《网易雷火笔试》专题
-
火花工和执行器芯
我有一个Spark集群运行在hdfs之上的纱线模式。我启动了一个带有2个内核和2G内存的worker。然后我提交了一个具有3个核心的1个执行器动态配置的作业。不过,我的工作还能运转。有人能解释启动worker的内核数量和为执行者请求的内核数量之间的差异吗。我的理解是,由于执行者在工人内部运行,他们无法获得比工人可用的资源更多的资源。
-
火花流和高可用性
我正在构建作用于多个流的Apache Spark应用程序。 我确实阅读了文档中的性能调优部分:http://spark.apache.org/docs/latest/streaming-programming-guide.html#performan-tuning 我没有得到的是: 1)流媒体接收器是位于多个工作节点上,还是位于驱动程序机器上? 2)如果接收数据的节点之一失败(断电/重新启动)会发
-
用TTL节省Cassandra的火花
我正在使用Spark-Cassandra连接器1.1.0和Cassandra 2.0.12。 谢谢, 沙伊
-
 烽火通信 一面面经
烽火通信 一面面经新鲜出炉的一面 地点西安,C++软开 大概20分钟 #校招# #秋招# #面经# 1. 说一下C++内存分区,以及各个分区中分别存储什么类型变量? 2. 为什么要把析构函数声明成虚函数? 3. 什么是动态绑定? 4. 刚刚你说到了把析构函数声明成虚函数是为了防止派生类造成内存泄露?那么如果基类的析构函数没有声明成虚函数,就一定可以造成内存泄露么? 5. 了解C++容器吗? 6. 说一下vector
-
 烽火星空c++一面20min
烽火星空c++一面20min自我介绍,针对项目问了几个相关的八股,不深。最后问了几个c++很简单的问题和计网的基础,最后反问,面完10min短信说过了#烽火星空#
-
 烽火星空一面+二面
烽火星空一面+二面如题,楼主面试的是测试 一面问题: 1.测试的基本流程 2.开发流程 3.测试方法有哪些 4.单元测试和集成测试的区别(好像是,不太记得了) 5.测试模型(w,v等等) 还有的不太记得了,想到了再补充 二面 我的二面是非技术的 1.学过的课程 2.就学过的课程提了一个问题(我说学了软件工程导论,所以他问了软件危机) 3.排名 4.觉得自己聪明吗 5.有没有奖学金 6.有没有比赛获奖 7.有没有论文
-
 烽火通信测开面经
烽火通信测开面经一面 自我介绍 介绍实习的主要工作 了解的测试理论 如何编写测试用例 bug管理 bug状态 什么时候推动研发修复bug 对测开的理解 linux修改权限指令? 数字分别代表什么? 什么是测试左移 在校成绩怎么样 考研还是保研 是党员吗 学生干部工作 项目获奖情况 奖学金情况 记得还问了高考考研分数 反问 感觉还行 后续没消息了 应该是成都招满了吧 #23届秋招笔面经#
-
火炬get_device_name和current_device被绞死?
我刚刚在我的机器上安装了一个新的GPU(RTX2070)和旧的GPU。我想看看Pytork是否捡到了它,所以按照这里的说明:如何检查Pytork是否正在使用GPU?,我运行了以下命令(Python3.6.9、LinuxMintTricia19.3) 两个停止的过程都需要一些时间,其中一个过程将机器冻结了半分钟左右。有没有人有这方面的经验?是否缺少一些设置步骤?
