《工作压力大怎么缓解》专题
-
使用Zappa部署lambda时出错:调用UpdateFunctionCode操作时:解压缩大小必须小于262144000字节
当我尝试使用Zappa上传到AWS Lambda时,收到错误消息“解压缩大小必须小于262144000字节”。在阅读之前的一个线程时,我被告知需要添加:“slim_handler”:true以处理zappa_设置中大于50MB的文件。json,但添加后我得到了OSError:Pypi查找失败。请让我知道如何解决此问题? 添加“slim_处理程序”后出错:true-- 回溯(最近一次调用):hand
-
你知道什么是锚点吗?它的作用是什么?怎么创建一个锚点?
本文向大家介绍你知道什么是锚点吗?它的作用是什么?怎么创建一个锚点?相关面试题,主要包含被问及你知道什么是锚点吗?它的作用是什么?怎么创建一个锚点?时的应答技巧和注意事项,需要的朋友参考一下 这里name="ss" 的a标签、id="ss" 的任意标签都是锚点,简单创建用id就可以,绝大多数标签又可以有id属性,而name仅在a标签中才可以作为锚点
-
如何在Golang的字节缓冲区中解压缩各种形式的整数?
问题内容: 我需要提取字节缓冲区中的各个字段。我想出了以下解决方案: 有没有更好/惯用/直接的方法呢? 我想让偏移量保持明确 我想从字节缓冲区中读取,而不是在可能的情况下从文件中查找和读取。 问题答案: 通过使用跳过不想读取的字节,可以避免每次创建新缓冲区: 或者,您可以避免逐块阅读,而创建一个标头结构,您可以使用以下方法直接读取它:
-
 利用 Linq+Jquery+Ajax 实现异步分页功能可简化带宽压力
利用 Linq+Jquery+Ajax 实现异步分页功能可简化带宽压力本文向大家介绍利用 Linq+Jquery+Ajax 实现异步分页功能可简化带宽压力,包括了利用 Linq+Jquery+Ajax 实现异步分页功能可简化带宽压力的使用技巧和注意事项,需要的朋友参考一下 在Web显示的时候我们经常会遇到分页显示,而网上的分页方法甚多,但都太过于消耗带宽,所以我想到了用Ajax来分页,利用返回的Json来处理返回的数据,大大简化了带宽的压力。先说下思路,无非就是异步
-
用Jmeter对Keycloak进行压力测试,结果是CPU使用率达到100%
用Jmeter对Keycloak进行压力测试,结果是100%的CPU使用率。
-
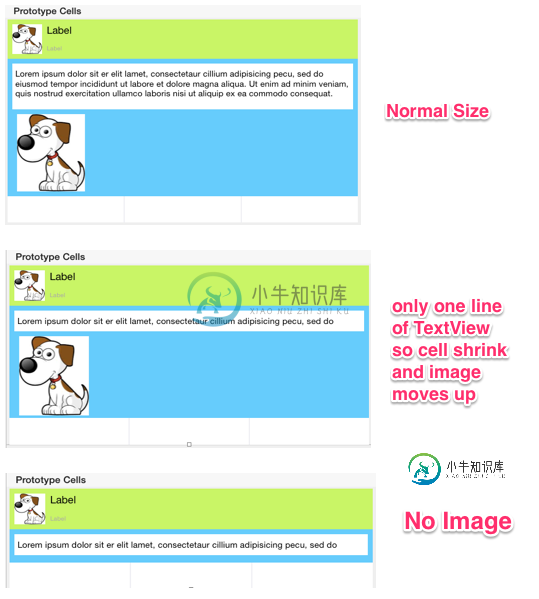 内容拥抱和内容压缩阻力、自动布局限制的问题
内容拥抱和内容压缩阻力、自动布局限制的问题我已经修改了问题,以提供更多的信息和明确。< br > 我想有一个动态的表格视图单元格,具有UITextView的灵活高度和可选的UIImageView。根据UITextView和可选的UIImageView的内容大小,可以收缩或扩展单元格。 这是我所期望的(如下图所示): 正常大小:文本视图的高度是固定的(例如77)。图像视图宽度和高度也是固定的(例如130,130) 当文本视图的内容大小减小时
-
Spring缓存驱逐不起作用
嗨,我在执行方法时遇到清理缓存的问题。这是我的配置和缓存方法: 我要缓存的这个方法: 在执行此方法时,我希望按类型清理缓存: 新闻消息对象看起来像: 缓存工作正常,第一次查询DB时,第二次从缓存中提取数据。问题是当我更新数据时,@CacheEvict不会清理缓存。我试图使用以下注释清理所有缓存:@cacheexit(cacheNames={CacheConfiguration.RSS\u NEWS
-
在C语言中,完全缓冲,行缓冲和非缓冲是什么意思?
