《数据库文件》专题
-
添加数据库或模式
创建新模型时,将自动创建一个数据库或模式(名为 Default),它是默认的数据库或模式。所有新添加的对象(表和视图)都属于默认数据库或模式。 你可以在浏览器的模型选项卡中查看以树结构表示的所有数据库或模式及其对象。 在浏览器的模型选项卡中数据库或模式的弹出式菜单选项包括: 选项 描述 新建数据库 / 新建模式 创建数据库或模式。 删除数据库 / 删除模式 从模型中删除已选择的数据库或模式及其对象
-
数据库角色设计器
【注意】下列选项和选项卡会根据服务器版本而有所不同。 常规属性 角色名 定义数据库角色的名。 所有者 指定数据库角色的所有者。 成员 在列表里,指定已选择的数据库用户和角色成为此数据库角色的成员。 成员属于 在列表里,指定此数据库角色成为已选择的数据库角色的成员。 拥有的模式 在列表里,勾选数据库角色拥有的模式。 数据库权限 在网格中,对照在“权限”列出的数据库权限,勾选“授予”、“授予选项”或“
-
数据库用户设计器
【注意】下列选项和选项卡会根据服务器版本和用户类型而有所不同。 常规属性 用户名 定义数据库用户的名。 验证 选择数据库用户的安全类型。 登录名 指定数据库用户使用的 SQL Server 登录。 默认模式 选择将拥有此数据库用户创建之对象的默认模式。 证书名 选择要用于数据库用户的证书。 非对称密钥名 选择要用于数据库用户的非对称密钥。 角色 在列表里,指定此数据库用户成为已选择的数据库角色的成
-
添加数据库或模式
创建新模型时,将自动创建一个数据库或模式(名为 Default),它是默认的数据库或模式。所有新添加的对象(表和视图)都属于默认数据库或模式。 你可以在浏览器的模型选项卡中查看以树结构表示的所有数据库或模式及其对象。 在浏览器的模型选项卡中数据库或模式的弹出式菜单选项包括: 选项 描述 新建数据库 / 新建模式 创建数据库或模式。 删除数据库 / 删除模式 从模型中删除已选择的数据库或模式及其对象
-
数据库角色设计器
【注意】下列选项和选项卡会根据服务器版本而有所不同。 常规属性 角色名 定义数据库角色的名。 所有者 指定数据库角色的所有者。 成员属于 在列表里,指定此数据库角色成为已选择的数据库角色的成员。 成员 在列表里,指定已选择的数据库用户和角色成为此数据库角色的成员。 拥有的模式 在列表里,勾选数据库角色拥有的模式。 数据库权限 在网格中,勾选“权限”列出的数据库权限,勾选“授予”、“含授予选项”或“
-
数据库用户设计器
【注意】下列选项和选项卡会根据服务器版本和用户类型而有所不同。 常规属性 用户名 定义数据库用户的名。 验证 选择数据库用户的安全类型。 登录名 指定数据库用户使用的 SQL Server 登录。 默认模式 选择将拥有此数据库用户创建之对象的默认模式。 证书名 选择要用于数据库用户的证书。 非对称密钥名 选择要用于数据库用户的非对称密钥。 角色 在列表里,指定此数据库用户成为已选择的数据库角色的成
-
添加数据库或模式
创建新模型时,将自动创建一个数据库或模式(名为 Default),它是默认的数据库或模式。所有新添加的对象(表和视图)都属于默认数据库或模式。 你可以在浏览器的模型选项卡中查看以树结构表示的所有数据库或模式及其对象。 在浏览器的模型选项卡中数据库或模式的弹出式菜单选项包括: 选项 描述 新建数据库 / 新建模式 创建数据库或模式。 删除数据库 / 删除模式 从模型中删除已选择的数据库或模式及其对象
-
持久化数据库存储
目的 配置 NFS 共享为 OpenShift 节点提供存储,并且配置 OpenShift 持久卷以绑定至数据库 Pod。 环境 openshift v3.11.16/kubernetes v1.11.0 步骤 配置 NFS 共享持久卷1. 登录到 NFS 服务器 # ssh nfs.example.com2. 创建 config-nfs.sh 脚本,内容如下 #!/usr/bin/sh exp
-
 知乎 数据仓库 凉经
知乎 数据仓库 凉经写在前面:这段时间经过了一段高强度笔面,但还是颗粒无收 面试 面试官进来就说:你不会flink? 我:了解的不多 那我们这次可能通过概率不大,但我们仍然可以就大数据来一波交流 实时: Flink的checkpoint Flink的反压 Flink的状态后端 离线: Kafka的有序性(不可全局有序,但可分区有序)面试官说不对??我让他下去再好好看看 Kafka一定不会丢数据嘛? Spark的内存模
-
 kmsma数据库公司面经
kmsma数据库公司面经1,CAP的概念,raft属于哪一种? 2,读写分离的东西懂不懂?比如说主从复制中读请求跟写请求的关系?回答了主从复制中异步复制导致复制滞后带来的一些一致性问题。 3,懂不懂数据库中按行,按列啥的忘了? 4,ACID的概念 5,lambda和function的区别,与function ptr的区别? 6,进程,线程,协程的区别? 7,什么时候会出现segment fault?数组越界一定会导致se
-
 SpringSecurity-连接数据库访问
SpringSecurity-连接数据库访问主要内容:1.引入jar包,2.配置文件编写,3.编写数据库,4.编写实体类,5.编写Mapper接口,6.在业务层中引入用户的用户名和密码,7.测试1.引入jar包 2.配置文件编写 appilication.properties 需要注意后面需要加上时区,因为当前引入的是SpringBoot2以上的版本 3.编写数据库 4.编写实体类 5.编写Mapper接口 这里是继承了BaseMapper接口 6.在业务层中引入用户的用户名和密码 第一个是导入UserMapper接口 第二个是根据接口去
-
 社招-数据仓库面试
社招-数据仓库面试Gaussdb是什么数据库 Gaussdb和Doris有什么区别 数据湖和数据仓库有什么区别 hudi中你们用的哪种表类型 hudi怎么实现实时数据更新的 HIVE有哪些模块 知道HIVE的thrift吗,有什么好处 生产中是用哪种方式连接HIVE的,会用jdbc连接吗 知道哪些spark的运行模式 yarn-client和yarn-cluster的区别是什么,从中选一个运行模式具体介绍下 sel
-
 达梦数据库java面经
达梦数据库java面经春招,面试官很好,大家秋招可以投
-
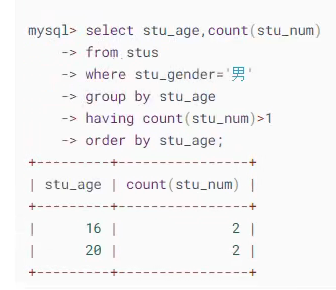 mysql - 数据库语法问题?
mysql - 数据库语法问题?求解答,这个select后的聚合函数与排序谁先执行,比如图示句子?
-
项目的数据库设计?
需求描述 有一个项目,面向学校德育评价,打算留一个发布通知的模块,现在拿不准如何设计数据库 个人方案 我个人有预想两种方案去解决 在mysql中建一个系统通知表 直接存redis中 第一种方案的优点是可以实现数据的持久化,但是对于一些时效性较强的通知【例如系统维护通知等】需要进行额外处理【因为基本上过了时效以后这条记录几乎不会再用到了】 第二种方案的优点是可以比较轻松的处理时效性问题,但是需要考虑