-
禁用火狐同源策略
我正在开发一个本地研究工具,要求我关闭Firefox的同源策略(就脚本访问而言,我并不真正关心跨域请求)。 更具体地说,我希望宿主域中的脚本能够访问嵌入在页面中的任何iframe中的任意元素,而不管它们的域是什么。 我知道以前的问题 如果这不能很容易地完成,我也会很感激任何见解,指出我的FF src代码的具体部分,我可以修改禁用SOP,以便我可以重新编译FF。
-
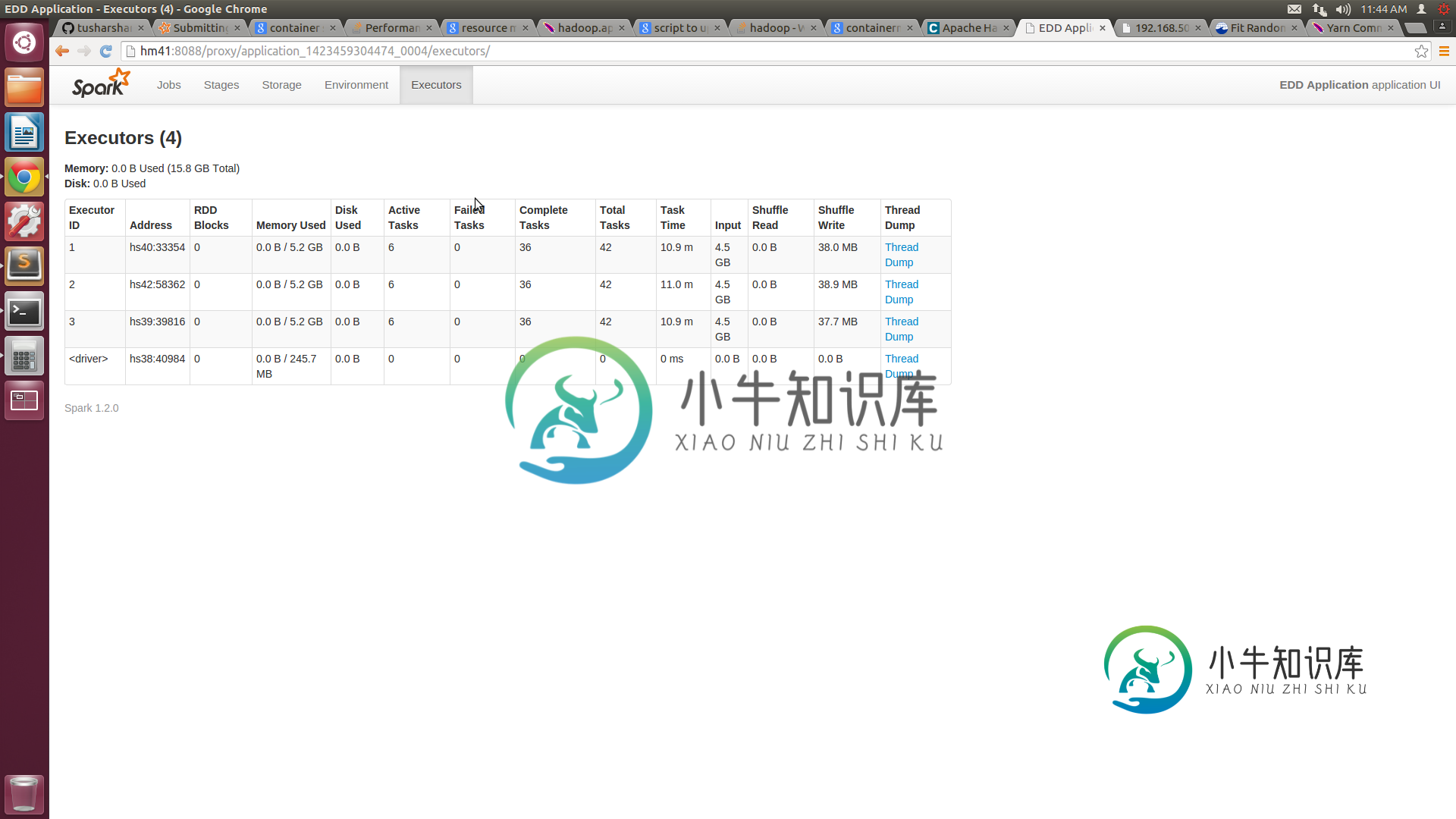 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
Google guava singleton Eventbus多次开火
我使用vaadin spring IOC google guava eventbus。参考资料建议将guava eventbus用作singleton。但当我这样做时,我有以下问题:; > 假设我同时在3个不同的浏览器上运行应用程序,那么我的应用程序有3个不同的实例。 然后,例如,当我按下一个浏览器上的按钮并触发一个事件时,我注意到我的带有@subscribe注释的相关侦听器方法被调用了3次! 这
-
模拟退火,蚁群对比
本文向大家介绍模拟退火,蚁群对比相关面试题,主要包含被问及模拟退火,蚁群对比时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 模拟退火算法:退火是一个物理过程,粒子可以从高能状态转换为低能状态,而从低能转换为高能则有一定的随机性,且温度越低越难从低能转换为高能。就是在物体冷却的过程中,物体内部的粒子并不是同时冷却下来的。因为在外围粒子降温的时候,里边的粒子还会将热量传给外围粒子,就可能导致局
-
引发异常的火花sortby
我正在尝试按键对JavaPairRDD进行排序。 块引号
-
火花createDataFrame()不使用Seq RDD
CreateDataFrame接受2个参数,一个rdd和模式。 我的图式是这样的 <代码>val schemas=结构类型(Seq(StructField(“number”,IntegerType,false),StructField(“notation”,StringType,false))) 在一种情况下,我能够从RDD创建数据帧,如下所示: 在以下其他情况下。。我不能 data2不能成为Da
-
火花内存不足错误
我的spark程序在小数据集上运行良好。(大约400GB)但是当我将其扩展到大型数据集时。我开始得到错误