《数据驱动封装pages》专题
-
Groovy withBatch(或者JDBC驱动程序)中的Bug?
我有以下更新代码: 当我运行它时,它告诉我:catch:java。sql。BatchUpdateException:不允许将数据类型“VARCHAR”隐式转换为“FLOAT”。使用CONVERT函数运行此查询。 但是,如果我这样做: 它工作没有问题 该参数是一个float,当我调用withBatch时,它似乎试图将null转换为string,但在常规更新中效果良好。 我正在使用赛贝斯和jTDS j
-
Selenium Web驱动程序过时引用异常
我必须点击页面上的某个按钮。但是,当我检索所有具有特定类名的元素时。当我尝试执行每个元素或单击时,所有检索到的元素都会抛出一个过时的引用异常。我不能双击任何一个。它找到了正确的元素,但抛出了所有元素的例外。注释掉的代码就是我试图选择并点击相应按钮的地方。我附上了表格的照片。请注意,每次单击或执行按钮时,页面都会发生更改。选择上传BOM按钮是您需要特别注意的。网站
-
Google驱动器服务帐户配额限制
-
在Glassfish中不调用消息驱动Bean onMessage()
我对JMS编码是新手。我试图从独立的java客户端创建消息,该客户端创建并将消息发送到队列,消息驱动bean用于进一步处理消息。 我使用的是Glassfish应用服务器(3.1)。并设置从独立java客户机创建消息的所有内容。 下面是我的代码:客户端 消息驱动bean: 问题是:没有被调用。我错过什么了吗?请帮帮我.
-
H2-r2dbc-h2驱动程序中的控制台
有人知道为什么吗?我该怎么解决?
-
XPath枚举元素时硒色驱动异常
我正在尝试将一个硒脚本从火狐转换为Chrome。该代码在x86_64上与火狐和壁虎驱动程序一起工作。壁虎驱动程序不支持ARM,所以我试图转移到Chrome。 Chrome和chromedriver在使用。例外是。 问题是什么,我如何解决它? 这是测试程序。 以下是尝试使用Chrome和chrome驱动程序枚举X路径时的异常。 此代码: 应该返回如下内容: 以下是版本号。
-
木偶驱动程序无法到达异常
我正在使用Firefox 47.0.1和木偶驱动程序geckodriver-v0。8.0-win32。但我遇到了无法访问的浏览器异常,无法打开。 我的代码片段如下所示: 将异常显示为:- 组织。openqa。硒。遥远的UnreachableBrowserException:无法启动新会话。可能的原因是远程服务器地址无效或浏览器启动失败。构建信息:版本:'2.53.0',版本:'35ae25b',时
-
消费者驱动的SOAP Web服务合同
你们中有人知道用SOAP web服务实现消费者驱动的契约的方法或工具吗?我有一个发布SOAP web服务的遗留Java应用程序,用Apache CXF实现,由一群Spring Boot Java微服务使用。我已经在使用Pact和Spring Cloud Contract来测试我在微服务之间的REST调用,但是找不到一种方法来使用这些相同的工具或任何其他工具来实现SOAP web服务。
-
.NetStandard 2.0,MongoDB驱动程序:FileNotFoundException for MongoDB。布森
