
OpenFlamingo 的核心是一个支持大型多模态模型 (LMM) 训练和评估的框架,DeepMind 的 Flamingo 模型的开源复制品。
主要包含如下内容:
- 一个用于训练 Flamingo 风格 LMM 的 Python 框架(基于 Lucidrains 的 flamingo 实现和 David Hansmair 的 flamingo-mini 存储库)。
- 具有交错图像和文本序列的大规模多模态数据集。
- 视觉语言任务的上下文学习评估基准。
- OpenFlamingo-9B 模型(基于 LLaMA )的第一个版本
OpenFlamingo 架构如下图,使用交叉注意力层来融合预训练的视觉编码器和语言模型。
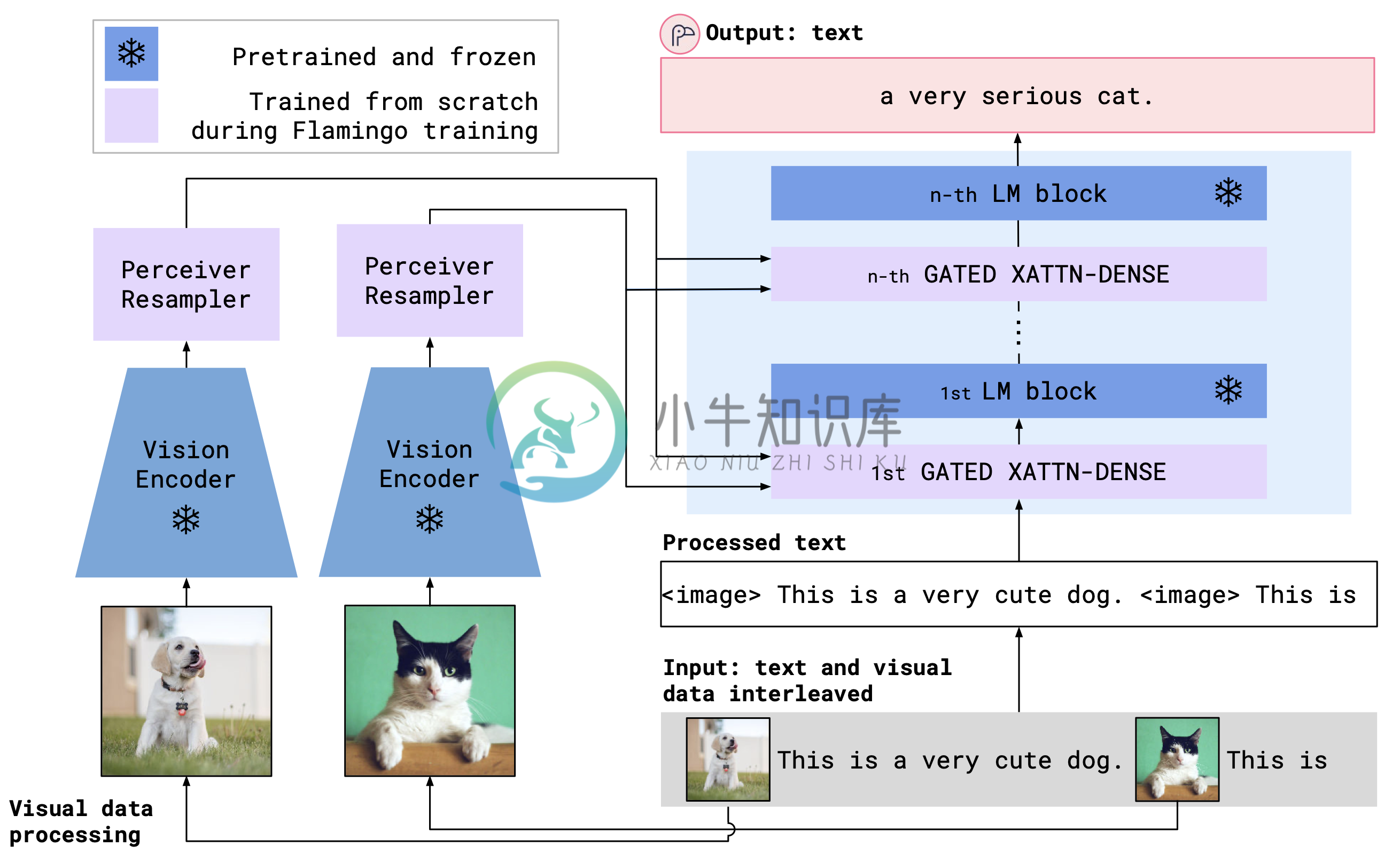
安装
要在现有环境中安装包,请运行
pip install open-flamingo
或者创建运行 OpenFlamingo 的 conda 环境,运行
conda env create -f environment.yml
用法
我们使用 CLIP ViT-Large 视觉编码器和 LLaMA-7B 语言模型提供初始OpenFlamingo 9B 模型。一般来说,我们支持任何CLIP 视觉编码器。对于语言模型,我们支持LLaMA 、OPT 、GPT-Neo 、GPT-J和Pythia模型。
注意:要使用 LLaMA 模型,您需要通过以下方式安装最新版本的变压器
pip install git+https://github.com/huggingface/transformers
使用此脚本将 LLaMA 权重转换为 HuggingFace 格式。
初始化 OpenFlamingo 模型
from open_flamingo import create_model_and_transforms
model, image_processor, tokenizer = create_model_and_transforms( clip_vision_encoder_path="ViT-L-14", clip_vision_encoder_pretrained="openai", lang_encoder_path="", tokenizer_path="", cross_attn_every_n_layers=4 )
grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download import torch
checkpoint_path = hf_hub_download("openflamingo/OpenFlamingo-9B", "checkpoint.pt") model.load_state_dict(torch.load(checkpoint_path), strict=False)
生成文本
这是一个以交错图像/文本为条件生成文本的示例,在这种情况下将进行少镜头图像字幕。
from PIL import Image
import requests
""" Step 1: Load images """ demo_image_one = Image.open( requests.get( "http://images.cocodataset.org/val2017/000000039769.jpg", stream=True ).raw )
demo_image_two = Image.open( requests.get( "http://images.cocodataset.org/test-stuff2017/000000028137.jpg", stream=True ).raw )
query_image = Image.open( requests.get( "http://images.cocodataset.org/test-stuff2017/000000028352.jpg", stream=True ).raw )
