《农行省分》专题
-
使用Maven和TestNG进行Selenium并行测试
我正在尝试使用2个xml文件与Maven并行运行我的测试,但似乎不起作用。我已经尝试了Maven留档中的步骤/参数:http://maven.apache.org/surefire/maven-surefire-plugin/examples/testng.html 以下是我的pom.xml文件: 这是功能1.xml文件: 我应该做哪些参数/更改才能使其生效? 谢谢你
-
与surefire maven插件并行运行junit测试
它是可以配置surefire插件只运行一些测试并行和其他顺序? 也可以使用surefireforkCount来运行声明为jUnit Suite的并行测试吗?
-
完全可执行的未来执行顺序
我试图理解java中完整期货的非阻塞回调性质 有了上面的代码,我总是看到下面看到的输出 线程名称ForkJoinPool.common池工人-1 thenApply Thread name main thenApply Thread name main thenAcceptThread name main Thread name main 这个顺序似乎建议主线程等待所有Futures线程的执行。
-
perl6:一行一行读取大的gzip文件
我试图在Perl6中逐行读取gz文件,但是,我被阻止了: > 如何在Perl6中逐行读取gz文件,但是,这种方法将所有内容读入会使用太多的RAM,除了在非常小的文件上之外,它都不可用。 我不明白如何使用Perl6的逐行获取所有内容,尽管我在他们的github上打开了一个问题 https://github.com/retupmoca/P6-Compress-Zlib/issues/17 我正在尝试用
-
Spring boot命令行运行不使用logback-spring.xml
这个应用程序在IntelliJ中工作正常,并根据配置创建日志文件,但是当从命令行启动应用程序时,它不使用logback-spring.xml文件,而是继续创建*tmp/spring.log文件,该文件似乎来自Spring*logback/base.xml.我花了几天时间来解决这个问题,但似乎没有什么工作到目前为止,其他问题不能解决根本问题,感谢您的帮助。 我将以以下方式启动应用程序:- 我可以看到
-
在testng(xml配置)中禁用并行执行
我想也许我有一个@beforeSuite藏在某个地方,但这不是问题所在。我只在我的测试用例中使用@beforeClass+@afterClass,因此根据官方文档: @BeForeClass:在调用当前类中的第一个测试方法之前,将运行带注释的方法。 @AfterClass:在当前类中的所有测试方法都运行完之后,将运行带注释的方法。 发现这篇文章:在TestNG中停止并行执行 并尝试根据Cedric
-
单声道反应器-执行并行任务
我不熟悉Reactor框架,并尝试在现有的实现中使用它。LocationProfileService和InventoryService都返回一个Mono,并并行执行,彼此之间没有依赖关系(来自MainService)。在LocationProfileService中-发出了4个查询,最后2个查询依赖于第一个查询。 有什么更好的方法来写这个?我看到调用按顺序执行,而其中一些应该并行执行。正确的做法是
-
并行运行测试时,覆盖Webdriver对象
