《提前批真的不会影响正式批吗》专题
-
 中国工商银行杭州软件开发中心提前批面试
中国工商银行杭州软件开发中心提前批面试线下面 时间大概十五分钟,不是群面,一对二;一个组里的一个个进; 进去自我介绍,然后让挑一个项目来讲 怎么做的性能优化 讲vue2和vue3的区别 为什么选杭州? 信息:前端岗位很少,后端为主(麻了)
-
 重庆京东方提前批产品开发研究员1面记录
重庆京东方提前批产品开发研究员1面记录7.17号投递简历并测评 7.19号中午面试 三个人一组,依次面试,每个人平均10来分钟 1、自我介绍 2、问家乡? 3、在这之前面试过其他企业没? 4、你的项目经历偏软件,可以谈谈你的个人职业规划吗? 5、项目中最大的难点是啥? 6、薪酬最低接受多少?(这个可以提前了解下,感觉我说少了); 反问? 1:接下来流程是啥? 2、技术面大概会面什么内容? 3、后期岗位是按照投递定还是贵公司回调? 4、
-
 百度提前批安卓一面凉经,把面试官都菜哭了
百度提前批安卓一面凉经,把面试官都菜哭了自我介绍 项目里面碰到的困难,怎么解决的。 问了问安卓行业的发展前景,简历里面写了后端的项目,怎么来面试安卓的岗位。 问了git:rebase和merge的区别 计算机网络: TCP,UDP的区别,TCP流量控制和拥塞控制 TCP为什么要三次握手,为什么两次不行。 java: AOP和ioc的区别,说说理解 什么事动态代理,动态代理解决了什么样的问题,好处是什么 代码: 手写快排, 二叉树层序遍历
-
 字节跳动后端开发工程师-Data提前批一二面(凉)
字节跳动后端开发工程师-Data提前批一二面(凉)字节跳动后端开发工程师-Data-抖音/直播/电商/剪映-24提前批一面 自我介绍 项目,qps 怎么测的 epoll 的实现原理? 同步异步阻塞非阻塞IO?epoll是什么IO?了解过哪些异步IO 跳表?具体结构怎么实现的,用红黑树可以吗? redis 数据类型? 如何用 redis 实现阻塞队列、延时队列? redis 持久化怎么做的? 如果 AOF 命令还没写入就宕机了用户还能获取到吗 My
-
 百度测开提前批一面二面三面(回忆版),进池子
百度测开提前批一面二面三面(回忆版),进池子百度二进宫,三面已过。 第一个部门: 一面8.2(1小时左右) 自我介绍 项目介绍及难点 计网,网页请求过程(在浏览器中输入www.baidu.com后执行的全部过程) TCP三次握手、四次挥手,为什么要四次 JavaSE相关问题 JVM的内存溢出情况分析(堆和栈) JVM运行时数据区 Redis缓存穿透、缓存击穿、缓存雪崩及解决办法 Redis数据一致性 MySQL索引,及设计原则 还有些八股忘
-
 百度提前批文心一言二面 科大讯飞飞星一面
百度提前批文心一言二面 科大讯飞飞星一面很怪的两场面试。。。。 百度提前批 文心一言 二面 1.主要就是拷打实习 2.过程中出来几道场景题 a. 如何利用大模型本身相关的方法,指标去判断数据,筛选数据(答了看ppl 巴拉巴拉) b. 如何扩展闭源的benchmark,或者如何从大量的指令数据里面提取能力项,构建扩展已有的benchmark(我其实不是很理解这个问题,说了一下deepseekmath的数据流程,艹) c. DPO的原始数据
-
 8月1日南京银行金融科技提前批笔试复盘
8月1日南京银行金融科技提前批笔试复盘双机位监考,时间巨长,题目类型巨多,题目也比较怪 总共2个半小时,五部分,一二部分性格测试,三四是标准的行测题目,计算和找图形相似。最奇怪的就是第五部分,一整个缝合怪,啥题目都有。 第五部分,前面一大半都是计算机专业基础题,包括SprinBoot,Linux,数据库。甚至我以为时间给的太充分了,直到我做到最后几题。 先是论述题,结合专业分析金融科技的趋势 接着编程题,难度不难,把物理题和编程题结合
-
如何正确批量报告退出状态?
