《饿了么》专题
-
了解DockerFile中的“ VOLUME”指令
问题内容: 以下是我的“ Dockerfile”的内容 在此文件中,我期望“ VOLUME。/ usr / src / app”指令将主机上当前工作目录的内容安装在要安装在容器的/ usr / src / app文件夹中的主机中。 请让我知道这是正确的方法吗? 问题答案: 官方Docker教程说: 数据卷是一个或多个容器中的一个特别指定的目录,绕过联合文件系统。数据量为持久性数据或共享数据提供了几
-
Hazelcast忽略了群集配置
我定义了“静态”hazelcast配置: 其中“10.0.0.2”是我的localhostip。我只希望将hazelcast的一个实例添加到我的tcpIpConfig成员中。我的朋友坐在同一个网络中,拥有编号为“10.0.0.3”的IP。他懒得从git上共享的属性文件中更改密码和组名,并且正在连接到我的集群。为什么他能够连接到我的集群?我如何防止这种情况?
-
Spring Boot@SpringBootTest给出了noClassDefFounderRor:…DataAccessException
原因:org.springframework.beans.beanInstantiationException:无法实例化[org.springframework.boot.web.servlet.FilterRegistrationBean]:工厂方法“Createyadayada Filter”引发异常;嵌套异常是org.springframework.beans.factory.beanDe
-
倒数计时器落后了
我正在尝试在两个日期之间创建倒计时,但时间过了一段时间就落后了。 我的PHP后端返回当前时间和未来X时间之间的差值,例如当前时间和提前2小时。这个差异在类,格式如下,我使用javascript函数对差异进行倒计时。以下是我的功能: 代码按预期工作,但几分钟后,比方说2-3分钟,如果您刷新页面或在新窗口中打开它,您将看到倒计时计时器落后秒/分钟。有人知道我做错了什么吗?
-
了解注释和JPA(休眠)
问题内容: 有一个结构。我想以这种方式链接这三个实体:公司应包含ID,公司名称和部门列表,每个部门都有一个工人列表,ID和部门名称。每个工人都有名字,身份证。 我试图与一对多和多对一建立联系,但未成功。 公司 部门 工人 我从开始: 它填充公司,但不填充其他表,也没有创建任何联接(映射)错误: 问题答案: 除了Glenn Lane的答案中提到的级联,您还需要了解双向关联是如何工作的。 它们有一个所
-
确保正确设置了JAVA_HOME
问题内容: Java和Mac都相当新。我想确保已设置JAVA_HOME,以便在其他程序中可以使用其路径。所以我做了一些谷歌搜索,这就是我得到的: 如果我在终端中输入 / usr / libexec / java_home ,则得到此信息: /System/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Home 但如果在终端中输入 echo
-
了解Spring Data JPA @NoRepositoryBean接口
问题内容: 在阅读Spring Data文档时,我多次遇到该界面。 引用文档: 如果您按原样使用通过接口使用Spring命名空间的自动存储库接口检测,将导致Spring尝试创建MyRepository实例。当然这是不希望的,因为它仅充当存储库和您要为每个实体定义的实际存储库接口之间的中介。要排除扩展存储库的接口被实例化为存储库实例,请使用注释。 但是,我仍然不确定何时何地使用它。有人可以建议并给我
-
ForkJoinPool似乎浪费了线程
问题内容: 我正在比较测试程序上的两个变体。两者都在具有四个内核的计算机上以4线程运行。 在“模式1”下,我非常类似于执行程序服务来使用池。我把一堆任务扔了进去。与普通的固定线程执行器服务相比,我获得了更好的性能(即使有对Lucene的调用,该调用在其中执行了一些I / O)。 这里没有分而治之。从字面上看,我知道 在“模式2”中,我向池提交一个任务,然后在该任务中调用ForkJoinTask.i
-
SQLite自然联接坏了吗?
