
我丢失了列中的值

我用熊猫组织了我的数据。我像下面这样填写我的程序
import pandas as pd
import numpy as np
df1 = pd.read_table(r'E:\빅데이터 캠퍼스\골목상권 프로파일링 - 서울 열린데이터 광장 3.초기-16년5월분1\17.상권-추정매출\201301-201605\tbsm_trdar_selng.txt\tbsm_trdar_selng_utf8.txt' , sep='|' ,header=None
,dtype = { '0' : pd.np.int})
df1 = df1.replace('201301', int(201301))
df2 = df1[[0 ,1, 2, 3 ,4, 11,12 ,82 ]]
df2_rename = df2.columns = ['STDR_YM_CD', 'TRDAR_CD', 'TRDAR_CD_NM', 'SVC_INDUTY_CD', 'SVC_INDUTY_CD_NM', 'THSMON_SELNG_AMT', 'THSMON_SELNG_CO', 'STOR_CO' ]
print(df2.head(40))
df3_groupby = df2.groupby(['STDR_YM_CD', 'TRDAR_CD' ])
df4_agg = df3_groupby.agg(np.sum)
print(df4_agg.head(30))
当我打印df2时,我可以在TRDAR_CD列中看到11947和11948值。如下图所示
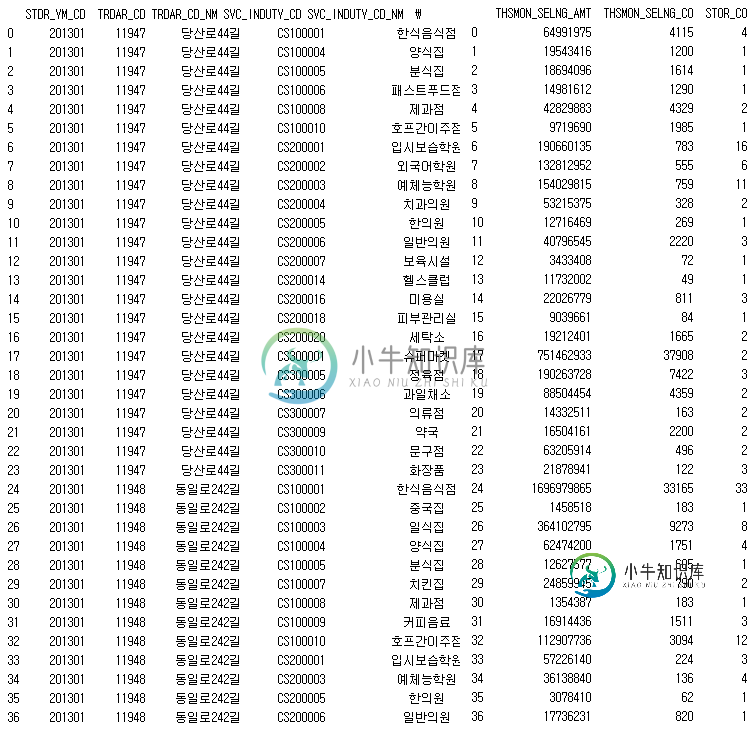
之后,我使用了groupby函数,并丢失了TRDAR_CD列中的11948个值。你可以在下图中看到这种情况

TRDAR_CD_NM 1085428非空对象
SVC_INDUTY_CD 1089023非空对象
SVC_INDUTY_CD_NM 1089023非空对象
无
共有1个答案

MultiIndex称为第一列和第二列,如果第一级有重复项,默认情况下,它会“分散”索引的较高级别,以使控制台输出更容易看到。
通过将display.multi_sparse设置为false,可以在multiindex的第一级中显示数据。
示例:
df = pd.DataFrame({'A':[1,1,3],
'B':[4,5,6],
'C':[7,8,9]})
df.set_index(['A','B'], inplace=True)
print (df)
C
A B
1 4 7
5 8
3 6 9
#temporary set multi_sparse to False
#http://pandas.pydata.org/pandas-docs/stable/options.html#getting-and-setting-options
with pd.option_context('display.multi_sparse', False):
print (df)
C
A B
1 4 7
1 5 8
3 6 9
import pandas as pd
import numpy as np
df2 = pd.read_table(r'tbsm_trdar_selng_utf8.txt' ,
sep='|' ,
header=None ,
usecols=[0 ,1, 2, 3 ,4, 11,12 ,82],
names=['STDR_YM_CD', 'TRDAR_CD', 'TRDAR_CD_NM', 'SVC_INDUTY_CD', 'SVC_INDUTY_CD_NM', 'THSMON_SELNG_AMT', 'THSMON_SELNG_CO', 'STOR_CO'],
dtype = { '0' : int})
df4_agg = df2.groupby(['STDR_YM_CD', 'TRDAR_CD' ]).sum()
print(df4_agg.head(10))
THSMON_SELNG_AMT THSMON_SELNG_CO STOR_CO
STDR_YM_CD TRDAR_CD
201301 11947 1966588856 74798 73
11948 3404215104 89064 116
11949 1078973946 42005 45
11950 1759827974 93245 71
11953 779024380 21042 84
11954 2367130386 94033 128
11956 511840921 23340 33
11957 329738651 15531 50
11958 1255880439 42774 118
11962 1837895919 66692 68
-
问题内容: 尽管有Docker的Interactive教程和常见问题解答,但当容器退出时,我仍然丢失了数据。 我已经按照以下说明安装了Docker:http : //docs.docker.io/en/latest/installation/ubuntulinux 在ubuntu 13.04上没有任何问题。 但是退出时它将丢失所有数据。 我还通过相同结果的交互式会话对其进行了测试。我忘记了什么吗?
-
我错过了什么? AMQ版本5.13.2 Java 1.8.0\u 74 Windows 10 给定一个简单的测试用例,传输两条Object消息,一条带有数据,另一条是数据结束标记。只有数据结束标记被接收。 队列在作业开始时创建,并在作业完成后销毁。 如果我运行更多的事务,我会看到大约50%的接收率。 日志清楚地显示接收器在第一条消息被放入队列之前就已启动,两条消息都被放入队列,但实际上只有第二条消
-
这看起来是一个简单的问题,但却给我带来了无尽的挫败感。这只是我用来玩耍的房子里的一个小盒子。 我尝试了跳过授权表版本,并使用了authentication_string字段,而不是仍在使用的密码版本。我也尝试过init-file方法,但没有成功。 如果我使用跳过授权表版本,并使用以下行: 我得到的结果是: 我不明白(完全)语法有什么问题。这让我为一个很小的问题而生气(我认为)。有人有什么想法吗?提
-
但是我想使用com.oracle,Windows上的jdk目录是JDK1.8。 那么有没有办法让pom“想要”我机器上实际拥有的工具版本呢?
-
当我在中添加以下代码时,我的设备上的应用程序丢失(消失)。 如果我没有添加此代码,则该应用程序已安装并按其应显示,但我收到警告: 应用程序是不可索引的谷歌搜索;考虑添加至少一个活动与动作视图意图过滤器。 我已经从官方留档和这个问题做了研究,但我的问题仍然不同。 编辑:这是我所有的清单:
-
问题内容: 我是Java新手。我正在做一个小型程序实践,并且会丢失return语句错误。 有人可以帮忙吗? 问题答案: 问题出在语句上。您缺少分支。当表达式的计算值为时,您的程序将不返回任何内容,因此将返回错误。 将其更改为如下所示: