow)上有关Firestore分页的所有文章,但没有运气。我试图在文档中实现确切的代码,但是什么也没有发生。我有一个包含项目的基本数据库(超过1250个或更多),我想逐步获取它们。通过滚动以加载15个项目(到数据库中的最后一个项目)。 如果使用文档代码: 怎么做?文档没有太多细节。 PS:当用户滚动时,我需要使用
-
使用Jenkins SonarQube插件进行FxCop分析?
我试图在Jenkins构建中为.NET项目获得FxCop分析(调用独立的SonarQube分析)。 配置如下所示: Sonarqube 5.1.2 C#4.2 声纳-转轮2.4 Jenkins:SonarQube插件2.2.1 有没有什么方法可以让FxCop使用Jenkins插件和sonar-runner工作而不设置sonar.cs.FxCop.Assembly属性?
-
分发模式下的Kafka连接行为
我在分布式模式下运行Kafka连接,有两个不同的连接器,每个连接器都有一个任务。每个连接器都在不同的实例中运行,这正是我想要的。 Kafka connect集群是否总是确保相同的行为来适当地分担负载?
-
分块传输编码-浏览器行为
我正在尝试以分块模式发送数据。正确设置所有标题,并相应地对数据进行编码。浏览器将我的响应识别为分块响应,接受标题并开始接收数据。 我希望浏览器会更新每个接收到的区块的页面,而不是等到所有区块都被接收,然后显示它们。这是预期的行为吗? 我希望看到每个块在收到后立即显示。使用时,每个块在收到后立即显示。为什么GUI浏览器不会发生同样的情况?他们是否在使用某种缓冲/缓存? 我将标头设置为,所以不确定它是
-
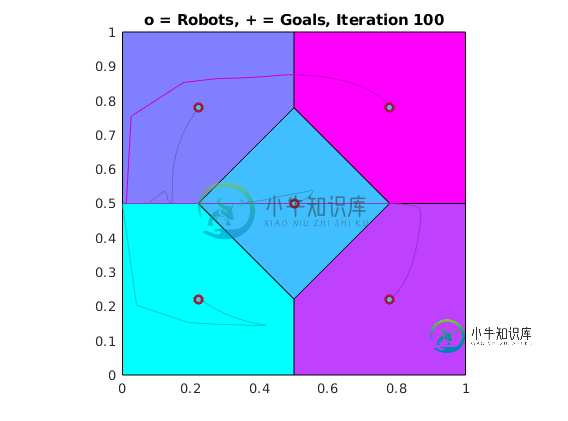 使用Lloyd算法进行锚定分区
使用Lloyd算法进行锚定分区我可以使用Lloyd算法将一个多边形划分为n个多边形。假设我使用上述算法将下面的多边形划分为5个多边形,得到如下结果:- 但我想进行锚定分区,这意味着我希望每个子多边形至少包含一个边界点,如下所示: 是否已经对算法进行了修改,可以帮助我实现这一点?如何确保锚定? 如果您可以引用一些现有的Matlab/python代码而不是伪代码,这将非常有用?我在上面使用的代码就是从这里开始的,它执行普通的实现。
-
Sails.Js-我如何在Sails.Js中进行分页
问题内容: 我想使用sails.js,mongodb和waterline-ORM创建分页表。 在sails.js中是否有任何特定的分页方法? 问题答案: http://sailsjs.org/#/documentation/concepts/ORM/Querylanguage.html 如果您希望分页异步工作,则使用JQUERY 和在服务器上非常容易 在水线和航行文档中有很多信息。
-
第四章 分布式和并行计算
目前为止,我们专注于如何创建、解释和执行程序。在第一章中,我们学会使用函数作为组合和抽象的手段。第二章展示了如何使用数据结构和对象来表示和操作数据,以及向我们介绍了数据抽象的概念。在第三章中,我们学到了计算机程序如何解释和执行。结果是,我们理解了如何设计程序,它们在单一处理器上运行。 这一章中,我们跳转到协调多个计算机和处理器的问题。首先,我们会观察分布式系统。它们是互相连接的独立计算机,需要互相
-
对熊猫分组操作进行排序
问题内容: 如何对pandas groupby操作应用排序?下面的命令返回一个错误,指出“布尔”对象不可调用 问题答案: 通常,排序是在groupby键上执行的,并且您发现您无法调用groupby对象,您可以做的是调用并传递函数并将列作为kwarg参数传递: 另外,您可以在分组之前对df进行排序: 更新资料 对于不建议使用的版本,请参见docs,现在应使用: 在这里在评论中添加@xgdgsc的答案
-
为什么该划分未正确执行?
问题内容: 我在Python中遇到一个奇怪的问题:除法未正确执行: 结果如下: 谢谢 问题答案: 上面的行为对于Python 2是正确的。Python 3中的行为已得到修复。在Python 2中,您可以使用: 然后用来获得您想要的结果。 由于要除以两个整数,因此得到的结果是整数。 或者,将数字之一更改为。
-
如何对pandas进行多索引分组?
问题内容: 以下是我的数据框。我进行了一些转换以创建类别列,并删除了其所属的原始列。现在,我需要进行分组,以除去公母,并且可以通过总和来汇总。 这是我创建数据框时创建的索引 我假设我想删除索引,并创建日期和类别,然后对指标进行求和。如何在熊猫数据框中执行此操作? 在Ubuntu 12.04上,Python为2.7,熊猫为0.7.0。下面是我运行以下命令时遇到的错误 问题答案: 您可以在现有数据框上