《联影》专题
-
使用多个关联Hibernate获取
我正在为实体对象上的延迟加载集合执行此操作: 我想返回一个实体对象,其中加载了多个延迟加载的集合,我可以这样做吗(传入一个列表并为单个条件设置多个关联?):
-
Php联系人表单插入Mysql
最后编辑:现在一切正常工作将在下面的工作代码,清理后像idealCastle说,并修复了一些语法错误,一切正常工作,因为它应该与javascript验证谢谢大家 超文本标记语言代码: Javascript文件: PHP文件:
-
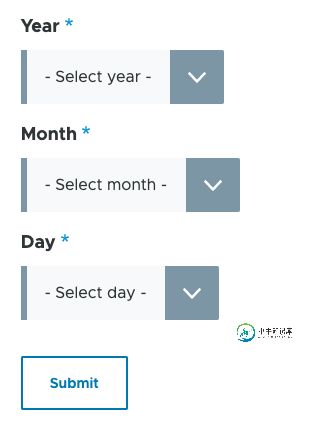 Drupal 9:级联Ajax选择表单
Drupal 9:级联Ajax选择表单本文向大家介绍Drupal 9:级联Ajax选择表单,包括了Drupal 9:级联Ajax选择表单的使用技巧和注意事项,需要的朋友参考一下 借助Drupal 9中内置的Ajax和状态系统,可以很轻松地将表单中的不同选择元素绑定在一起。这意味着任何Drupal表单都可以具有一个select元素,该元素可以将选项显示和更新为同一表单中的另一个select元素。 。使用此系统,您可以创建一个分层系统,其
-
使用EF核心级联删除
我目前对EF Core有一些问题。我有一些需要删除的数据,我正在努力查看流畅的API是如何工作的,正是关于函数。 考虑到微软自己网站的经典博客/帖子场景,我想知道到底是什么实体,OnDelete()是“目标”(因为没有更好的词),在某些情况下,它似乎是博客,在另一些情况下,是帖子。是否可以从两侧定义级联删除(即当父博客被删除时,帖子被删除),如果是这样,我认为代码应该如下所示: <代码>模型。实体
-
使flex子级内联块[重复]
我想让flex的孩子渲染,使位于的宽度之下,而不是容器的宽度之下。 显然flex子项不能设置为内联块? 有解决这个问题的方法吗? https://codepen.io/joshuajazleung/pen/EbwZmJ
-
LR与SVM的联系与区别?
本文向大家介绍LR与SVM的联系与区别?相关面试题,主要包含被问及LR与SVM的联系与区别?时的应答技巧和注意事项,需要的朋友参考一下 LR与SVM都可以处理分类问题,且一般都可以用于线性二分类问题 两个方法都可以增加不同的正则化项 区别: LR是参数模型,SVM是非参数模型(参数模型是假设总体服从某一个分布,该分布由一些参数确定,在此基础上构建的模型为参数模型,而非参数模型对于总体的分布不做假设
-
在SQL中级联菱形删除
问题内容: 如果我的数据库中有一个简单的User表,而有一个以User.id作为外键的简单Item表,则: 如果将用户从表中删除,我需要先删除所有相关项,以免破坏参照完整性约束。这很容易做到 但是,如果我也有引用用户的集合,还有一个将项目收集到集合中的表,那么我很麻烦,即以下附加代码不起作用。 该错误表明“可能导致循环或多个级联路径”。我认为推荐的解决方法是 重新设计表格,但是我看不到如何做。或者
-
右联接查询不起作用
问题内容: 我有两个表:和。 我想基于item_number从两个表中检索数据,并且在以下查询中工作正常。(使用内联接) 但是我也希望’items’表中的所有行,即使在opensalesorder和items中找不到与ItemName匹配的内容。 但是使用下面的查询似乎对我不起作用。 即使在左侧找不到匹配项,右联接也会从右表返回结果。 查询正确吗? 谢谢 问题答案: 这是您的查询: 该条件是“撤销
-
T-SQL-什么是内联视图?
问题内容: 我最近回答了这个问题,如何依次按顺序调用用户定义的功能与选择组一起使用 我的答案是使用内联视图执行该功能,然后对它进行分组。 在评论中,提问者不理解我的回答,并要求提供一些网站/参考资料以帮助解释它。 我已经做了一个快速的谷歌,还没有找到任何详尽的资源来详细解释什么是内联视图以及它们在哪里有用。 有没有人可以帮助解释什么是内联视图? 问题答案: 从这里开始:内联视图是另一个SELECT
-
联合查询的结果顺序
问题内容: 我有一个联合查询,它从两个不同的总体中获取计数。如何强制结果按查询中写入的顺序而不是升序/降序返回? 我希望第一个结果始终作为第一行返回。这可能吗? 问题答案: 您必须使用ORDER BY子句指定订单。在您的示例中,您可以执行以下操作:
-
xml路径的字符串串联
问题内容: 你好!今天,我学习了在mssql中连接字符串的技术。由于我从未在mssql中使用过xml,而google却没有帮助,所以我需要问你。 让我们想象一下默认情况。我们需要连接表中的一些字符串: 所以我得到这样的东西: 好的。它工作正常。但是我有两个非常相似的连接块。区别只是结果字符串看起来像这样: 和 因此,我可以使用不同的字符串构造函数编写2个非常相似的代码块(已经完成,btw),或尝试
-
具有内部联接的SQL max()
问题内容: 我正在创建一个拍卖网站。人们可以在这里寻找物品并在其上下注。我希望在用户帐户区域中有一个列表,显示用户对其进行出价的所有项目。 当然,每个项目可以有多个来自不同用户的赌注,因此我只希望显示最高金额的项目。这样一来,用户就可以关注其出价所在的所有项目,并可以跟踪他是否仍然是出价最高的项目。 这是我的数据库的样子: 因此,如上所示,我有3个表(item,itembid和user)。如您所见
-
Javascript console.log(object)与串联字符串
问题内容: 我在node.js中运行它: 我不明白的是为什么为什么要“漂亮地打印”对象,而字符串连接却“丑陋地打印”对象。更重要的是,使它打印的最佳方法是什么? 问题答案: 将对象强制转换为字符串,即: http://jsfiddle.net/Ze32g/ 漂亮的打印是一个很好的,可能非常复杂的基础代码,有人将其作为对象和方法的一部分来实现。 试试这个:
-
MySQL-关于联接的特定列?
问题内容: 进行联接时(内部,左外部,右外部或其他),如何指定表中的哪些列联接到原始表中? 考虑以下示例: 这将从用户中选择FirstName,但从Provider中选择所有内容。如何指定结果集中应包括提供商的哪些部分? 问题答案: 这将只包括 与最终结果集:
-
在AngularJS中使用内联模板
问题内容: 我想加载一个内联视图模板。 我将模板包装在类型为的脚本标签中,并将ID设置为。这是我的模块配置 它在控制台窗口中告诉我,这意味着它正在寻找该名称的文件。 我的问题是:如何配置路由以使用嵌入式模板? 更新:这是我的服务器渲染的DOM的样子 问题答案: Ody,您的方向正确,唯一的问题是标记位于使用指令的DOM元素 之外。如果将其移至元素,则内联模板应该可以使用。