《2024找工作》专题
-
命令行工具不工作-OS X El Capitan、Sierra、High Sierra、Mojave
我刚从约塞米蒂升级到埃尔卡皮坦(并复制了从埃尔卡皮坦升级到塞拉的问题),当我尝试在终端内键入例如时,我得到以下错误: 我没有安装Xcode,从来没有安装过。有人有办法吗?
-
在python中将新工作表添加到现有工作簿
问题内容: 我已经浏览了几乎所有以前的线程,但是仍然无法正常工作。我正在尝试向现有工作簿中添加新工作表。我的代码有效,但是它继续添加更多(实际上很多)工作表。我不知道解决方案。下面是我的代码 问题答案: 如果要向现有电子表格中添加工作表,只需继续并将新工作表添加到文件中,而不是复制对象并尝试向其中添加新工作表。
-
Workbox服务工作人员在PWA中没有正常工作
我试图用一个服务人员使用Workbox制作一个非常基本的PWA,但是我有一个问题。我正在使用命令行界面来生成服务工作人员,一切正常,完美的亮点,但我不能将我的index.html添加到运行时缓存中。我必须将其添加到全局模式,以便我的网站在离线模式下工作,但当我更新index.html文件时,除非我清除缓存,否则不会更新。我想要和我的js和css一样的东西。当我升级这些文件时,它们会更新。这是我的工
-
Servlet在Eclipse中工作,但不在tomcat服务器上工作
我正在自学servlet,找到了一些非常好的教程,并在Eclipse Neon EE中取得了巨大成功。(非常基本的servlet,只提供一个简单的静态网页) 在安装Eclipse Neon EE之前,我安装了Tomcat standalone,并对其进行了测试,得到了regulat apache Tomcat页面。我找到的教程还指导我如何在Eclipse中设置tomcat服务器。他们还向我展示了如
-
COPY不工作与docker-comment但工作发现与docker构建
我的任务是对接angular应用程序,并使用Nginx提供服务。 我已将angular项目构建到dist文件夹,并希望将此文件夹移动到nginx- 这就是我Docker项目的结构 在这个目录的顶部是一系列其他服务,它们需要与angular应用程序一起运行,而angular应用程序正在按预期运行。用下面的docker编写。yml文件 当我用docker build构建并运行这个容器时,它会按预期运行
-
laravel运行工匠队列:从后台的PHP内部工作
我们有laravel 5.6和很多队列。 在生产中,我有一个主管负责处理这些队列。 在localhost上,我使用“sync”选项同步/直接处理所有队列。 我想知道是否有可能在localhost上有不同的行为: 我想分派作业,然后直接通过php exec运行以下命令: 这应该在后台运行队列工作程序一次。 但是什么都没发生。工匠在这种情况下工作吗?
-
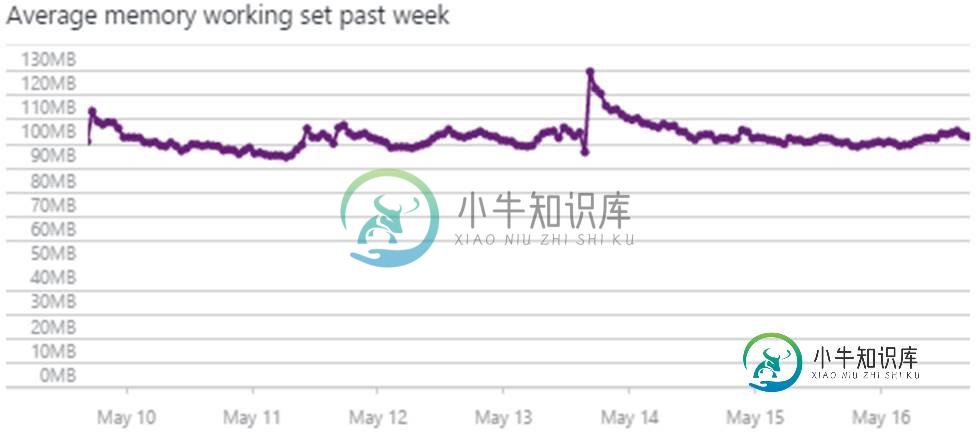 Azure中的平均内存工作集和内存工作集
Azure中的平均内存工作集和内存工作集我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示: 现在,我有三个问题: > 如何找出我的服务的专用最大内存是多少?一旦达到限制会发生什么? 内存工作集是进程中的线程最近接
-
Google工作表:工作表列表中匹配值的总和
我正在准备一份投资跟踪表。对于overview页面,我想查询并合并来自每个account选项卡的数据,但我很难弄清楚如何才能做到这一点。 以下是我的测试表链接:https://docs.google.com/spreadsheets/d/14sZmxkM65ax9BKrkjinwOrOQPrS_xhqPPLs68Rggii4/edit 我尝试使用的公式位于Overview选项卡的J列中。此公式适用
-
按工作表名称连接不同工作表的数据
我有多张谷歌表。所有数据列都具有相同的名称(id、日期、金额),但列数不同:在第1页中,“id”列是A列,在第2页中“id”列可以是C列或任何其他列。 我正在尝试创建一个主工作表,从所有工作表中提取所有数据并按列名排列。尝试使用Query,但它似乎可以与列id(A,B)一起工作,而在我的例子中,id(A,B)正在发生变化。 这是一张样品单
-
C#Excel:从不同工作簿复制工作表的问题
-
全日历调度程序中的工具提示不工作
我试图向fullcalendar scheduler 5.8添加工具提示,但未能实现此功能。 在fullcalendar调度程序模板中,我添加了“工具提示”和“popper”库以及CSS,它们可以处理简单的fullcalendar,但没有结果。我的模板起点是https://fullcalendar.io/docs/event-tooltip-demo 工具提示模板示例图像 在Javascript代
-
使用主键链接两个工作表的Google工作表
我有两个我想使用“主键”链接的工作表。目前,我已经使用函数从Sheet1导入了一些列到Sheet2(例如第一个单元格)。我的目的是完成与Sheet2中每个导入行相关的数据。但是,Sheet1与其他人共享,因此他们可以修改行的内容,而无需删除或修改我在Sheet2中添加的数据(而这在Sheet1中不存在)。 考虑到我的表中有一列“id”可以被视为主键,我如何在sheet2中添加新数据,只要它与“id
-
语言工作者如何使用Python在Azure Functions中工作?
我正在使用Azure函数进行一个ETL项目,在该项目中,我从blob存储中提取数据,在Python和pandas中转换数据,并使用pandas将数据加载到_sql()。我试图通过使用异步IO和语言工作者来提高这个过程的效率。 我有点困惑,因为我的印象是asyncio使用一个线程工作,但Azure Functions文档说如果你改变配置,你可以使用多个语言工作者,甚至一个不使用async关键字的方法
-
jpa-entitylistener-@prepersisted和@preupdate成功工作,但@postpersisted和@postupdate不工作
下面是我的代码: 实体->区域 接口,用于实体共享相同的外部EntityListener 下面是我执行上面的Main方法时的控制台日志 下面是我的pom.xml
-
Toast和startActivity在片段中工作,但不在类中工作
TerminalFragment.java VLC.Java