《综合面》专题
-
ElasticSearch术语聚合
问题内容: 我正在尝试使用以下查询对以下数据进行elasticsearch来执行术语聚合,输出将名称分解为标记(请参见下面的输出)。因此,我尝试将os_name映射为multi_field,但现在无法通过它查询。是否可以有没有令牌的索引?例如“ Fedora Core”? 查询: 数据: 输出: 映射: 问题答案: 实际上,您应该像这样更改映射 并且您的aggs应该更改为:
-
Java Commons集合removeAll
问题内容: CollectionUtils :: removeAll()公用集合3.2.1 我一定要疯了,因为似乎此方法正在做与文档状态相反的操作: 从集合中移除remove中的元素。也就是说,此方法返回一个集合,其中包含c中所有不在remove中的元素。 这个小小的JUnit测试 失败了 java.lang.AssertionError:预期:<2>,但之前是:<1> 和印刷品 通过阅读文档,我
-
混合synced()与ReentrantLock.lock()
问题内容: 在Java中,这样做并使用相同的锁定机制? 我的猜测是“不”,但我希望是错的。 例: 想象一下,线程1和线程2都可以访问: 线程1运行: 线程2运行: 假设线程1首先到达其部分,然后在线程1完成之前到达线程2:线程2将等待线程1离开该块,还是继续运行? 问题答案: 不,即使线程1 在同一线程上,线程2也可以。这是文档必须说的: 请注意,Lock实例只是普通对象,它们本身可以用作同步语句
-
C++:组合模式
将对象组合成树形结构以表示“部分整体”的层次结构。Composite使得用户对单个对象和组合对象的使用具有一致性(稳定)。 class Component { public: virtual void process() = 0; virtual ~Component() {} }; //树节点 class Composite : public Component { string name
-
SQL集合操作
主要内容:联合 - Union,2. 全联合 - Union All,3. 相交,4. 差集SQL集合操作用于组合两个或多个SQL SELECT语句。 集合操作的类型 联合 - Union 联合所有 - UnionAll 交集 - Intersect 差集 - Minus 联合 - Union SQL 操作用于组合两个或多个SQL 查询的结果。 在操作中,在应用操作的两个表中,所有数据类型和列的数量必须相同。 操作从结果集中删除重复的行。 语法 假设有两个表,第一个表:First 的结构
-
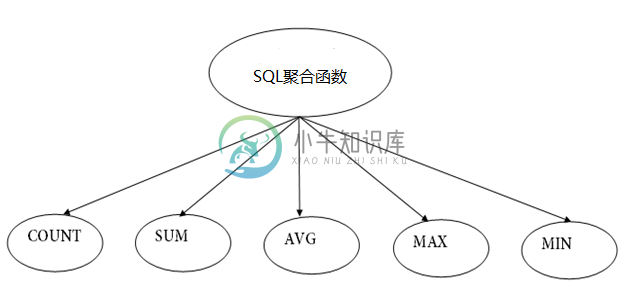 SQL聚合函数
SQL聚合函数主要内容:1.COUNT函数,2. SUM函数,3. AVG函数,4. MAX函数,5. MIN函数SQL聚合函数用于对表的单个列的多行执行计算,它只返回一个值。它还用于汇总数据。 SQL聚合函数的类型,如下图所示 - 接下来,我们一个个地讲解。 1.COUNT函数 函数用于计算数据库表中的行数,它可以在数字和非数字数据类型上工作。 函数使用返回指定表中所有行的计数。 包函重复值和值。 语法 假设有一个表,它的结构和数据如下所示 - PRODUCT COMPANY QTY RATE COST I
-
ECMAScript/ES6集合/Set
主要内容:1.Set属性,2.Set方法,3.弱集合,4.迭代器集合是一种数据结构,可创建唯一值的集合。 集是处理单个对象或单个值的集合。是类似于数组的值的集合,但不包含任何重复项。它使可以存储唯一值, 它支持原始值和对象引用。 与映射相似,集合也被排序,即集合中的元素按其插入顺序进行迭代。 它返回设置的对象。 语法 通过使用以下示例来理解集合的概念: 集合的所有元素必须唯一。 因此,以上示例中的设置颜色仅包含四个不同的元素。 成功执行以上代码后将获得以下输出
-
Swif哈希集合
Swift 4集合是用于存储相同类型的不同值,但它们没有像数组那样的有明确排序顺序。 如果不需要元素排序,或者需要没有重复值(唯一值),则可以使用集合而不是数组(集合只允许不同的值)。 类型必须是可散列类型并且是可以比较的,才能存储在一个集合中。哈希值是对象的值相等。例如,如果两个对象相等:,则。 默认情况下,所有基本值都是可散列类型,可以用作集合值。 创建集 使用以下初始化语法创建某个类型的空集