问题内容: 我碰到一行,命令的输出已完全缓冲。这是什么意思? 问题答案: 在线C11标准 7.21.3 / 3: 当流没有 缓冲时 ,字符应尽快从源或目标出现。否则,字符可能会作为块被累积并传输到主机环境或从主机环境传输。当流被 完全缓冲时 ,打算在填充缓冲区时将字符作为块与主机环境进行传输。当流被 行缓冲时 ,当遇到换行符时,字符打算作为块与主机环境进行传输。此外,当填充缓冲区,在无缓冲流上请求
-
压缩
Tango拥有一个默认的压缩中间件,可以按照扩展名来进行文件的压缩。同时,你也可以要求某个Action自动或强制使用某种压缩。比如: type CompressExample struct { tango.Compress // 添加这个匿名结构体,要求这个结构体的方法进行自动检测压缩 } func (CompressExample) Get() string { return f
-
压测
前言 几乎所有的框架、模块、类库, 都会把高性能作为最重要的标签之一(当然, braft也不例外)。但是常常开发者对于性能理解只是停留在吞吐或者QPS的数字表面,性能测试变成了想方设法刷数字的游戏,而不考虑场景是否符合实际应用场景。常见的『提升性能数字』的方法有以下两类: Batch: 系统主动等request数量达到一定数量或者等一个超时时间, 合成一个request发给后端系统, 取决于bat
-
压缩
所有基于http协议的服务器组件均支持压缩,请求头Accept-Encoding的值需要包含deflate或者gzip。 即便请求头Accept-Encoding的值包含deflate或者gzip,服务器还会参考静态变量http_server::zip_min_size(默认1024,即1KB)和http_server::zip_max_size(默认307200,即300KB)来决定是否压缩:仅
-
zlib deflate:为什么它会积累短数据,直到输入缓冲区满了才开始压缩?
在zlib的deflate实现中,注意到当给定的数据长度较小时,zlib函数会将数据复制到输入缓冲区,只有当输入缓冲区满时才开始压缩。 当给定的数据长度大于输入缓冲区大小时,zlib函数直接开始压缩。 我想知道将短数据积累到输入缓冲区中有什么好处。我能想到的是: 避免花费在块处理上的开销,包括Huffman树初始化和CRC caculation 保持I/O工作在8KB(或更大)块上,有利于提高性能
-
在apache Camel中压缩和解压缩一个大文件,而不将整个文件加载到内存中
我们使用Apache Camel来压缩和解压缩我们的文件。我们使用标准的和API。 我们的问题是,当我们得到非常大的文件(例如800MB到1GB以上的文件大小)时,我们的应用程序将耗尽内存,因为整个文件被加载到内存中进行压缩和解压缩。 是否有任何骆驼API或java库可以帮助压缩/解压缩文件,而不需要将整个文件加载到内存中。 这里还有一个类似的未解问题
-
手写代码:怎么判断链表有环,怎么找环节点?
本文向大家介绍手写代码:怎么判断链表有环,怎么找环节点?相关面试题,主要包含被问及手写代码:怎么判断链表有环,怎么找环节点?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 判断是否有环以及环节点
-
7.4 Git 工具 - 签署工作
Git 虽然是密码级安全的,但它不是万无一失的。 如果你从因特网上的其他人那里拿取工作,并且想要验证提交是不是真正地来自于可信来源,Git 提供了几种通过 GPG 来签署和验证工作的方式。 GPG 介绍 首先,在开始签名之前你需要先配置 GPG 并安装个人密钥。 $ gpg --list-keys /Users/schacon/.gnupg/pubring.gpg ----------------