《烽火通信面试》专题
-
 深信服hr面凉经(已offer)
深信服hr面凉经(已offer)25min 没有自我介绍 1.做项目遇到困难怎么解决 2.最有成就感的事 3.到岗时间 4.实习时间 5.之后还有没有课 后面忘了 说今天内给结果,是不是凉了呀呜呜呜呜
-
 7.10长城信息前端一面
7.10长城信息前端一面1、自己常用的布局技术,以及应用场景 2、浅拷贝和深拷贝的区别 3、linux常用的命令有哪些 4、使用过的性能优化手段 5、考虑过哪些浏览器兼容性 6、了解过哪些攻击方式 7、在开发中对安全性有哪些考虑 8、localstorage、sessionstorage、cookie的区别 9、js的数据类型有哪些 10、数组常用的方法有哪些 11、对闭包的理解 12、共享屏幕展示自己的项目 13、项目
-
 3.19 南瑞信息安全一面
3.19 南瑞信息安全一面主要在聊项目聊了半小时,岗位是大模型安全应用的落地 transformer原文读过没? 使用pytorch一般干嘛? 用的什么开源大模型? java反序列化接触过没? hook用来干嘛? 为什么用soot不用codeqr? 有哪些方面是没问到的? 南大软件分析课程看过吗? hr 面 有无offer、期望薪资 3.29 突然就接到电话约签三方了。。。说是江苏那边的政策,学历满足了一定条件可以免笔试。
-
 亚信科技电话面-凉经
亚信科技电话面-凉经#非技术2024笔面经# 3.11发简历,3.13晚上直接打的电话进来,全程大概20分钟 要求业务面线下,不太想去就无后续了 1.简单做个自我介绍 2.目前可以实习多久,一周几天,现住地在哪,到岗时间如何 3.为什么想做产品经理,你觉得产品经理需要哪些特质 4.了解整个产品的生命周期么 5.有没有实战画过原型图,写过PRD 6.讲一下PRD里面应该包含什么要素或者内容,原型图画的怎么样,高保真还是
-
 5.14北京亚信2一面 oc
5.14北京亚信2一面 oc自我介绍 主要拷打项目 然后就是一下线程的问题 什么时候会用到多线程 如何实现多线程等等 springcloud五大组件用什么 反问 #Java##后端开发##实习##26届找工作求助阵地#
-
 北大信研院 后端一面
北大信研院 后端一面1.自我介绍 2.有没有用过抽象类,对它的了解是什么 3.了解注解吗,举一个写过的自定义注解的例子 4.对动态代理了解吗,说一下jdk动态代理 5.有没有用过设计模式,分别说一下发布订阅模式和观察者模式 6.你认为RocketMQ是有序的还是无序的,是如何保证消息的顺序性的 7.HashSet了解吗,是怎样保证元素不重复的 8.线程池有哪些参数,在你具体实践中是怎么用的 9.新建了一个Spring
-
 深信服售前产品面经
深信服售前产品面经之前秋招面的,现在记录一下问题 群面题目:游艇破了,直升机去救援,但是每次只能救一个人,总共8个人,请给出营救顺序并说明原因。 一面(20min): 1、自我介绍 2、说一下以往的经历中遇到的比较大的困难以及自己是怎么解决的? 3、你的优缺点是什么? 4、了解售前产品经理的工作内容吗? 5、个人的1-3年的职业规划是怎样的? 很遗憾没有走到后续#产品面经#
-
 微信支付算法一面挂
微信支付算法一面挂🕒岗位/面试时间:微信支付风控算法/2024.8.28 上来面试官介绍说这边是微信支付部门做风控的,跟我以前的经历可能不太一样,问我有意愿吗?我当然回答愿意。 随后给我出了两道题, 第一道是有序数组找到target所在的左端点以及右端点,用两次二分解出来; 第二道是汽车加油问题,这道面试官只用我说思路,我说了常规的o(n)解法,然后还问有更简单的方法吗,我说没了(也确实没有更简单的了?)。 随后