""" Step 2: Preprocessing images Details: For OpenFlamingo, we expect the image to be a torch tensor of shape batch_size x num_media x num_frames x channels x height x width. In this case batch_size = 1, num_media = 3, num_frames = 1 (this will always be one expect for video which we don't support yet), channels = 3, height = 224, width = 224. """ vision_x = [image_processor(demo_image_one).unsqueeze(0), image_processor(demo_image_two).unsqueeze(0), image_processor(query_image).unsqueeze(0)] vision_x = torch.cat(vision_x, dim=0) vision_x = vision_x.unsqueeze(1).unsqueeze(0)
""" Step 3: Preprocessing text Details: In the text we expect an special token to indicate where an image is. We also expect an <|endofchunk|> special token to indicate the end of the text portion associated with an image. """ tokenizer.padding_side = "left" # For generation padding tokens should be on the left lang_x = tokenizer( ["An image of two cats.<|endofchunk|>An image of a bathroom sink.<|endofchunk|>An image of"], return_tensors="pt", )
""" Step 4: Generate text """ generated_text = model.generate( vision_x=vision_x, lang_x=lang_x["input_ids"], attention_mask=lang_x["attention_mask"], max_new_tokens=20, num_beams=3, )
print("Generated text: ", tokenizer.decode(generated_text[0]))
方法
OpenFlamingo 是一种多模态语言模型,可用于多种任务。它在大型多模态数据集(例如 Multimodal C4)上进行训练,可用于生成以交错图像/文本为条件的文本。 例如,OpenFlamingo 可用于为图像生成标题,或根据图像和文本段落生成问题。这种方法的好处是我们能够使用上下文训练快速适应新任务。
模型架构
OpenFlamingo 寻求使用交叉注意力层来融合预训练的视觉编码器和语言模型。模型架构如下图所示。
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
问题内容: 我想知道是否有可能保存经过部分训练的Keras模型并在再次加载模型后继续进行训练。 这样做的原因是,将来我将拥有更多的训练数据,并且我不想再次对整个模型进行训练。 我正在使用的功能是: 编辑1:添加了完全正常的示例 对于10个纪元后的第一个数据集,最后一个纪元的损失将为0.0748,精度为0.9863。 保存,删除和重新加载模型后,第二个数据集上训练的模型的损失和准确性分别为0.171
-
大家已经提到了这个,这个,这个和这个,但是仍然发现很难建立一个自定义的名字查找器模型。。以下是代码: 我在尝试执行命令行时不断出现错误: 让我把论点1改为 然后我收到一个运行时错误,说你不能强制转换这个。这是我在线程“main”中强制转换 第二个问题是: 给出一个语法错误。不确定这里出了什么问题。如果有任何帮助,我将不胜感激,因为我已经尝试了上述链接上的所有代码片段。 祝好
-
我试图用下面的代码训练模型,但我一直在方法上收到错误,它告诉我将更改为。为什么?
-
利用 Polar 应用程式、Polar Flow 应用程式以及 Polar Flow 网络服务获得有关您的训练的即时分析,深入了解您的训练。 M600 上的训练总结 在每次训练后,您将在您的手表上收到您的即时训练总结。 总结中显示的信息取决于运动内容。可提供的细节包括: 时间长度:训练时长 距离(如适用于您的运动):指训练中已完成的距离。 平均心率:指训练期间您的平均心率。 最大心率:指训练期间您