问题内容: 我面临一种奇怪的情况,即我编写的批处理文件报告了错误的退出状态。这是重现该问题的最小示例: 如果我运行此脚本(使用Python,但是当以其他方式启动时实际上也会出现问题),这是我得到的: 注意如何报告,即使应该如此。 现在很奇怪的是,如果我删除了inner子句(这没关系,因为之后的所有内容都不应该执行),然后尝试启动它: 我再次启动它: 现在正确地报告为。 我不知道是什么原因造成的
-
JDBC插入批处理在SqlServer和Oracle上的工作方式不同
我正在尝试在SqlServer和Oracle上进行批量插入,并在以下测试代码中实现: } 该代码将数据插入到具有主键ID和时间戳的Tester表中。 我想做的是以这样一种方式插入数据库:即使批处理中的一些数据已经存在,也会插入不存在的数据,因为违反了主键约束,所以会抛出BatchUpdateException。 我正在测试一个有50000个条目的批次,其中50%已经在数据库中。 使用SqlServ
-
Spring批处理:忽略与指定模式不匹配的任何行
这是我的明显错误,我没有任何映射的TREX,*jamend,EOF模式。因此,它抛出以下异常: 我看了许多例子,这一个匹配接近,并改变了我的步骤如下,但仍然是同样的问题。 查看这里的Spring.io文档中的跳过记录(5.1.5配置跳过逻辑),也不起作用。 请让我知道绕过这个问题的理想方法。难道不应该有一种简单的方法来指定不匹配特定情况的跳过记录吗?请指教。谢了。 --- 我有一个'*'的模式映射
-
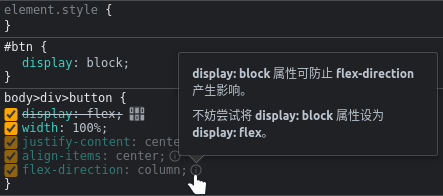 前端 - 为什么设置了块布局 flex-direction 依然影响样式?
前端 - 为什么设置了块布局 flex-direction 依然影响样式?为什么这里的 flex-direction 和 align-item 还有效 firefox 上一切正常 jsfiddle 浏览器信息: Vivaldi 6.2.3105.58 (Stable channel) stable (64 位) Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/11
-
通用批处理模式 - 基于ItemReaders的driving query
11.4 基于ItemReaders的driving query 在readers 和writers章节中对数据库分页进行了讨论,很多数据库厂商,比如DB2,如果读表也需要使用的在线应用程序的其他部分,悲观锁策略,可能会导致问题.此外,打开游标在超大数据集可能导致某些供应商的问题.因此,许多项目更喜欢使用一个’Driving Query’的方式读入数据.这种方法是通过遍历keys,而不是整个对象,
-
对于FindBugs,应该优先于jar305.jar中的批注而不是那些notification.jar中的类似批注吗?
问题内容: 在FindBugs的分布,annotations.jar是不是的一个子集jsr305.jar。但是,几个注释似乎重复了(精确地或非常接近地)。如果我可以选择的话,jsr305.jar是否应该选择注释? 请注意,我不只是想知道,使用注释来“更好”jsr305.jar是因为它们只是代表一种标准,因此“不仅仅是”。相反,我想知道如果我更喜欢jsr305.jar特定注释的版本,FindBugs
-
range()真的会创建列表吗?
我的教授和这个家伙都声称范围创建了一个值列表。 注意:range函数只返回一个包含从x到y-1的数字的列表。例如,range(5,10)返回列表[5,6,7,8,9] 我认为这是不准确的,因为: 此外,访问由范围创建的整数的唯一明显方法是遍历它们,这使我相信将范围标记为列表是不正确的。
-
 猿辅导第二批前端笔试8.26
猿辅导第二批前端笔试8.26题型:选择(15*3)+编程(30+30+40)=总分145,时间90分钟 选择题 前端不友好型,偏数据库计网操作系统,咔咔一顿乱做 编程题第一题:公共哈希值(100%) 题目大意:找到不同测试脚本公共哈希值 输入:第一行n为测试用例数量,每个测试用例包含:m脚本文件数量,剩余m行表示各个脚本文件哈希值,哈希值有多个且没排序,可能有重复 输出:按照字典顺序[划重点!!!]返回共有的哈希值字符串,多