《联影》专题
-
汇编中的内联c方法
让我们有一个名为myClass的小类。我很感兴趣的是,当方法内联或不内联时,如何看待. ash的差异。我制作了两个程序,在cpp文件中带有和不带有内联关键字,但. ash的输出是相同的。我知道内联只是编译器的提示,很有可能我是优化的受害者,但有可能在一个小的cpp示例中看到内联和非内联方法的差异吗? h: cpp: 主要: 附注: 两种情况下的ASM输出:
-
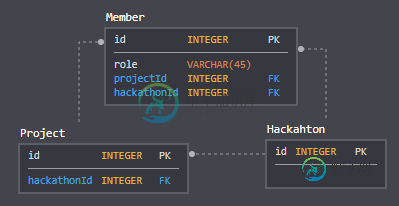 SpringData联接实体的QueryDSL筛选
SpringData联接实体的QueryDSL筛选我正在尝试在我的Spring数据服务中使用查询DSL来实现类似于SQL的查询 成员可以是项目或黑客马拉松的成员。项目是黑客马拉松的一部分。我试图找到哈查顿和子项目的所有成员。 因为谓词产生了交叉连接,所以QueryDslPredicateExecutor接口对我不起作用: 我尝试过使用JPAQuery来手动管理连接策略,但是也遇到了同样的问题: Hibernate:选择memberenti0_.i
-
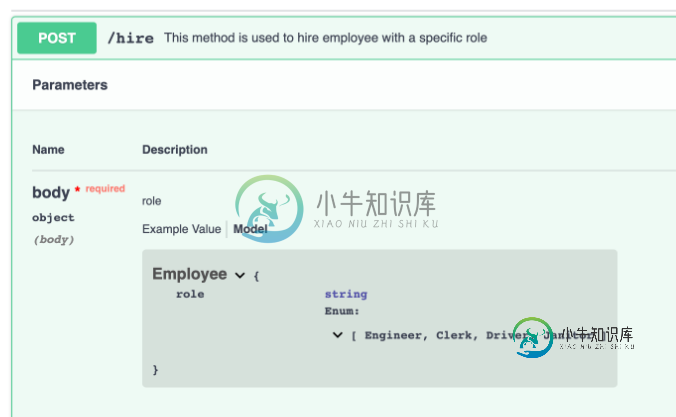 Swagger:将整数关联到枚举
Swagger:将整数关联到枚举我想在我的项目中包含swagger,但我不能更改代码或变量名称。 我有一个返回列表的服务: 代码变量来自枚举操作可能的错误: 是否可以将“代码”和TYPE枚举相关联,以便我可以在生成的swagger文档中显示选项列表? 谢谢
-
代码覆盖率内联函数
我有这个函数写在科特林 但是当我为此函数创建单元测试时,它在报告上显示0覆盖率。我正在使用jacoco进行代码覆盖。你们知道如何正确地对内联功能进行单元测试吗?谢谢!