问题内容: 我只是逐渐了解NATURAL JOIN,而SQLite却表现不佳。 和 产生相同(正确)的结果。 但是,如果我省略括号,如下所示: 我看到r1和r2正确连接,但是r3根本没有连接到结果,而是形成了r1 NATURAL JOIN r2,r3的笛卡尔积。 第一个联接结果的属性名称是否存在问题,或者我误解了SQL? 问题答案: 我自己没有使用该数据库,但是根据此文档,SQLite中的所有联接
-
PostgreSQL中的Alter Table太慢了
问题内容: 我正在尝试添加新列 到此表: 但是查询从未完成,我已经等了5分钟,什么也没发生。该表只有5,000条记录,由于它阻止了对该表的访问,我迫不及待地等待了太多时间。我有一个测试数据库(等于生产版本),并且工作非常迅速。postgres版本是9.5.6。 问题答案: 如果您运行的是PostgreSQL 9.6+,则可以用来查找锁定您的查询的PID。
-
Liferay启动时间太长了
我是新的Liferay开发,我面临的麻烦与启动我的Liferay Tomcat服务器。它几乎需要3分钟(169048毫秒),这对于开发来说是不可接受的。我想把它压缩到一分钟左右。 以下是我的机器的规格: 英特尔酷睿双核T2300@1.66 GHz 4GB RAM(使用中3.24GB) 带有Service Pack 1Windows 7 Enterprise 32位 我正在使用: Liferay 6
-
安装tensorflow gpu破坏了tensorflow
我通过anaconda使用tensorflow cpu,在使用命令之后 gpu安装 我收到以下错误信息 File"",第1行,在runfile('C:/用户/g/桌面/大师-项目/高斯ROC示例/神经网络工作Example.py',wdir='C:/用户/g/桌面/大师-项目/高斯ROC示例') 文件“C:\ProgramData\Anaconda3\lib\site packages\spyde
-
了解服务器端的websockets
在客户端,使用“new WebSocket('ws:/blahlah')”创建新的套接字处理程序 然后使用onOpen()方法就知道我们已连接到WS服务器 使用onMessage()方法,已知已从WS服务器接收到消息 onClose()方法指示套接字连接已关闭 所以从客户的角度来看是很清楚的。但是从服务器的角度来看,流程是如何进行的(就像上面的客户端一样),websocket服务器进程的确切含义是
-
了解Eureka客户端缓存
我需要一些帮助来理解为什么在Eureka注册的服务会想要彼此通信,尽管没有实际运行。例如,我在尤里卡注册了服务A和服务B。如果我搞垮了服务B,那么即使服务A没有运行,它仍然会尝试与服务B进行30秒到3分钟的通信。这样做的目的是什么?有什么办法可以绕过它吗?谢谢你!
-
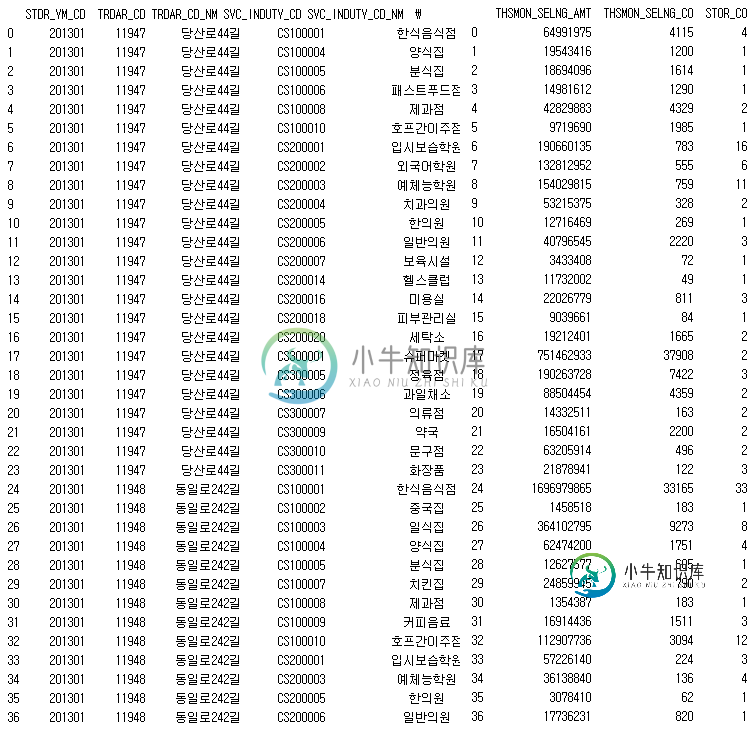 我丢失了列中的值
我丢失了列中的值我用熊猫组织了我的数据。我像下面这样填写我的程序 当我打印df2时,我可以在TRDAR_CD列中看到11947和11948值。如下图所示 之后,我使用了groupby函数,并丢失了TRDAR_CD列中的11948个值。你可以在下图中看到这种情况 TRDAR_CD_NM 1085428非空对象 SVC_INDUTY_CD 1089023非空对象 SVC_INDUTY_CD_NM 1089023非空对