我已经用创建了一个新项目。Net标准2.0,具有以下依赖项: MongoDb.驱动程序 MongoDb.司机。核心 MongoDb.bson 但是,当我运行程序时,会出现以下错误: 未处理的异常:系统。木卫一。FileNotFoundException:无法加载文件或程序集“MongoDB.Bson,Version=2.7.2.0,Culture=neutral,PublicKeyToken=nu
-
mongo csharp驱动程序版本存在问题
我使用mongo csharp驱动程序版本1.9.1。但是,我有这个dll的问题。例外情况是: "无法加载文件或程序集'MongoDB. Bson, Version=1.9.1.221,区域性=中性, PublicKeyToken=f686731cfb9cc103'或其依赖项之一。找到的程序集的清单定义与程序集引用不匹配。(HRESULT的异常: 0x80131040)":"MongoDB. Bs
-
连接到db2 7.1 as400的jdbc驱动程序
我需要使用sqldeveloper连接到db2 7.1 as400系统,使用jdbc驱动程序连接到oracle data integrator。 我下载了db2cc.jar、db2cc_license_cisuz.jar..jt400.jar、db2java.jar。 连接显示成功,并且似乎已连接,但在运行任何查询或浏览任何表时,每次我得到以下错误:
-
Cassandra Batch声明行为-datastax java驱动程序
我想得到一些关于批处理语句执行的澄清。 我在批处理中为不同的表添加了许多insert/update语句。当我执行批处理时,我希望如果任何一个查询失败,所有其他插入/更新都不会成功。但这并没有发生。我可以看到部分更新/插入。 我怎样才能实现这一点?[如果任何一个查询失败,该批的所有更新/插入都不应发生。] 如何获取/打印导致批处理执行失败的确切问题查询? 已记录批处理语句的用途是什么? http:/
-
CassandraJava驱动程序-QueryBuilder API与准备语句
用于cassandra的Datastax Java驱动程序(cassandra-driver-core 2.0.2)支持PreparedStatements以及QueryBuilder API。使用其中一种比另一种有什么特别的优势吗?缺点? 文档:http://www.datastax.com/documentation/developer/java-driver/2.0/common/drive
-
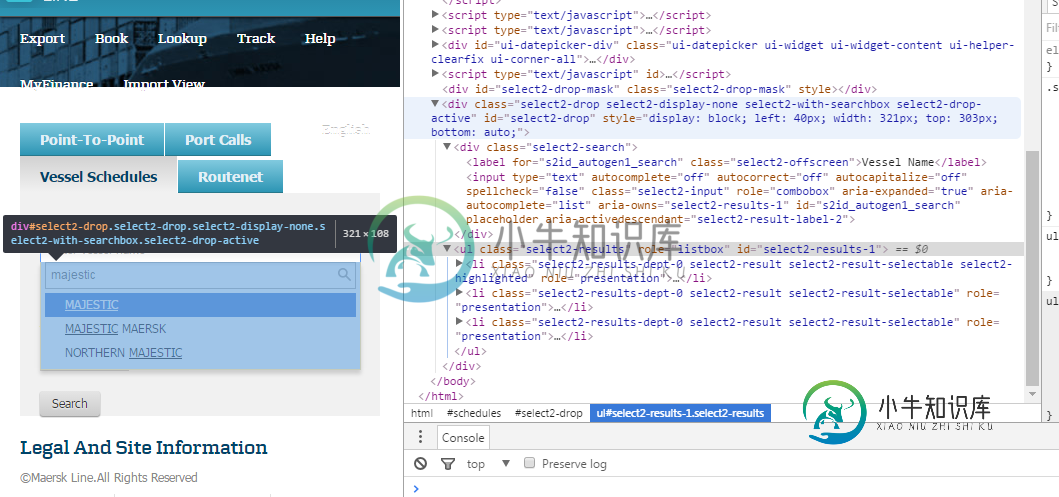 selenium Web驱动程序访问列表框值
selenium Web驱动程序访问列表框值我在使用Selenium web驱动程序访问列表框值时遇到了问题。 我能够粘贴值并传递我想选择的列表的类名,基本上我必须每次选择列表中显示的第一个选项 第6行给我以下错误 任何想法,我怎么能做到这一点?任何需要的信息让我知道。谢谢 更新代码
-
运行网络驱动程序硒在后台
我查了一下,我怎么能默默地运行硒:在这里找到了下一个伟大的答案 我正在尝试让selenium正常运行,直到一些操作完成,然后在后台运行它。 有可能吗? 高级Oz中的thanx