《中兴优招》专题
-
 美团运筹优化算法二面
美团运筹优化算法二面平台,问了面试官是二轮技术面+一轮HR面 9.21一面 1.拷打项目和论文,详细问了VRP精确算法里的创新点(是论文里的) 2.国赛项目建模优化办法 3.八股:启发式算法,精确算法 4.手撕:矩阵左上角到右下角的路径数 9.22约二面 9.25二面 1.继续拷打项目和论文,硕士期间成果因为全是数学理论的东西所以说的很一般 2.实习经历,什么场景,做了什么 3.继续国赛项目,什么场景,做了什么,有什
-
 美团优选 移动端一面 1h
美团优选 移动端一面 1h捞起来面的,本来之前三个志愿都结束的 1. 自我介绍 2. 问项目和实习 3. 手撕: 把n分钱随机分给m个人,每人不小于等于1分钱 没撕出来,random类忘了参数是怎么写的了,蠢,写到后面有点摆烂 总结: 手撕没撕出来有点难受,实习项目讲得挺透彻,面试官没什么疑问,但是自己写的项目因为有些代码没有自己写,感觉次次被问住了,次次被挖的头掉😭,我都想把那俩在简历上删了完事
-
 虹软科技 算法优化 笔试
虹软科技 算法优化 笔试#24届软开秋招面试经验大赏# 投递岗位:算法优化工程师 笔试时间:8.20 120min 双机位 笔试题型:20个不定项选择、2个编程、1个数据结构论述题、1个4选1的论述题 笔试考察知识点: 选择题涉及概率分布、贝叶斯概率计算、排列组合、函数求极限、机器学习、矩阵奇异值分解、C/C++基础知识、图像处理方法、HOG特征、SIFT特征、进程与线程、算法时间复杂度计算等等。 编程有点难度,第1题5
-
 美团优选测开 一面面经
美团优选测开 一面面经47分钟 比较简单,可能是kpi 1.自我介绍 2.技术是自学的? 3.项目介绍,说一下难点,你的提升 4.手撕快排,1分钟写完,结果写测试用例判断特殊字符输入的时候稍微出了点问题 5.URL输入后的过程 6.HTTP各版本的特征 7.HTTP的响应状态码 8.mysql数据库事务,知道多少说多少 9.redis非关系型数据库,知道多少说多少(脑抽少说了一个基本数据类型) 10.ip地址除了存DN
-
 8.25美团优选前端一面(凉)
8.25美团优选前端一面(凉)时长:60分钟左右 自我介绍 如何学习前端的 学习前端知识多久了 编译型语言和脚本语言有什么区别,分别有哪些语言是编译型语言,脚本语言 会不会一门编译型语言 OSI七层网络协议,TCP/IP五层网络协议,分别介绍一下 五层协议少的那两层协议具体是干什么的 应用层主要用作用? 运输层主要干什么的? http和https的区别 介绍一下https具体的加密方法,怎么实现的 TCP和UDP的区别 TCP
-
 微网优联 数据仓库 面经
微网优联 数据仓库 面经Timeline: 10.14 投递 10.18 一面 10.25 二面 10.18 一面 21min: 1.项目介绍 2.具体数据表 3.存储数据量达到多少 4.Mysql数据类型 5.聚集索引和非聚集索引 6.怎么处理数据丢失 7.对redis的理解 8.http协议 9.了解的基础数据结构与算法 10.介绍一种排序算法 11.怎么远程连接到linux服务器 12.部署过服务器吗 10
-
 ES性能优化原理大揭秘
ES性能优化原理大揭秘主要内容:1、一道面试题的引入:,2、性能优化的杀手锏:Filesystem Cache,3、数据预热,4、冷热分离,5、ES中的关联查询,6、Document 模型设计,7、分页性能优化1、一道面试题的引入: 如果面试的时候碰到这样一个面试题:ElasticSearch(以下简称ES) 在数据量很大的情况下(数十亿级别)如何提高查询效率? 这个问题说白了,就是看你有没有实际用过 ES,因为啥?其实 ES 性能并没有你想象中那么好的。 很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的
