《我的记录》专题
-
SQL:递归选择所有子记录的SUM
问题内容: 我有一张桌子,桌子之间有一对多的关系。每个记录可以有来自同一张表的n个孩子。例如 给定一个ID,我想递归选择所有文件夹记录的SUM(SIZE)。目标数据库是MySql 5,但是如果它的通用性足以在Oracle和MS- SQL中运行,那将是很好的选择。 我不知道树有多深,可能是1级,可能是50级(或更多) 问题答案: 这可能会有些帮助:http : //mikehillyer.com/a
-
在MySQL中仅选择唯一的行/记录
问题内容: 我想看看如何只获得具有唯一城市的唯一行/记录,而不关心是否是首都,例如: 只会返回一条记录。 我累了像这样的东西,但是没用 谢谢… 问题答案: 您可以使用以下仅用于mysql的技巧: 这将返回 遇到的第一行 的每个独特的价值和。 其他数据库将抱怨您的分组依据中未列出未聚合的列或此类消息。 已编辑 以前我声称不使用分组列上的函数将返回所有大小写的变化,但这是不正确的- 感谢SalmanA
-
ASP获取新增记录ID值的方法
本文向大家介绍ASP获取新增记录ID值的方法,包括了ASP获取新增记录ID值的方法的使用技巧和注意事项,需要的朋友参考一下 ASP+Access2000 1.要获取的ID值字段属性必须设为:自动编号(我们假设字段名为recordID) 2.添加记录格式:Rs.Open table,Cn,1,3 注意模式为:1,3 3.newID = rs.Fields("recordID") 4.newID为刚添
-
查找符合特定条件的记录组
问题内容: 我有以下数据: 对于每组记录(按ParentID分组),我想查找所有没有包含“ A”作为数据值的记录的组。 由于第1组和第6组确实包含至少一个以“ A”作为数据值的记录,因此我不希望看到它们。我只想查看记录4和5(它们是组4的一部分),因为该组中没有记录带有“ A”。 任何帮助是极大的赞赏! 问题答案: 如果表很大,建议建立索引。
-
使用Python(django)的AWS Elastic Beanstalk日志记录
问题内容: 你如何在AWS Elastic beantalk中管理应用程序日志?我的意思是你将应用程序日志写入哪个文件?我在开发环境中使用以下日志记录配置,但是当我在AWS中部署时,此配置不起作用。 提前致谢! 问题答案: 首先,我通过ssh连接到ec2机器,然后以root用户在/ var / log中创建一个名为app_logs的文件夹: 之后,我执行以下操作: 这样可以确保在此文件夹中创建的所
-
Spring Cloud Sleuth的Spring AOP记录器跟踪ID?
我有一些微服务作为分布式日志管理器与Spring Cloud Sleuth一起运行。对于一些微服务,还包括Spring AOP,主要是关于方法执行时间日志的建议(下面的代码)。 现在,我可能在这里错过了AOP点,并且不太明白建议何时真正生效,但是否有可能将Sleuth跟踪ID包含在从定义的类生成的日志中? 代码: 方面类(从组织aspectj和组织slf4j导入): Spring Boot版本为2
-
Scrapy:日志记录到没有ScrapyFileLogObserver()的文件
显然,我不应该再使用ScrapyFileLogObserver(http://doc.scraphy.org/en/1.0/topics/logging.html)。但是我仍然希望能够将我的日志消息保存到一个文件中,并且我仍然希望将所有标准的不稳定的控制台信息也保存到该文件中。 通过阅读如何使用日志模块,下面是我尝试使用的代码: 它运行良好,并将“某些东西”保存到文件中。但是,我在命令提示符窗口中
-
用于链接记录的MongoDB集合设计
我有一个“name”集合,当我执行POST调用时,我会搜索数据库中是否有与SSN匹配的记录,并创建一个具有相同name_id的记录,基本上是为了链接具有相同SSN的记录。 同时,我将为每个记录创建NameDetails。 它的目的是,当我通过SSN执行GET调用时,它应该从Name collection及其相应的NameDetails中获取所有具有匹配SSN的记录。 NameDetails集合:{
-
Python CPLEX记录了可行的解决方案
我想知道如何在Python CPLEX API中使用MIP回调来记录可行的解决方案。目前我的cplex模型可以运行10个小时,看起来客观值一点也没有提高,但是我不能中途停下来,因为数据会丢失,所以我想知道如何在MILP问题中使用回调来记录可行的解决方案 编辑:我没有用docplex,我用的是cplex
-
是否需要重写记录的hashCode()和equals()?