-
 Matlab整合集成
Matlab整合集成主要内容:使用MATLAB找到不确定的积分,使用MATLAB查找定积分整合(或也叫作集成)涉及两种本质上不同类型的问题。 第一种类型问题是给出了函数的导数,并且想要找到该函数。所以基本上扭转了差异化的过程。 这种反向过程被称为抗分化,或者找到原始函数,或者找到不确定的积分。 第二种类型问题是涉及相当多的非常小的数量,然后随着数量的大小接近于零,而术语的数量趋向于无穷大。这个过程导致了定积分的定义。 确定的积分用于查找区域,体积,重心,转动惯量,由力完成的工作以及许多
-
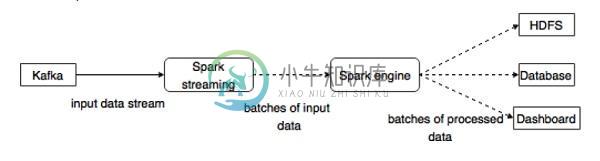 Kafka与Spark整合
Kafka与Spark整合主要内容:Spark是什么?,与Spark整合在本章中,将讨论如何将Apache Kafka与Spark Streaming API集成。 Spark是什么? Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理。 数据可以从Kafka,Flume,Twitter等许多来源获取,并且可以使用复杂算法进行处理,例如:映射,缩小,连接和窗口等高级功能。 最后,处理后的数据可以推送到文件系统,数据库和现场仪表板上。 弹
-
Kafka与Storm整合
主要内容:Storm是什么?,与Storm整合,提交到拓扑在本章中,我们将学习如何将Kafka与Apache Storm集成。 Storm是什么? Storm最初是由Nathan Marz和BackType团队创建的。 在很短的时间内,Apache Storm成为分布式实时处理系统的标准,用于处理大数据。 Storm速度非常快,每个节点每秒处理超过一百万个元组的基准时钟。 Apache Storm持续运行,从配置的源(Spouts)中消耗数据并将数据传递
-
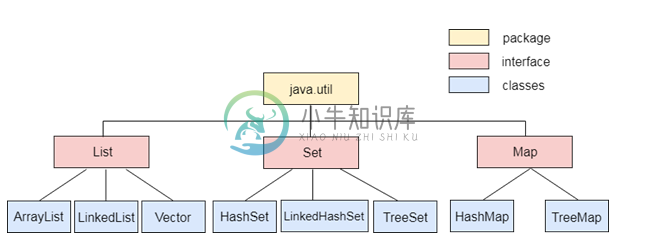 JPA集合映射
JPA集合映射主要内容:集合类型,以下是纠正/补充内容:集合(Collection)是一个将多个对象分组为一个单元的java框架。它用于存储,检索和操作汇总数据。 在JPA中,可以使用集合来持久化包装类和String的对象。JPA允许三种对象存储在映射集合中 - 基本类型,实体和嵌入式类型。 集合类型 根据要求,我们可以使用不同类型的集合来持久化对象。如下所示 - List Set Map 包中包含集合框架的所有类和接口。 以下是纠正/补充内容: 根据
-
TypeScript 联合类型
主要内容:TypeScript,JavaScript,TypeScript,JavaScript,联合类型数组,TypeScript,JavaScript联合类型(Union Types)可以通过管道(|)将变量设置多种类型,赋值时可以根据设置的类型来赋值。 注意:只能赋值指定的类型,如果赋值其它类型就会报错。 创建联合类型的语法格式如下: 实例 声明一个联合类型: TypeScript var val:string|number val = 12 console.log("数字为 "+ val
-
 Vue3 组合式 API
Vue3 组合式 API主要内容:setup 组件,实例(src/APP.vue),实例,Vue 组合式 API 生命周期钩子,实例,实例,实例,模板引用,实例,实例,实例,实例Vue3 组合式 API(Composition API) 主要用于在大型组件中提高代码逻辑的可复用性。 传统的组件随着业务复杂度越来越高,代码量会不断的加大,整个代码逻辑都不易阅读和理解。 Vue3 使用组合式 API 的地方为 setup。 在 setup 中,我们可以按逻辑关注点对部分代码进行分组,然后提取逻辑片段并与其他组件共享代码。因
-
MongoDB固定集合
主要内容:创建固定集合,固定集合查询固定集合是具有固定大小的循环集合,遵循插入顺序,以支持高性能的创建、读取和删除操作。通过循环,当分配给集合的固定大小用完时,它将删除集合中最旧的文档,而不提供任何显式命令。 如果更新导致文档大小增加,则固定集合会限制对文档的更新。由于固定集合是按磁盘存储的顺序存储文档的,因此可以确保文档大小不会增加磁盘上分配的大小。固定集合最适合存储日志信息、缓存数据或任何其他高容量数据。 创建固定集合 要创建一