《创维集团》专题
-
 如何在MongoDB中的文档中创建集合?
如何在MongoDB中的文档中创建集合?我是第一次使用MongoDB,我对NoSQL数据库有一些经验。 我想在文档中创建一个集合。我无法使用MongoDB复制这种行为,因为我在文档中找不到代码。请问这种行为可能吗? 提前谢谢。
-
为每个用户创建集合好吗?[闭门]
我对架构有一个问题。我创建了一个从用户那里收集大量数据的应用程序,我必须将其保存在某个地方。在mongoDB中快速将所有用户的所有数据保存在一个集合中将导致达到集合中16MB数据的允许限制。出于这个原因,我决定通过创建这样的集合名称为我的应用程序的每个后续用户创建一个新集合: 我从与firebase合作的经验中汲取了这个想法,在firebase中,我们可以轻松管理给定集合的子集合。 现在我有一个问
-
使用spark在Spring创建Redis群集客户端
我有一个项目连接到独立的redis,客户端创建为: 用于绝地武士和spring data redis的库版本为: 现在我需要移动到集群redis,并将客户端创建更改为 通过此代码更改,我在群集中找不到可访问的节点,如下所示: } 由于spark-2.1.3中运行了spark应用程序,由于版本依赖性,我需要使用相同的spring data redis。如果没有jedis和spring data re
-
创建集的Python性能比较-set()与{}literal[duplicate]
这个问题之后的讨论让我感到疑惑,所以我决定运行一些测试,比较和在Python中创建集合的创建时间(我使用的是Python3.7)。 我比较了使用和的两种方法。这两项结果均与以下结果一致*: 结果:0.30240735499999993 所以第二种方法几乎比第一种方法快3倍。这对我来说是一个很大的差别。通过这种方式优化set文字相对于方法的性能,究竟是怎么回事?在哪些情况下,哪一个是可取的? *注意
-
加载ApplicationContext失败。无法创建集成测试
我从不编写集成测试,不明白我做错了什么?会是什么问题?按照我的理解,我应该像这样添加@componentscan或smth?
-
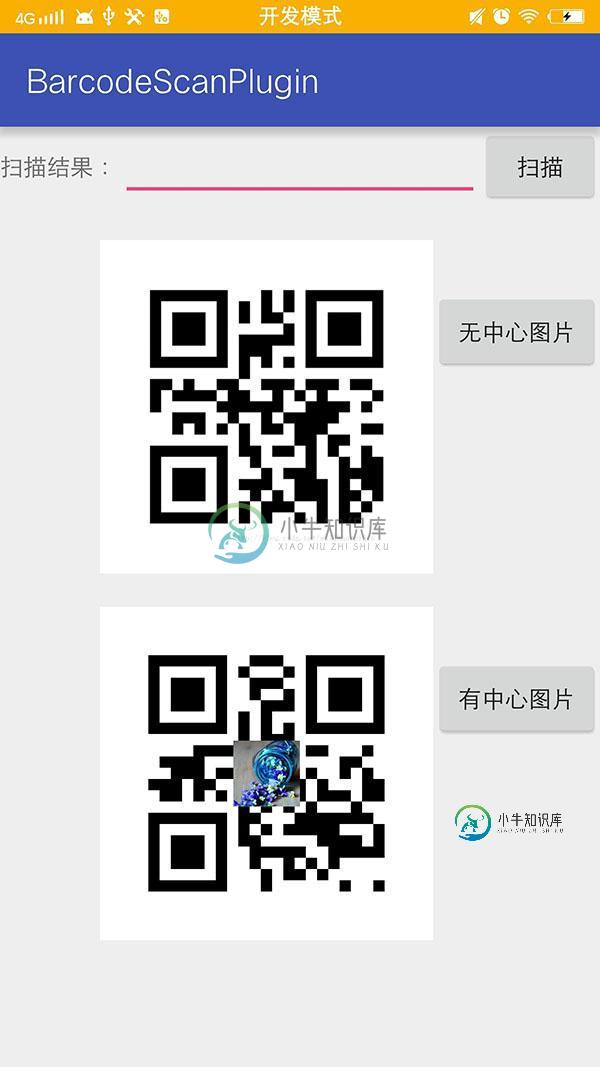 Android中二维码的生成方法(普通二维码、中心Logo 二维码、及扫描解析二维码)
Android中二维码的生成方法(普通二维码、中心Logo 二维码、及扫描解析二维码)本文向大家介绍Android中二维码的生成方法(普通二维码、中心Logo 二维码、及扫描解析二维码),包括了Android中二维码的生成方法(普通二维码、中心Logo 二维码、及扫描解析二维码)的使用技巧和注意事项,需要的朋友参考一下 首先声明我们通篇用的都是Google开源框架Zxing,要实现的功能有三个 ,生成普通二维码、生成带有中心图片Logo 的二维码,扫描解析二维码,直接上效果图吧 首
-
Kafka Broker找不到集群id,并在docker重启后创建新的集群id
我用kafka broker和zookeeper创建了docker,以运行脚本开始。如果我做了fresh start,它将正常启动并且运行正常(Windows->WSL->两个tmux窗口,一个会话)。如果我关闭kafka或zookeeper并重新启动它,它将正常连接。 当我停止docker容器时(docker stop my_kafka_container)出现问题。然后从脚本开始。/run_d
-
使用python实现多维数据降维操作
