《工作压力大怎么缓解》专题
-
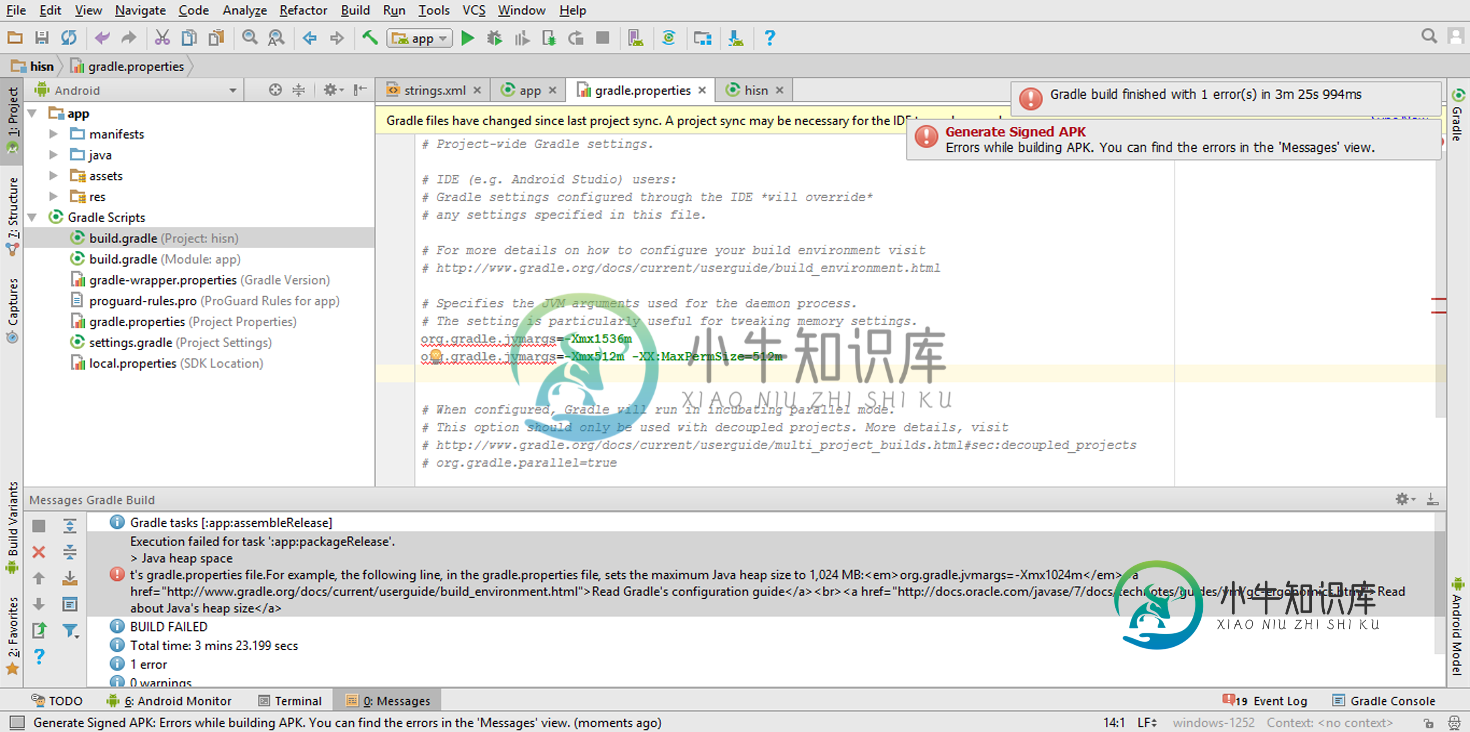 如何解决Java的堆大小问题在android工作室
如何解决Java的堆大小问题在android工作室我完成了一个Android应用程序,当我尝试生成APK文件时,它显示我将Java的堆大小设置为1024m,我这样做了,但我仍然得到相同的错误。这是错误消息和gradle.proprities的截图e:: 我在等你的帮助!提前感谢
-
“最大打开文件数”用于工作流程
问题内容: 是否可以为工作过程增加“最大打开文件数”参数?我的意思是这个参数: 感谢您的建议 问题答案: 作为系统管理员 :在大多数Linux安装中,此文件控制此文件;它允许您设置每个用户的限制。您需要一条像这样的线。 在一个进程内 :getrlimit和setrlimit调用控制大多数每个进程的资源分配限制。控制文件描述符的最大数量。您将需要适当的权限才能调用它。
-
VSCode-Python大纲视图为Python在VSCodeLinux不工作
在Ubuntu上运行VSCode 16.04.3 VSCode版本:1.26.1 Microsoft Python扩展:2018.7.1 当我查看python文件时,大纲视图显示在文档中找不到符号。Windows上VSCode中的同一文件显示所有符号 有帮助吗?
-
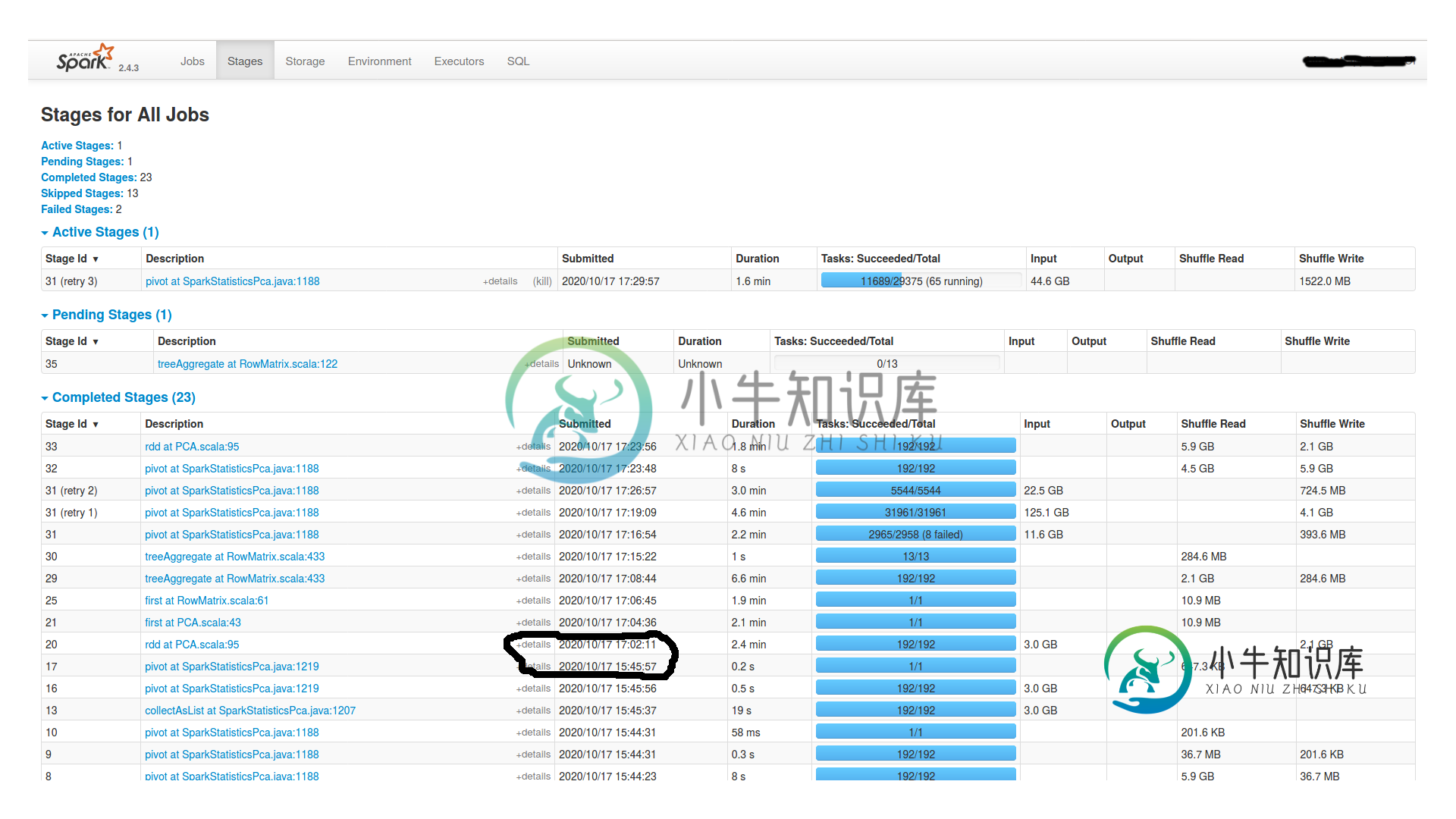 火花工作之间的巨大时间间隔
火花工作之间的巨大时间间隔我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
Tomcat 7-无法使CATALINA_OPTS堆大小正常工作
我在catalina.sh中设置CATALINA_OPTS,但奇怪的是,这个值似乎被忽略了。我在一台有768M内存的机器上。以下是复制的步骤 在启动Tomcat之前,我通过运行检查内存。我得到以下信息 我在catalina.sh的第一行设置了CATALINA_OPTS,如下所示: 这表明使用了512MB。我不确定我做错了什么。我还尝试设置JAVA_OPTS,但也不起作用。 我在Centos6上使用
-
如何在Talend大数据工作中迭代tHiveInput?
