《矢量图》专题
-
使用R中的矢量多边形提取光栅像素值
我已经为此挣扎了几个小时。我有一个包含177个多边形(即177个县)的shapefile(称为“shp”)。这个shapefile覆盖在光栅上。我的光栅(称为“ras”)由具有不同污染值的像素组成。 现在我想提取每个多边形的所有像素值及其出现次数。 这正是QGIS功能“分区直方图”所做的。但我想在R中做同样的事情。 我尝试了提取()函数,并设法获得了每个县的平均值,这已经是第一步,但我想制作像素分
-
 android中谷歌地图中带有矢量资产图标的自定义标记
android中谷歌地图中带有矢量资产图标的自定义标记我们如何能实现一个地图标记图标与矢量资产文件,谷歌显示的方式是这样的,编程: 更新: 这在处理向量资源时不起作用。问这个问题的主要原因。上述代码中的错误: java.lang.非法参数异常:解码图像失败。提供的图像必须是位图。
-
如何使用Tensorflow使用Python查看矢量化数据的样本?
本文向大家介绍如何使用Tensorflow使用Python查看矢量化数据的样本?,包括了如何使用Tensorflow使用Python查看矢量化数据的样本?的使用技巧和注意事项,需要的朋友参考一下 Tensorflow是Google提供的一种机器学习框架。它是一个开放源代码框架,可与Python结合使用,以实现算法,深度学习应用程序等等。它用于研究和生产目的。 可以使用下面的代码行在Windows上
-
使用python中的矢量化解决方案计算最大跌幅
问题内容: 最大跌幅是量化金融中用于评估已经历的最大负收益的常见风险度量。 最近,我变得不耐烦使用循环方法来计算最大跌幅。 我熟悉一个普遍的看法,即向量化的解决方案会更好。 问题是: 我可以将这个问题向量化吗? 这个解决方案是什么样的? 有什么好处? 编辑 我将亚历山大的答案修改为以下功能: 问题答案: 假定是收益的数据框架,其中每一列是单独的策略/经理/安全性,而每一行是一个新日期(例如,每月或
-
如何在Spark中将映射类型转换为SparkML稀疏矢量?
我的原始模式包含许多我想在ML模型中使用的映射类型,因此我需要将它们转换为SparkML稀疏向量。 背景:SparkML模型要求将数据形成特征向量。有一些实用程序可以生成特征向量,但都不支持maptype类型。e、 g.SparkML VectorAssembler允许组合多个列(所有数字类型、布尔类型或向量类型)。 编辑: 到目前为止,我的解决方案是将映射分解为单独的列,然后使用向量汇编程序:
-
Spark-将矢量数据拆分、转换和存储到CSV文件中
请看下面这个数据文件的架构 > 问题1:我需要将第一列数据分成两列,这样整数数据应该在一列中,数组数据应该在另一列中。不确定如何在Spark/Scala中实现?任何关于这一点的指示都将是有帮助的。 当我试图将此数据文件写入csv文件时,我得到了以下错误
-
如何在 不复制矢量的情况下将 Vec 转换为 Vec?
我想转换一个
-
将JUNG图导出到高分辨率图像(最好是基于矢量的图像)
问题内容: 在我的一个项目中,我使用JUNG2可视化显示在applet中的非常大的多父级层次结构图。我需要将图形的全部/部分导出为高分辨率的静止图像,因为屏幕截图在打印时看起来很丑陋(特别是如果图形已经缩小)。 我当前使用的代码如下: 这会创建不是特别高分辨率的PNG图像。所以我的问题如下: 是否可以将PNG导出分辨率提高到300 dpi? 是否可以将图形或与此相关的任何摆动组件导出为基于矢量的格
-
单击矢量资产导入向导上的剪辑艺术图标不起作用
单击Vector Asset Import Wizard上的剪贴画按钮会导致android studio JSON对材质图标元数据文件的反序列化异常,但什么都没有发生 例外 我无法将向量资源导入到我的项目中我可以做些什么来解决此问题?
-
在向反应原生项目添加矢量图标时生成失败的异常
我必须在我的react原生项目中使用矢量图标,在为android平台构建(react原生运行android)时,我遇到了这个错误。 执行以下步骤添加矢量图标: npm安装反应本机矢量图标–保存 反应-本机链接 有人能帮助解决这个问题吗? 失败:构建失败,有一个异常。*出了什么问题:配置项目: app时出现问题。 无法解析配置“”的所有依赖项:应用:\ u debugApk'。配置项目时出现问题:“
-
在什么条件下. NET即时编译器执行自动矢量化?
新的RyuJIT编译器是否生成过向量(SIMD)CPU指令,以及何时生成? 旁注:系统。Numerics命名空间包含允许显式使用向量操作的类型,向量操作可能生成也可能不生成SIMD指令,具体取决于CPU、CLR版本、JITer版本,无论是否直接编译为本机代码。这个问题具体是关于非矢量代码(例如C或F中的)何时会生成SIMD指令。
-
如何改变矢量绘制背景当你点击按钮在Android Studio?
