《字节招聘》专题
-
字节流和字符流
问题内容: 请解释什么是字节流和字符流。这些到底是什么意思?Microsoft Word文档是面向字节还是面向字符? 谢谢 问题答案: 流是顺序访问文件的一种方式。字节流逐字节访问文件。字节流适用于任何类型的文件,但不适用于文本文件。例如,如果文件使用unicode编码,并且一个字符用两个字节表示,则字节流将分别处理这些字节,您需要自己进行转换。 字符流将逐字符读取文件。必须为字符流提供文件的编码
-
 字节跳动QA、虾皮阿里深信服测开社招面筋
字节跳动QA、虾皮阿里深信服测开社招面筋简单描述下楼主的情况,本科985,毕业1.5年,一直是做测开,今年拿到字节和虾皮的offer(可提供字节内推,放最后) 因为当初面试的时候把所有的题目都整理到一起了,具体细节可能不太清晰,就先分享一下印象比较深的问题,然后把具体的知识点放后面了 深信服 一面: 常规的知识点面试,侧重python和linux相关的知识 1、python的深拷贝、浅拷贝的区别 2、python的内存管理机制(垃圾回收
-
 字节 秋招 商业化技术 后端开发 一二面(凉经)
字节 秋招 商业化技术 后端开发 一二面(凉经)tiktok广告流量分发业务。 9.5 一面(1h) 自我介绍 实习项目 项目拷打 为什么通讯选择用Netty 还有什么长连接的方式 长连接数量较多 占用资源过多 怎么解决 Java并发容器 ConcurrentHashMap怎么保证线程安全 synchronized上锁解锁流程 synchronized为什么设计为可重入锁 手撕 反转链表 K个一组反转链表 9.18 二面(1h) 自我介绍 实习
-
 字节跳动2024秋招研发第四场笔试【后端方向】
字节跳动2024秋招研发第四场笔试【后端方向】第一题:吃糖果xx值大于等于x(二分答案) 题意:给一个长度为的数组代表个糖果的幸福值,一天可以吃任意个糖果得到幸福值其中不代表下标,吃的顺序可以任意。 现在求至少吃多少天可以得到至少的幸福值。 思路:不难发现答案是线性的,存在一个分界天数使得达到这个分界后都能达到,因此使用二分天数。我们可以贪心的认为对于幸福值大的糖果尽量在每一天更早的吃。即先对降序,每次都长度为累加(我直接累减,这里可以用前缀
-
 秋招回顾5-字节提前批系统架构运维面试
秋招回顾5-字节提前批系统架构运维面试7.14提前批面试,属于面的比较早的一波了~ 先自我介绍一下 然后问技术问题: haproxy,keepalived实现原理 VIP和IP有啥区别 K8S网络了解吗 POD间的通信如何实现 FLANNEL了解多少,处理网络连接,-> 网络连接具体包括哪些工作呢? iptables规则你了解多少 calico 原理 iptables链
-
 字节跳动2023届秋招面经-搜索产品运营-成都
字节跳动2023届秋招面经-搜索产品运营-成都一面-单面30min-0914 开头挖简历 1.自我介绍 2.挑选简历里一段具体的经历,说说自己怎么抓热点的,怎么应用到产品中去的,应用后怎么检测效果的 针对搜索产品运营岗位本身: 基础题: 1.有使用过今日头条/抖音吗? 2.你觉得吸引你使用这些软件(自己常用的)APP的原因是? 3.如何给B站想要改进热点这一块的板块内容,你会怎么做? 4.现在一般的搜索软件都是搜完后直接出结果的,你觉得这种搜
-
 字节跳动 大数据开发工程师一面面经 (社招)
字节跳动 大数据开发工程师一面面经 (社招)1、自我介绍 2、跳槽理由 3、介绍团队 4、自己感觉做的最好的项目(扣的很细,聊了很久) 5、遇到过的技术问题 6、数据倾斜如何解决 7、缓慢变化维怎么解决 8、周期变化事实数据,比如七天累计订单表应该放哪一层?为什么? 9、什么数仓才算一个好的数仓 10、雪花模型跟星型模型区别 11、写sql题 12、反问 面了三家 淘天、字节、pdd,都offer了,这个草稿也是当时写的一直忘发了,后面有空
-
 字节抖音直播(游戏业务)-后端 秋招一面凉经
字节抖音直播(游戏业务)-后端 秋招一面凉经2024/08/28 1h 基本介绍、选一段最有亮点的实习来介绍然后面试官开始拷打 spring框架最初是解决的什么问题?它是怎么管理bean的生命周期的? 这里为什么用rocketmq?消息发送失败怎么办? 可以用哪些redis数据结构存你这个项目里接口响应的数据 旧版redis怎么通过单线程处理网络I/O请求的 事件队列 你项目的系统瓶颈在哪? 你提到的去重,还有什么方式吗?(我只说了sele
-
通过套接字Java发送字节数组、字符串和字节
我需要通过Java socket发送一个文本消息到服务器,然后发送一个字节数组,然后是一个字符串等等。到目前为止,我所开发的内容还在工作,但客户端只读取发送的第一个字符串。 从服务器端:我使用发送字节数组,使用发送字符串。 问题是客户机和服务器不同步,我的意思是服务器发送字符串然后字节数组然后字符串,而不等待客户机消耗每个需要的字节。 我的意思是情况不是这样的:
-
从字节数组中删除前16个字节
问题内容: 在Java中,如何获取byte []数组并从数组中删除前16个字节?我知道我可能必须通过将阵列复制到新阵列中来执行此操作。任何例子或帮助将不胜感激。 问题答案: 参见Java库中的类:
-
字节vs字节数组在Python 2.6和3中
问题内容: 我正在Python中测试vs。我不明白某些差异的原因。 一个迭代器返回的字符串: 给出: 但是迭代器返回s: 给出: 为什么会有所不同? 我想编写可以很好地转换为Python 3的代码。那么,Python 3中的情况是否相同? 问题答案: 在Python中,2.6字节只是str的别名 。 引入此“伪类型”是为了(部分地)准备要与Python 3.0转换/兼容的程序(和程序员!),在Py
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
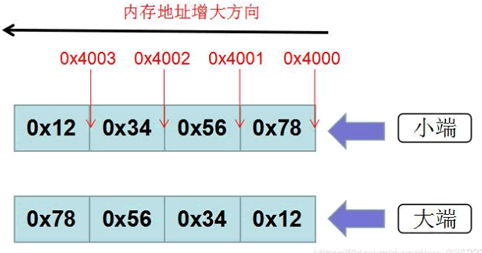 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x
-
比较字节值?
问题内容: 我很好奇为什么,当我将一个数组与一个值进行比较时… …返回,而… …才不是?是一个数组 问题答案: 比较整数,因为0xFF是整数,此表达式 会将您的字节 扩展为int并将括号内的内容与第二int进行比较。至于你说的是,它将首先被调整为整数且相比于整数,所以这个作品。 将一个字节与int比较: 是一个字节(有符号),其值为。 不等于,因此这就是为什么在比较integer之前必须将data