-
Java性能优化的七个方向
主要内容:文章目录,1.复用优化,2.计算优化,2.3 惰性加载,3.结果集优化,4.资源冲突优化,5.算法优化,6.高效实现,7.jvm 优化,8.总结复用优化 结束集优化 高效实现 算法优化 计算优化 资源冲突优化 jvm 优化 1.复用优化 编码逻辑上的优化: 重复的代码可以提取出来,做成公共的方法。 数据复用: 缓存和缓存 : 常见于对数据的暂存,然后批量传输或者写入。多使用顺序方式,用来缓解不同设备之间频繁地、缓慢地随机写,缓冲主要针对的是。 : 常见于对已读取数据的复用,通过将它们缓
-
 Api接口优化的几个方法
Api接口优化的几个方法主要内容:1.哪些问题会引起接口性能问题,2.问题解决1.哪些问题会引起接口性能问题 数据库慢查询 深度分页问题 未加索引 索引失效 join过多 子查询过多 in中的值太多 单纯的数据量过大 业务逻辑复杂 循环调用 顺序调用 线程池设计不合理 锁设计不合理 机器问题(fullGC,机器重启,线程打满) 2.问题解决 2.1 慢查询(基于mysql) 深度分页 当分页所以深度不大的时候当然没问题,随着分页的深入 这个时候,mysql会查出来10000
-
 美团运筹优化实习二面
美团运筹优化实习二面60min 1.前30min主要围绕项目问,问细节 2.说一下列生成怎么求解子问题的 3.分枝定价框架如果想要求解很大规模的问题,得到一个满意解,该怎么做调整 4.简单说一下xgboost 然后手撕一道题,我理解错题目了,场面十分尴尬,面试官还给我提示,依旧尴尬 然后问了些技术无关的问题,喜欢做哪个方向、团队合作中的优缺点之类的 总结:手撕代码场面十分尴尬,回去老老实实刷题吧
-
 美团优选物流运营二面
美团优选物流运营二面1.面试了接近30分钟 2.深挖简历上的实习内容 3.问专业问未来职业规划
-
 美团优选前端一面面经
美团优选前端一面面经1.面试官介绍 2.自我介绍 3.为什么学习前端 4.介绍一下项目 5.扣项目细节 6.考JS的输出(有一些卡住的地方面试官很耐心的引导) 7.v-if v-show 区别 8.vue2跟vue3的区别 9.编程题:手写数组扁平化 10.反问 面试官超好 问的也不难主要是抠项目 #前端##面经##美团#
-
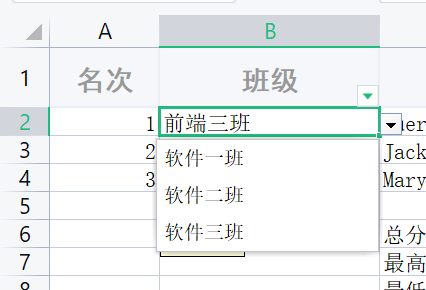 前端 - 设置excel下拉框优化?
前端 - 设置excel下拉框优化?背景: 技术栈:项目: vue3 + vite 场景: 希望导出的excel的某一列填充下拉框内容,例如 尝试: 相关代码如下 上述代码一次只能给某一个单元格加下拉框,所以要达到使B列单元格都加上下拉框的目的,就要给一个很大的终止值,去循环遍历。 有没有什么更好的方法去优化?
-
java - mysql sql语句优化的问题?
我有个商品表里面有30多万的数据,商品标题是中文,系统模糊查询的时候老是会显示慢,同时我在这个字段创建了一个普通索引;但是查询还是会慢?请教高手要如何进行优化? select * from goods_name where title_name like "%电器%"
-
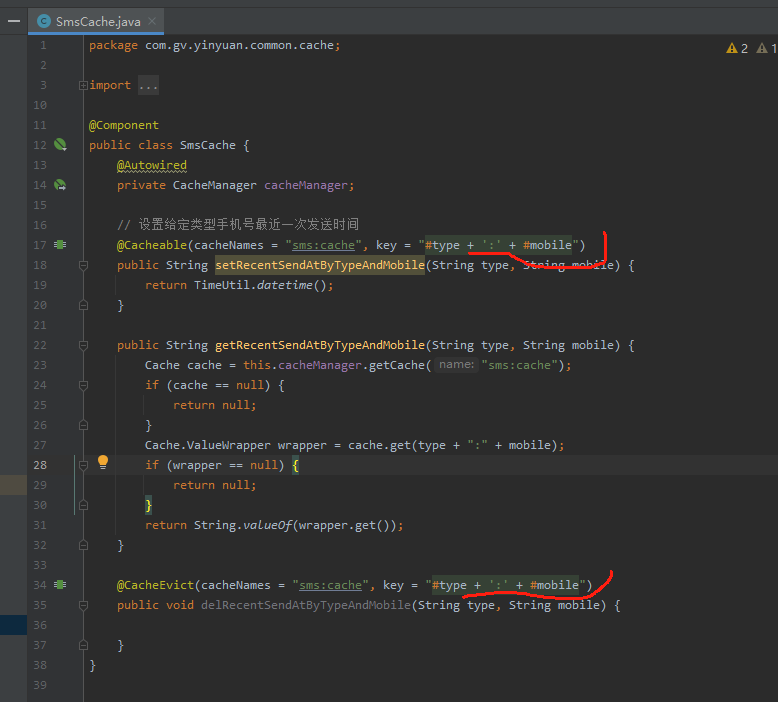 spring - Spring Cache如何简化和优化?
spring - Spring Cache如何简化和优化?关于spring缓存的问题: 类似我通过注解方式定义的缓存,我定义了设置缓存,获取缓存、删除缓存三个方法,但我感觉其中设置、删除缓存方法都很奇怪,设置缓存居然要提供返回值才能实际设置;删除缓存又是一个空的方法体。缓存是通过这种方式使用的吗?我感觉很奇怪 我在 application.yml 中配置了缓存的 cache-names;然后使用 @Cachable 注解IDE还是会提示要提供 name,