-
Netty 4-EventLoopGroup-EventLoop-EventExecutor-线程关联
我正在研究Netty 4.0.0.Alpha5代码,以了解如何处理线程。我还阅读了Netty 4新线程模型的介绍,网址为http://netty.io/wiki/new-and-noteworthy-in-4.0.html#wiki-第2-34页。 据我所知,目标是: 线程关联,将通道粘贴到单个线程(EventLoop)。我想,采取这种方法是为了减少缓存未命中,并改善NUMA硬件上的情况 所以,我
-
复杂对象KStream GlobalKTable左联接
我对Kafka的溪流很陌生。我想执行以下KStream-GlobalKTable纯基于DSL的左联接操作,而不使用map操作。 和另一个输入主题,它是 ,其中value: 我要执行左联接操作是一个流,主数据是一个全局表,以实现结果值为 连接条件为 代码:
-
使用GlobalKtables的KStream联接上的
我有一个Kafka Streams应用程序,其中我将读取“topic1”的KStream与读取“topic2”的GlobalKTable连接起来,然后再与读取“topic3”的GlobalKTable连接起来。 当我尝试同时推送消息到所有3个主题时,我会得到以下异常- org.apache.kafka.streams.errors.invalidStateStoreException 如果我在这些
-
JPA选择关联并使用NamedEntityGraph
我首先尝试了用户图,但是由于我们要获取组,所以我尝试了组图。同样的例外。 问题是,没有简单的方法向生成的查询添加,因为我不知道应该加入关联的哪些属性。我必须加载Entitygraph,遍历它和任何子图,并生成正确的join子句。 关于查询生成的更多细节: queryException:查询指定了连接提取,但是提取的关联的所有者不在选择列表中
-
Flink SQL间隔联接未触发
我在两个无界流之间有一个简单的间隔连接。这适用于较小的工作负载,但对于较大的(正式生产环境),它不再有效。通过观察输出,我可以看到FlinkSQL作业仅在扫描整个主题(并因此读入内存?)后才触发/发出记录,但我希望作业在找到ingle匹配后立即触发记录。因为在我的正式生产环境中,作业无法承受将整个表读入内存。 我正在做的间隔连接与这里提供的示例非常相似:https://github.com/ver
-
 20221012银联数据面试(一面)
20221012银联数据面试(一面)20221012银联数据面试(一面) 写在前面:约的早上10:10,10:11开始面试,大搞20分钟结束,稍微有点卡,整体体验不错~在这里记录下 面试流程 自我介绍 SparkStreaming项目详说(说一半儿不让我说了,估计嫌烦) 问项目是不是事实项目,说不是,是练手的 问scala相关知识,问函数式编程优点,说了个简单,符合大数据的逻辑,没了,他问我还有没有?/捂脸,是真不知道了 问java
-
 招联金融-数据岗-面经
招联金融-数据岗-面经笔试(10.11) 岗位是数据开发,一道编程,几十道选择。难度不大,但涉及面挺广。 一面(10.15) 笔试完,隔天约面,效率很高。 项目介绍,自己的分工 特征选择方法 数据挖掘中对于缺失值的处理方案 说一下Python(pandas)中常用的数据处理算子。 Spark的原理,分布式是怎么搭建的。 Sql中union和union all的区别 数据行转列怎么操作 xgboost和gbdt的区别 x
-
 广联达测试开发面经
广联达测试开发面经1,自我介绍。 2,项目怎么做的?实验室项目还是? 3,SpringAOP在项目里怎么体现的? 4,项目里用到redis,怎么保持一致性的? 5,自己做的论坛项目中的难点? 6,线程的获取方式? 7,Mysql用到什么程度?只会增删改查吗? 8,Linux常用指令? 9,你知道的网络协议介绍一下? 10,介绍一下简历上写的实验的课题 11,课题研究过程中遇到了什么困难,怎么解决的? 12,为什么选
-
 2023联想SSG测试岗面试
2023联想SSG测试岗面试1. 为什么做测试,有投过开发岗吗,哪些公司会投开发,为什么联想投测试 2. 对开发能力不够的人转测试怎么看 3. 对外面对联想的流言蜚语怎么看 4. 为什么选择联想 5. &和&&有什么区别,哪个有中断性 6. ==和equals有什么区别 7. 完成项目最大的问题是什么,怎么解决的 8. 未来职业规划是什么,内向的人可以去做项目管理吗 9. 你最大的优势和劣势 10. 常用linux操作命令
-
NULL和nullptr的关联与差别
在写代码的过程中,有时候需要将指针赋值为空指针,以防止野指针。在C中,都是使用NULL来实现的;在C++中,除了NULL之外,还提供了nullptr来进行定义。那么两者之间有什么区别呢,分别适用于什么类型的场景呢? NULL在C/C++中的含义 NULL是一个宏定义,它的值是一个空指针常量,由实现来进行定义。C语言中常数0和(void*)0都是空指针常量;C++中常数0是,而(void*)0 不是
-
机器学习:关联与回归
关联规则:关联规则反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。Apriori算法利用频繁项集生成关联规则。它基于频繁项集的子集也必须是频繁项集的概念。频繁项集是支持值大于阈值(support)的项集。