《泡池子》专题
-
User-Agnet代理池
主要内容:自定义UA代理池,模块随机获取UA在编写爬虫程序时,一般都会构建一个 User-Agent (用户代理)池,就是把多个浏览器的 UA 信息放进列表中,然后再从中随机选择。构建用户代理池,能够避免总是使用一个 UA 来访问网站,因为短时间内总使用一个 UA 高频率访问的网站,可能会引起网站的警觉,从而封杀掉 IP。 自定义UA代理池 构建代理池的方法也非常简单,在您的 Pycharm 工作目录中定义一个 ua_info.py 文件,
-
Hystrix和连接池
请原谅,这很可能是一个愚蠢的新手问题。 我们使用Hystrix作为两个服务之间的断路器。为了提高性能,我们使用了连接池。我们正在使用Apache HttpClient的PoolingHttpClientConnectionManager来处理连接池。 我们还使用Hystrix的“TimeoutInMissels”属性来捕获问题。 我们遇到的“问题”是,在正常操作中,创建一个新的HTTPS连接需要c
-
SQLAzure和连接池
我一直在到处寻找,收集零碎的东西,如果这已经在其他地方得到了回答,但我找不到,我很抱歉。 我正在用Java编写一个web应用程序,在后端使用Tomcat和SQLAzure。 有多个servlet访问SQLAzure DB。我想使用由Tomcat 8.5管理的连接池 我的应用程序上下文。META-INF中的xml如下所示: 在Java代码中,我以典型的方式访问: ds.get连接。 一切似乎都正常,
-
动态线程池
问题内容: 我有一个运行时间很长的过程,可以监听事件并进行一些激烈的处理。 目前,我通常用于限制并发运行的作业数量,但是根据一天中的时间以及其他各种因素,我希望能够动态地增加或减少并发线程的数量。 如果我减少了并发线程的数量,那么我希望当前正在运行的作业能够很好地完成。 是否有Java库可以让我控制并动态增加或减少线程池中运行的并发线程数?(该类必须实现ExecutorService)。 我必须自
-
2.2.2 Java线程池
一、概述 在我们的开发中经常会使用到多线程。例如在Android中,由于主线程的诸多限制,像网络请求等一些耗时的操作我们必须在子线程中运行。我们往往会通过new Thread来开启一个子线程,待子线程操作完成以后通过Handler切换到主线程中运行。这么以来我们无法管理我们所创建的子线程,并且无限制的创建子线程,它们相互之间竞争,很有可能由于占用过多资源而导致死机或者OOM。所以在Java中为我们
-
池Websocket连接-NodeJS
我希望构建一个节点应用程序,将实现以下目标: null
-
使用连接池
我正在用vaadin和spring开发一个Web应用程序java,比如容器和eclipse链接,比如持久化框架。现在我想在我的应用程序中使用一个连接池。我在谷歌上读了一些我还没读到的东西。这是我的应用程序配置: 我的春日文脉 我的persistence.xml 但我得到以下异常:
-
Postgres Npgsql连接池
当使用Npgsql for Postgres时,我想更好地理解连接池。(http://www.npgsql.org/) 当我使用连接字符串时: UserID = rootPassword = myPassword主机=本地主机;端口= 5432;Database = myDataBasePooling = true最小池大小= 0;最大池大小= 100; “汇集”将在哪里进行?在我的应用服务器上还
-
内存池管理
静态内存池接口 结构体 struct rt_mempool 内存池控制块 更多... 类型定义 typedef struct rt_mempool * rt_mp_t 内存池类型指针定义 函数 rt_err_t rt_mp_init (struct rt_mempool *mp, const char *name, void *start, rt_size_t size,
-
电池柱状图
实现很漂亮的电池柱状图Demo,有三维效果。有3种自定义样式,可以进行扩展。 [Code4App.com]
-
javascript - 事件冒泡是宏任务还是微任务,以及冒泡的触发时机?
之所以想到这个问题,是因为在看一篇介绍事件循环的文章的一个例子 执行结果是 关于事件循环、宏任务、微任务我已经比较了解。但是这些内容和事件冒泡、捕获的传递结合起来,之前没有考虑过。 文章开头介绍宏任务包括“UI交互事件”,所以点击事件是宏任务 但从执行结果来看,事件冒泡是属于微任务。当然,一个是事件的点击,一个是事件的传递,性质不同。不知道官方标准是怎么定义这部分内容的?另外,和这个有关的标准,是
-
ThreadPoolExecutor中的核心池大小与最大池大小
当我们用来谈论核心池大小和最大池大小之间的区别到底是什么? 可以借助示例来解释吗?
-
使用AWS API的链接标识池和用户池
我有一个混合移动应用程序使用AWS Javascript SDK与Amazon Cognito集成,使用Cognito用户池作为身份提供者。很管用。 我需要使用AWS API遍历数据以生成报告。一个关键部分是列出哪个用户(显示他们的用户名)与哪些项(与他们的认知身份相关联)相关联。
-
错误池。ConnectionPool-无法创建池的初始连接
我是Grails新手。在DataSource.groovy中进行了一些基本配置后,我的grails应用程序无法启动。我得到以下错误 数据库radb存在。我已经核实过了 我的datasource.groovy文件供参考,如下所示
-
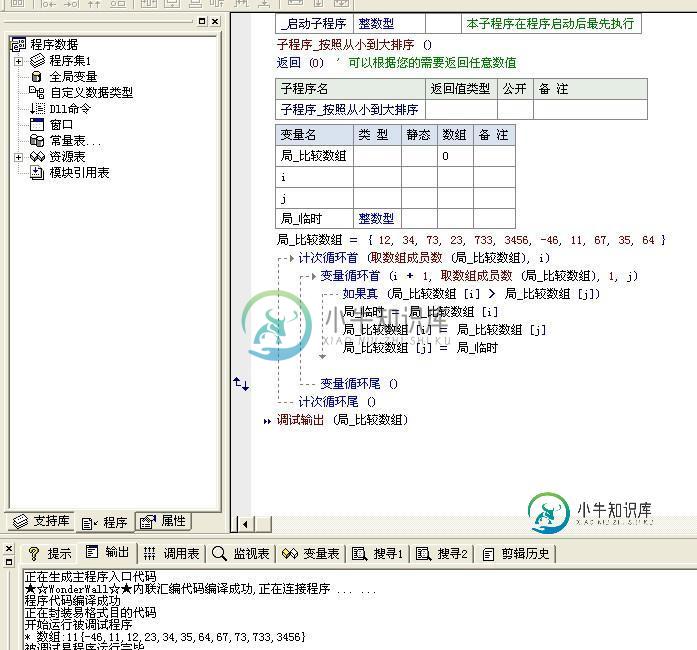 详解易语言的冒泡算法
详解易语言的冒泡算法本文向大家介绍详解易语言的冒泡算法,包括了详解易语言的冒泡算法的使用技巧和注意事项,需要的朋友参考一下 我们做一些游戏脚本软件时候,经常要用到这个算法,比如求解离自己身边最近的怪物优先攻击,就要用到这个算法,冒泡算法可以快速的把一组数据按照从大到小,或者从小到大的顺序进行快速排序. 冒泡算法的核心就是,从第一位开始把数据提取出来,跟余下的数据逐一进行比大或者小(看你是按照从大到小,还是从小到大顺序