-
 深信服测开社招面经
深信服测开社招面经时间线: 2024年1月4日 目前在等待一面结果 一面内容: 面试官迟到十分钟,刚准备给HR打电话,面试官进来了 1、自我介绍 2、手画自己开发的测试提效平台架构 因为面试官迟到这么久,加上给面试官讲解他总是误解,把自己快给讲急眼了,最后才给他讲明白了 3、接口自动化,难点是什么?断言校验的正则如何编写?然后给出了几个正则的匹配,让现场写 4、项目拷打 5、算法题 括号合法性校验,输入除了各种括号
-
 南京亚信 java实习面经
南京亚信 java实习面经java中常见集合 说一下HashMap的实现 mysql中的索引 mysql有哪些引擎 对innoDB的理解 spring中的ioc和aop 讲一下后端项目你实现的用户模块是怎么设计的 大二就出来实习没问题吗,能实习多久 凉,1二本比不过广西大学 2一定要说自己能实习6个月
-
 奇安信 暑期售前一面
奇安信 暑期售前一面分享一下 首先自我介绍 答:专业,校园经历,性格,意向 你对公司有什么了解? 答:行业和产品,客户,行业地位,竞争对手 你对岗位有什么了解? 答:解决方案输出,沟通前后端 专业好像不太符合? 答:工科背景,有编程经验,表达愿意去学习的意愿 你对自己有什么样的职业发展规划? 答:希望从事toB售前,数字和科技行业 是否主持或组织过活动? 答:团支书 辩论队 实习期间导师找该怎么办? 答:实验室氛围宽
-
 5.12 普元信息 前端一面
5.12 普元信息 前端一面1.自我介绍➕项目介绍,碰到过哪些难点,难点怎么解决 2.类式组件和函数组件的不同,函数组件有什么优点 3.函数组件中的生命周期 4.es6常见特性 5.promise常用方法,了解过a+标准么 6.父组件怎么拿到子组件的方法 7.git中的冲突合并、版本同步
-
 4.26安恒信息 前端一面
4.26安恒信息 前端一面电话面 1.自我介绍 2.介绍项目 3.讲下Promise和async await 4.事件执行队列 5.事件代理 6.react组件间常见通信方式 7.es6常用语法 8.说下es6中的proxy 9.跨域解决方案 10.git常用命令 11.http常见状态码 大多数都是基础八股文,说了会有二面,一个星期也没接到,估计是🈚️了
-
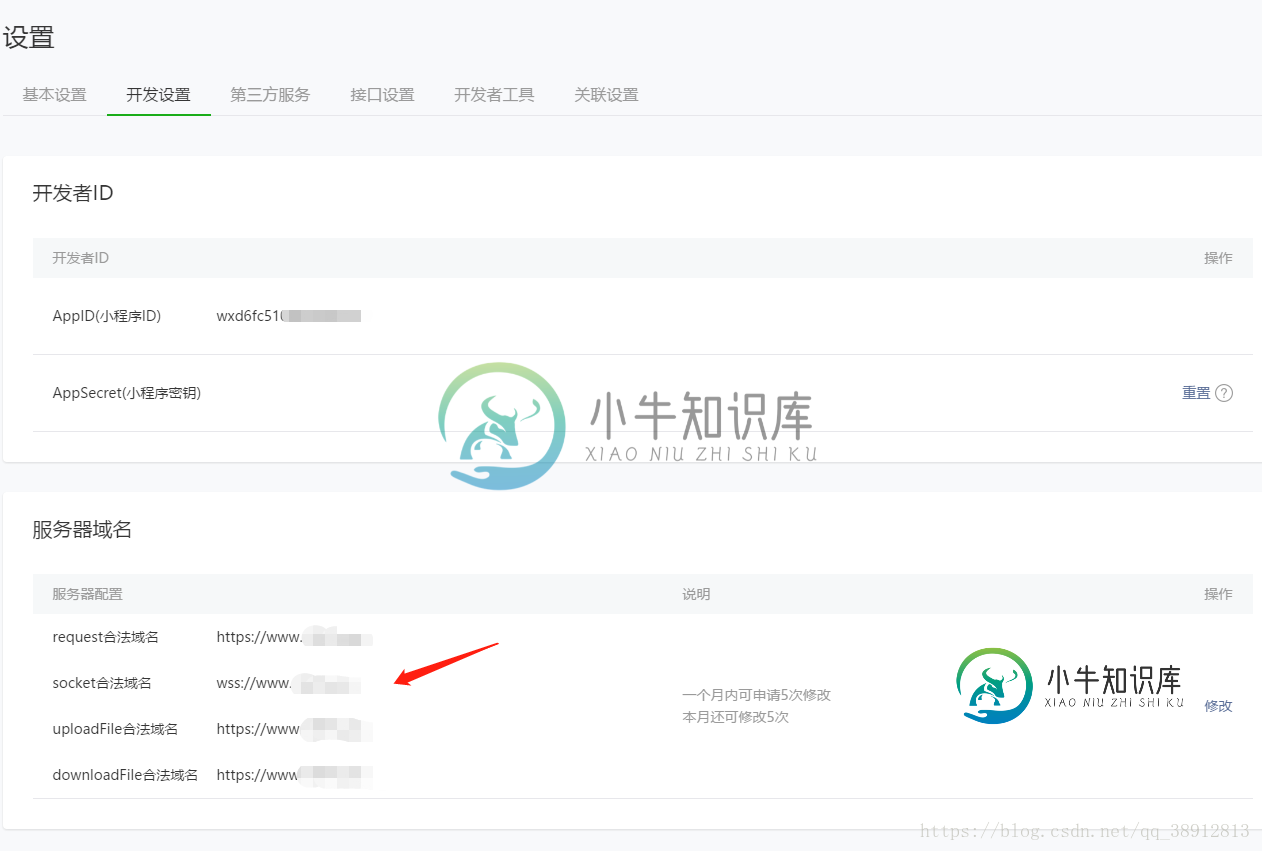 微信小程序实现即时通信聊天功能的实例代码
微信小程序实现即时通信聊天功能的实例代码本文向大家介绍微信小程序实现即时通信聊天功能的实例代码,包括了微信小程序实现即时通信聊天功能的实例代码的使用技巧和注意事项,需要的朋友参考一下 项目背景:小程序中实现实时聊天功能 一、服务器域名配置 配置流程 配置参考URL:https://developers.weixin.qq.com/miniprogram/dev/api/api-network.html 二、nginx中配置反向代理加密w
-
 小鹅通日常实习一面(积累面试经验)
小鹅通日常实习一面(积累面试经验)1.自我介绍 2.为什么要学前端 3.学习的路线,有没有在网上看别人的学习路线 4.介绍一下在之前实习做的项目(文件流和其他请求请求头和请求体的区别) 5.http请求用的是库还是自己定义的,用的axios库的底层原理是什么,ajax的请求的步骤 6.axios返回的是promise对象,介绍一下promise 7.const p=new Promise(()=>{ console.log