但是当我运行test时,两个浏览器实例都打开了(Chrome首先打开并开始执行,延迟后Firefox打开)。在这种情况下,驱动程序对象被Firefox驱动程序覆盖,chrome停止执行。测试继续在Firefox上执行并成功完成。 项目的结构是这样的: 创建了一个DriverBase.class来加载与浏览器对应的驱动程序,该浏览器具有my@beforeSuite. crteated页面的单个类。(
-
Selenium Grid for Webdriver TestNG的并行执行问题
我正在尝试用Web驱动集线器和TestNG并行机制设置Web驱动程序并行执行。我正面临线程的问题 我有一个扩展TestBaseSetUp的类,它有一个Beforemethod和Aftermethod,并设置为始终运行。对于Web驱动程序的并行执行,我想使用线程本地,但是@测试和@之前/@之后方法在不同的线程中。所以如果我在我的TestBaseSetUp中设置Web驱动程序为线程本地,并尝试进入我的
-
TestNG Selenium Grid 2没有并行运行测试
当我试图在Selenium Grid 2旁边使用TestNG并行运行测试时,我似乎遇到了一个问题。 尽管打开的浏览器数量与我正在运行的测试数量相匹配,但所有测试的所有指令都被发送到同一个浏览器窗口。例如,每个测试都会打开一个页面并尝试登录。四个浏览器窗口将打开,但一个浏览器窗口将导航到登录页面四次,然后键入用户名四次,而其余的浏览器窗口保持不活动。 以下是我如何启动网格: xml套件是这样设置的:
-
如何在cmd行中运行java类文件
我的两门课是这样的: 和 我无法使用编译这两个文件,错误是: a、 java:4:找不到symbol symbol:B类位置:p.a类 B类B=新B(“哈哈”) ^ a.java:4:找不到符号 符号:B类 位置:p.a类 B类=新B(“哈哈”) ^ 2个错误 移除
-
如何运行尚未运行的docker容器
只有当docker容器尚未运行时,我才需要运行它。给了这个命令。如果它不存在,我将如何运行它。 我对任何脚本或语言都持开放态度。
-
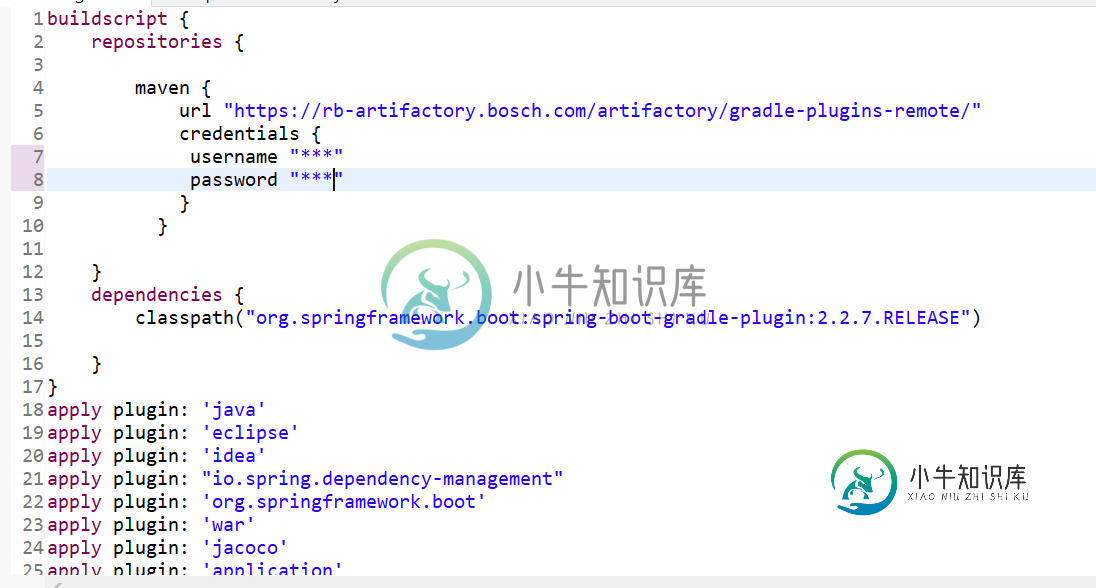 无法在命令行中运行gradle程序
无法在命令行中运行gradle程序分级测试 任务:编译Java FAILED 失败:生成失败,出现异常。 出错的地方:任务': compileJava'执行失败。 无法解析配置': detachedConfiguration1'的所有依赖项。无法解析org.springframework.boot: spring-boot-依赖项:2.2.7.RELEASE.需要:项目:
-
获取所选primefaces数据表行的行号
在JSF页面中,我需要显示(选定行数)的(总行数)。我可以使用rowIndexVar属性在其中一列中显示行号,但我不知道在行选择的输入文本中单独显示相同的数字。 我需要在JSF页面或托管bean中做什么才能获得所选的行号。 请在这方面帮助我。 下面是我的JSF页面
-
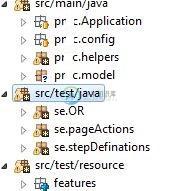 直接从可执行jar运行Cucumber测试
直接从可执行jar运行Cucumber测试我有一个项目与cucumber和maven也我使用JUnit。 我能够从Eclipse成功地运行和构建我的项目。 现在,我想在另一个没有安装eclipse或cucumber的系统中从命令行运行测试。我有一个想法,我们可以从JAR创建一个JAR,我们可以通过java cli命令运行测试。 我已经在类路径中添加了JUNIT Jar。 我以两种方式生成jar, 1)使用->project->export