《综合面》专题
-
 Oracle合并数据
Oracle合并数据主要内容:Oracle MERGE语句简介,Oracle MERGE示例在本教程中将学习如何使用Oracle 语句来执行更新或基于指定条件插入数据。 Oracle MERGE语句简介 Oracle 语句从一个或多个源表中选择数据并更新或将其插入到目标表中。 语句可指定一个条件来确定是更新数据还是将数据插入到目标表中。 以下说明了Oracle 语句的语法: 下面来仔细看看上面语句的语法: 首先,指定要在子句中更新或插入的目标表()。 其次,指定要更新或插入子句中的数据源
-
 JSF复合组件
JSF复合组件主要内容:实例JSF通过Facelets提供复合组件(有点类似于)的概念。复合组件是一种特殊类型的模板,它充当应用程序中的一个组成部分。 复合组件由标记标签和其他现有组件组成。 这个可重复使用的用户创建的组件具有定制的定义功能,并且可以像任何其他组件一样具有连接到它的验证器,转换器和监听器。 包含标记标签和其他组件的任何XHTML页面都可以转换为复合组件。 以下表格包含复合标签以及说明 - 标签 功能 它用于声
-
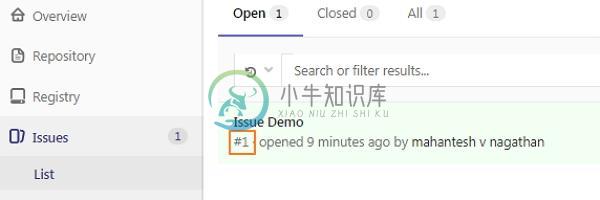 GitLab合并请求
GitLab合并请求GitLab可以引用提交消息中的特定问题来解决特定的问题。 在本章中,我们将讨论如何在GitLab中引用问题: 步骤(1): 要引用问题,您需要创建问题的问题编号。 要创建问题,请参阅创建问题章节。 步骤(2): 要查看创建的问题,请单击Issues选项卡下的List选项: 步骤(3): 在对本地存储库进行更改之前,请使用以下命令检查它是否为最新版本: 命令从远程服务器下载最新的更改并直接集成到当
-
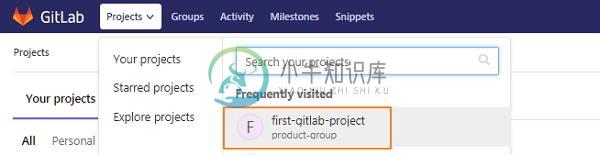 GitLab合并请求
GitLab合并请求主要内容:合并请求的步骤合并请求可用于对项目其他人员之间所做的代码进行交换,与他们讨论更改。 合并请求的步骤 步骤(1): 在创建新的合并请求之前,应该在GitLab中创建一个分支。 您可以参考本章创建分支: 步骤(2): 登录到您的GitLab帐户并转到项目部分下的项目: 步骤(3): 点击选项卡,然后点击New merge request 按钮: 步骤(4): 要合并请求,请从下拉列表中选择源分支和目标分支,然后单击
-
Java 集合排序
主要内容:1 集合元素的排序,2 Collections sort方法,3 字符串正序排序,4 字符串倒序排序,5 包装类型排序,6 自定义对象排序1 集合元素的排序 我们可以对以下元素进行排序: 字符串对象 包装类对象 用户自定义对象 Collections类提供用于对集合的元素进行排序的静态方法。如果集合元素为Set类型,则可以使用TreeSet。但是,我们无法对List的元素进行排序。Collections类提供用于对List类型元素的元素进行排序的方法。 2 Collections so
-
结合静态库
问题内容: 假设我有三个 C 静态库,它们说 libColor.a 取决于 libRGB。 a,而后者又取决于 libPixel.a 。据说库 libColor.a 依赖于库 libRGB.a, 因为 libColor.a中 有对 libRGB.a 中定义的某些符号的 引用 。如何将上述所有库合并到独立的新 libNewColor.a ? 独立意味着新库应已定义所有符号。因此,在链接时,我只需要给
-
结合ListActivity和ActionBarActivity
问题内容: 我目前的构建数量至少为10,因此我必须使用该库来实现。我已经设置了,但是我现在要添加一个,但是这需要扩展我的类,Java没有多个。我该怎么办? 问题答案: ListActivity尚未移植到AppCompat。可能是因为您应该认为它“已弃用”,而改用ListFragment。 片段将与ActionBarActivity一起使用,只需确保它们是支持库中的片段即可。 要通过读这大约片段的链
-
获取组合键
问题内容: 如何获得Java 键盘EG(+ ,+ )上的按键组合? 我使用监听器,键盘上所有按键的监听器。我可以使用该监听器捕获键盘上的所有按键事件。但是,我无法捕捉到(+ + )....等组合键。 问题答案:
-
 众合科技9.7
众合科技9.7众合科技 1.硕士期间的项目,合作项目内容,负责部分 2.学校期间上课有没学过Java 3.平时的学习方式是什么 4.mq有学过吗? 5.假如要你学习kafka你会怎么学习? 6.学习完你觉得会产出什么? 7.项目问题 8.TCP为什么是四次挥手,挥手为什么多一次? 9.操作系统中,进程线程有什么关系? 10.Java的基础类型有哪些?占多少字符? 11.JDBC的基础流程? 12.项目中用到的集
-
Spark Streaming 整合 Kafka
一、版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下: spark-streaming-kafka-0-8 spark-streaming-kafka-0-10 Kafka 版本 0.8.2.1 or higher 0.10.0 or higher A
-
Spark Streaming 整合 Flume
一、简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中。Spark Straming 提供了以下两种方式用于 Flume 的整合。 二、推送式方法 在推送式方法 (Flume-style Push-based Approach) 中,Spark Streaming 程序需要对某台服务器的某个端口进行监听,Fl
-
C# 高级 - 集合
集合类专门用于数据存储和数据检索,并提供堆栈、队列、列表和哈希表的支持。目前,大多数集合类都实现了相同的接口。 集合类服务于不同的目的,如为元素动态分配内存,基于索引访问列表项等等,这些类所创建的是 Object 类的对象的集合。在 C# 中,Object 类是所有数据类型的基类。 各种集合类及其用法 下表为一些常用的以 System.Collection 为命名空间的集合类,点击相应链接,可查看
-
分布式集合
Map Redisson 分布式的 Map 对象,实现了 java.util.concurrent.ConcurrentMap 和 java.util.Map 接口。 Map 的大小由 Redis 限制为 4 294 967 295。 RMap<String, SomeObject> map = redisson.getMap("anyMap"); SomeObject prevObject =
-
2.1.6 Java集合——LinkedHashMap
一、 概述 在理解了HashMap后,我们来学习LinkedHashMap的工作原理及实现。首先还是类似的,我们写一个简单的LinkedHashMap的程序: LinkedHashMap<String, Integer> lmap = new LinkedHashMap<String, Integer>(); lmap.put("语文", 1); lmap.put("数学", 2); lmap.p
-
2.1.5 Java集合——TreeMap
一、概述 A Red-Black tree based NavigableMap implementation. The map is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time, depending on which construct