假设以下示例:
-
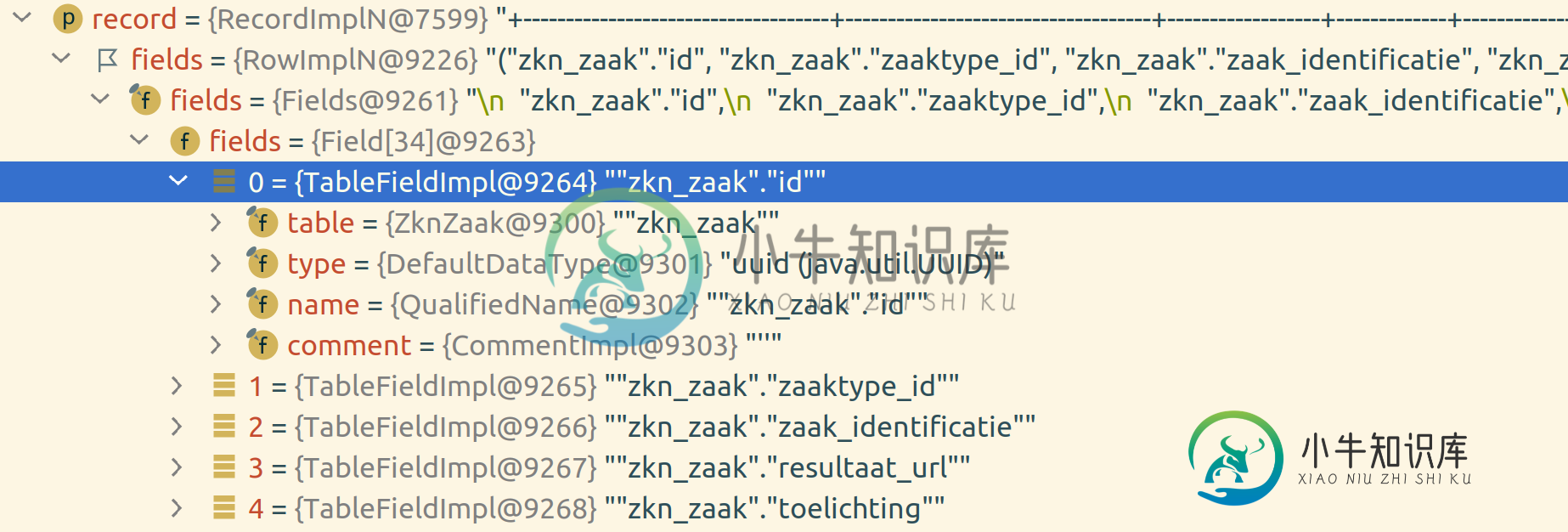 jOOQ从记录中返回错误的列值
jOOQ从记录中返回错误的列值我有以下记录是通过一个带有几个连接的查询得到的: 现在,当我尝试检索不在结果中的特定列时: 其中生成具有以下详细信息的静态编程语言代码: 我希望得到null。但是,返回了错误的id值(zkn_zaak.id)。 我错过了什么?jOOQ不应该有足够的信息(表和字段名)来从记录中检索正确的列吗? =======更新============= 从代码来看,这似乎是预期的行为,并且已经在例如。https:
-
使用Mapstruct作为JOOQ的记录映射器
我想实现我自己的并使用Mapstruct将记录映射到POJO。我不太明白如何完成这一点。我遵循了这部分文档:https://www.jooq.org/doc/3.13/manual/sql-execution/fetching/pojos-with-recordmapper-provider/ 我的映射器看起来像这样: 问题是,作为我实际上并没有得到,而是我的语言表中的,因此无法将转换为。知道我需
-
父类中的Slf4j记录器日志字段
我有以下代码: 在日志中,我只能看到来自BClass而不是AClass的字段: 17:52:28.151[main]INFO Main-Main. BClass(金额=12) 但是我想查看所有BClass字段,包括父类中的字段(标题字段)。我该怎么做?
-
使用spark avro跳过记录中的字段
更新:spark avro软件包已更新以支持此场景。https://github.com/databricks/spark-avro/releases/tag/v3.1.0 我有一个AVRO文件,它是由我无法控制的第三方创建的,我需要使用spark进行处理。AVRO模式是一个记录,其中一个字段是混合联合类型: 这是不支持的火花avro阅读器: 除了上面列出的类型之外,它还支持读取三种类型的联合类型
-
所有记录的DynamoDB流触发器调用
我试图从DynamoDB表中设置ElasticSearch导入过程。我已经创建了AWS Lambda并启用了带有触发器的DynamoDB流,该触发器为每个添加/更新的记录调用我的Lambda。现在我想执行初始种子操作(将DynamoDB表中当前的所有记录导入ElasticSearch)。我该怎么做?有没有办法让表中的所有记录都“重新处理”并添加到流中(这样我的lambda就可以处理它们)?还是最好