-
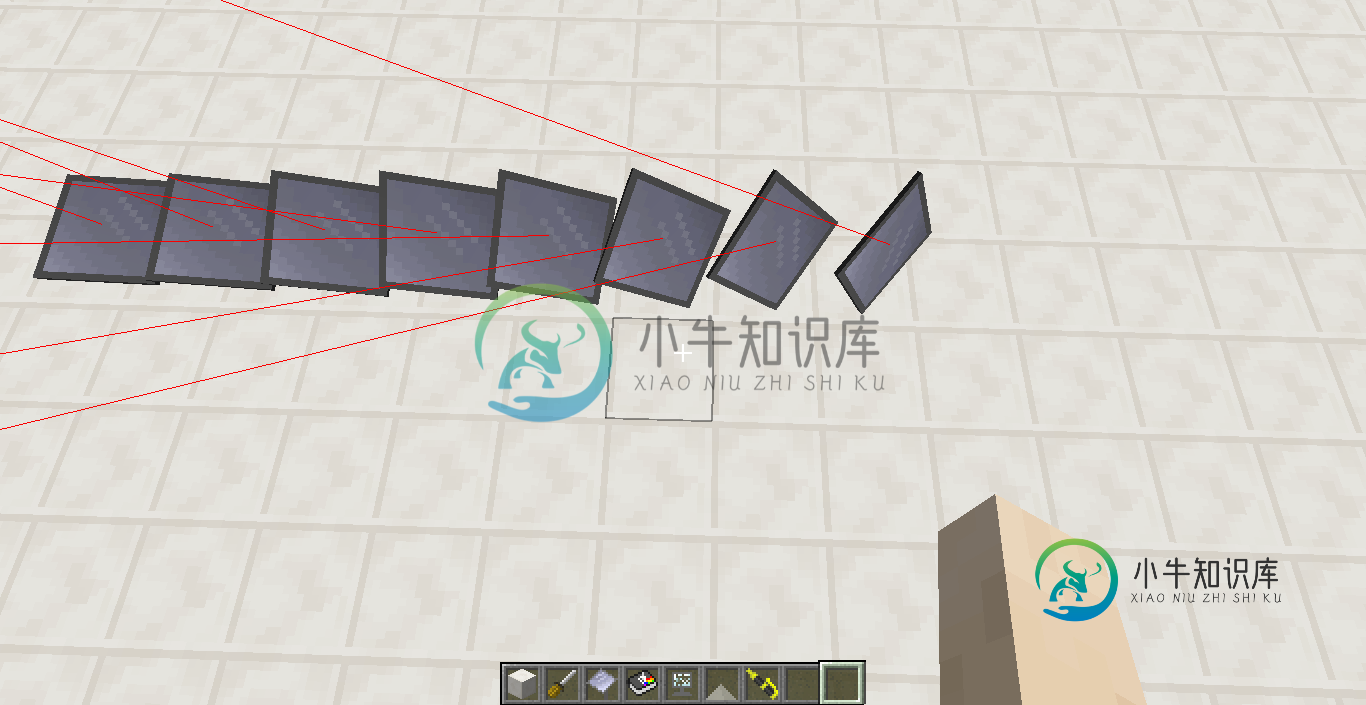 无法根据俯仰和偏航正确计算法线/方向矢量
无法根据俯仰和偏航正确计算法线/方向矢量我的投球和打哈欠都搞砸了。我有垫子的俯仰和偏航,但光束的俯仰和偏航都搞砸了。如何计算垫的俯仰和偏航的法向量?我在stackoverflow上尝试了一大堆数学,但到目前为止都失败了。 我接下来尝试做的是将光束的俯仰和偏航从垫子的俯仰和偏航中分离出来,并分别计算它们。这基本上有效,但偏航仍然完全混乱。 我过去是通过光束的偏航和俯仰来计算方向向量的,这是一个util minecraft用来计算暴徒的方向
-
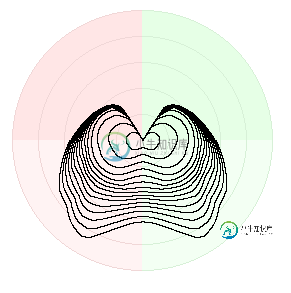 选择一对矢量以获得最佳“之字形”轮廓的算法
选择一对矢量以获得最佳“之字形”轮廓的算法我有一组不同的二维向量(在实数上),指向不同的方向。我们被允许选择一对向量并构造它们的线性组合,使得系数是正的,它们的总和是1。简而言之,我们被允许对任何两个向量进行“加权平均”。 我的目标是在任意方向上选取一对向量,其“加权平均值”在这个方向上并且最大化。说到代数给定的向量a和b以及方向向量n,我们对最大化这个值感兴趣: [a交叉b]/[(a-b)交叉n] 即选择最大化该值的a和b。 (此图中的
-
为什么SSE矢量化在这种情况下没有更快?[重复]
我的SSE代码和标准的C代码一样慢,我做错了什么? 我在Intel i3-6100 CPU上运行,使用C和minGW和CLion,我使用-O0标志。 在使用clock()函数测量性能时,两个版本的速度一样快,都达到了大约45节拍(超过1000节拍)(SSE:1138节拍-C:1093节拍)。我认为SSE不知何故打乱了时钟()的时间测量,但即使只是简单地计算秒,也没有什么不同。 函数 :(交换注释.