有没有一种方法可以在talend大数据工作中迭代一个TiveInput?
-
COPY如何工作,为什么它比INSERT这么快?
问题内容: 今天,我整天都在改善Python脚本的性能,该脚本将数据推送到Postgres数据库中。我以前是这样插入记录的: 然后,我重新编写了脚本,以使它创建的内存文件比Postgres命令所使用的内存文件大,这使我可以将数据从文件复制到表中: 该方法 惊人地更快 。 但是我找不到关于为什么的任何信息?它与多行的工作方式有何不同,从而使其变得更快? 也请参阅此基准测试: 问题答案: 这里有许多因
-
java - 怎么根据计划周期定时生成工单, 求解答?
怎么根据计划周期定时生成工单,当计划开始根据选择的周期,如立即执行一次,每天执行一次,每月执行一次。 最好可以指定每天几点,每月几号执行
-
使用设置上载\u最大\u文件大小。htaccess不工作
我想用我的. htaccess将upload_max_filesize设置为3G(或最大值),因为我无法访问php.ini.我做了很多研究,这就是我现在得到的: .htaccess: 但不知怎么的,这对我不起作用。当我加上 对于我的PHP脚本,我只得到这样的响应: 当我使用而不是时,我得到一个500内部服务器错误 那么我做错了什么<提前谢谢! 编辑/解决方案:我使用的是一个共享托管服务,它不允许我
-
什么是耦合和凝聚力?
本文向大家介绍什么是耦合和凝聚力?相关面试题,主要包含被问及什么是耦合和凝聚力?时的应答技巧和注意事项,需要的朋友参考一下 组件之间依赖关系强度的度量被认为是耦合。一个好的设计总是被认为具有高内聚力和低耦合性。 面试官经常会问起凝聚力。它也是另一个测量单位。更像是一个模块内部的元素保持结合的程度。 必须记住,设计微服务的一个重要关键是低耦合和高内聚的组合。当低耦合时,服务对其他服务的依赖很少。这样
-
为什么看不到热力图
使用指南 - 疑难问题 - 数据缺失或无数据问题 - 为什么看不到热力图 设置热力图的页面上边没有正确添加当前站点的统计代码 网站有跳转,但是热力图上边设置的监控网址是跳转之前的,请用跳转之后的网址设置; 注意查看时间,热力图是隔一天后才有数据的; 偶尔浏览器的显示存在问题,请将页面设置为100%大小,并作刷新处理,且建议使用Chrome和Firefox浏览器。 页面上添加了禁止iframe加载的
-
NotNull不工作,列(nullable=false)工作
我有一个Spring实体,其中有一个用javax.validation.constraints中的@NotNull注释的字段 问题是,如果为name字段设置了空值,则将其存储在数据库中。但是,如果我按以下方式更改类,它会引发我想要接收的异常: ApplicationContext-JPA 由于我使用的是存储库,因此我还报告了corrisponding实体存储库:
-
工作非工作Hibernate Derby错误
我有一个非常简单的实体,其注释与我在将其添加到项目之前使用的注释完全相同。在添加FK constaint时,我得到下面显示的堆栈跟踪,也有未显示的堆栈跟踪。无论我是使用原语还是对象作为索引,都会发生错误。一切似乎都是对的,有人能启发我吗?泰。 组织。冬眠工具架构。spi。CommandAcceptanceException:通过org上的JDBC语句执行DDL“create table user(
-
使用JMeter进行负载测试、压力测试、容量测试
嗨,我是JMeter的新手,我知道如何使用JMeter执行负载测试。我试图弄清楚压力测试或容量测试是如何通过JMeter执行的。是不是通过逐渐增加JMeter中的线程数,我们可以确定何时出现性能问题,并获得阈值,在阈值以上运行测试。那它会做压力测试吗? 在如何执行压力测试和能力测试与Jeter工具混淆。
-
如何对现有的linux应用程序进行压力测试
我有一个带有linux平台的嵌入式系统,我想对每个应用程序执行压力测试和负载测试。我该怎么做? 如果我使用任何bash脚本(如下面的链接)或压力工具,它会增加系统的负载,而不是单个应用程序的负载 如何使用bash命令创建CPU峰值 让我知道我如何能在单个应用程序上实现。