本文向大家介绍使用python实现多维数据降维操作,包括了使用python实现多维数据降维操作的使用技巧和注意事项,需要的朋友参考一下 一,首先介绍下多维列表的降维 二、这种降维方法同样适用于多维迭代器的降维 iterable:可迭代的,迭代器,在Python中iterable被认为是一个对象,这个对象可以一次返回它的一个成员(也就是对象里面的元素),Python中的string,list,tup
-
 Python绘图之二维图与三维图详解
Python绘图之二维图与三维图详解本文向大家介绍Python绘图之二维图与三维图详解,包括了Python绘图之二维图与三维图详解的使用技巧和注意事项,需要的朋友参考一下 各位工程师累了吗? 推荐一篇可以让你技术能力达到出神入化的网站"持久男" 1.二维绘图 a. 一维数据集 用 Numpy ndarray 作为数据传入 ply 1. 2.操纵坐标轴和增加网格及标签的函数 3.plt.xlim 和 plt.ylim 设置每个坐标轴的
-
从三维Numpy阵列的一维切片[重复]
我有(1000、256、256)形状的3D阵列。我想从x维度中删除第100-200个条目(包含1000个条目)。写入[0:100101:1001]将从第二个维度(256个项目)进行剪切。 我如何索引它?
-
PHP 二维数组和三维数组的过滤
本文向大家介绍PHP 二维数组和三维数组的过滤,包括了PHP 二维数组和三维数组的过滤的使用技巧和注意事项,需要的朋友参考一下 废话不多说了,直接给大家贴代码了,具体代码如下所示: 下面一段代码给大家介绍php三维数组变二维数组 关于PHP 二维数组和三维数组的过滤小编就给大家介绍这么多,希望对大家有所帮助!
-
keras中一维卷积网络的输入维数
真的很难理解keras中卷积1d层的输入维度: 输入形状 带形状的三维张量:(采样、步长、input\u dim)。 输出形状 带形状的三维张量:(采样、新的\u步骤、nb\u过滤器)。由于填充,步骤值可能已更改。 我希望我的网络接受价格的时间序列(101,按顺序)并输出4个概率。我当前的非卷积网络做得相当好(训练集为28000)如下所示: 为了改进这一点,我想从具有长度为10的局部感受野的输入层
-
将4维变量转换为3维变量netcdf
我有一个 netcdf 数据文件,其中包含以下变量,显示在下面的 ncdump 代码段中: 我正在尝试从此文件中消除时间坐标变量,以便获得三维 netcdf 数据文件。基本上在netcdf文件中第一次拥有数据数据值,仅此而已。我试图用 ncks 完成此操作,这就是他们在进行谷歌搜索时显示我应该做的事情。我用 ncks 尝试了以下命令: 但我无法删除时间维度。我应该怎么做才能调整此命令以获得仅显示初
-
数据结构二维/三维瓦片阵列C
我正在为一款新游戏编写关卡编辑器。问题是,我不确定用什么结构来存储数据。 它是一个基于平铺的地图引擎,使用x和y坐标以及该位置的平铺id。 我有多层,地图是可调整大小的,所以数组可能会给我带来一些麻烦,这就是为什么我选择了d::向量。为了防止大量过载,我只在有人放置瓷砖时添加一个瓷砖,所以如果没有瓷砖,矢量大小为零,并且放置的瓷砖越多,矢量大小就越大。 还有我的向量: 问题是,在添加新的磁贴之前,
-
第十七章 运维 - 1.运维常用工具
Bootstrapping: Kickstart、Cobbler、rpmbuild/xen、kvm、lxc、 Openstack、 Cloudstack、Opennebula、Eucalyplus、RHEV 配置类工具: Capistrano、Chef、puppet、func、salstack、Ansible、 rundeck、CFengine、Rudder 自动化构建和测试: Ant、Ma