《python爬虫》专题
-
python爬虫 - Python爬虫WinError 10061连接拒绝问题?
python爬虫时显示 [WinError 10061] 由于目标计算机积极拒绝,无法连接。 import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font
-
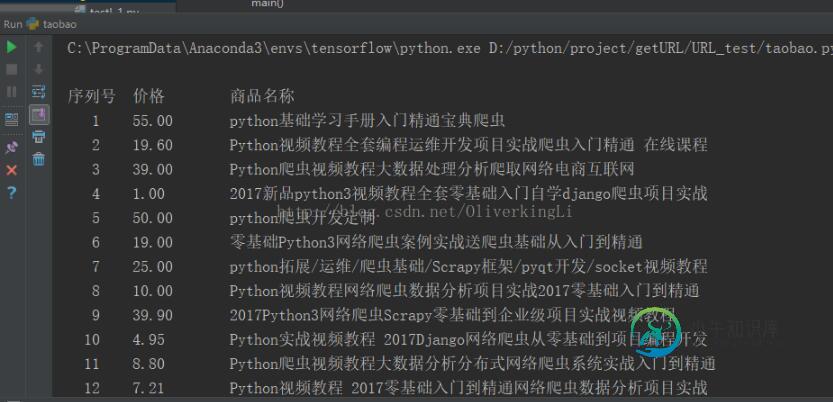 python爬虫爬取淘宝商品信息
python爬虫爬取淘宝商品信息本文向大家介绍python爬虫爬取淘宝商品信息,包括了python爬虫爬取淘宝商品信息的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 效果图: 更多内容请参考专题《python爬取功能汇总》进行学习。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
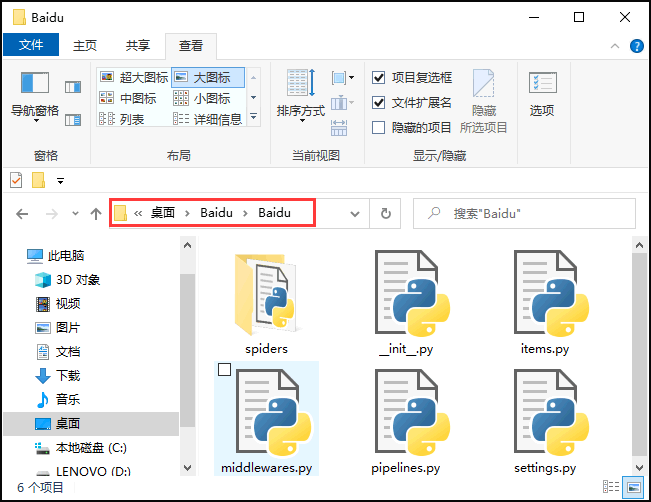 Python Scrapy爬虫框架
Python Scrapy爬虫框架主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
 Python多线程爬虫
Python多线程爬虫主要内容:多线程使用流程,Queue队列模型,多线程爬虫案例网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 IO 以及本地磁盘 IO 操作,这些都会消耗大量的时间,从而降低程序的执行效率,而 Python 提供的多线程能够在一定程度上提升 IO 密集型程序的执行效率。 如果想学习 Python 多进程、多线程以及 Python GIL 全局解释器锁的相关知识,可参考《Python并发编程教程》。 多线程使用流程 Python 提供了两个支持多线
-
python爬虫爬取图片的简单代码
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
Python爬虫:常用的爬虫技巧总结
python应用最多的场景还是web快速开发、爬虫、自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。
-
Python爬虫爬取、解析数据操作示例
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
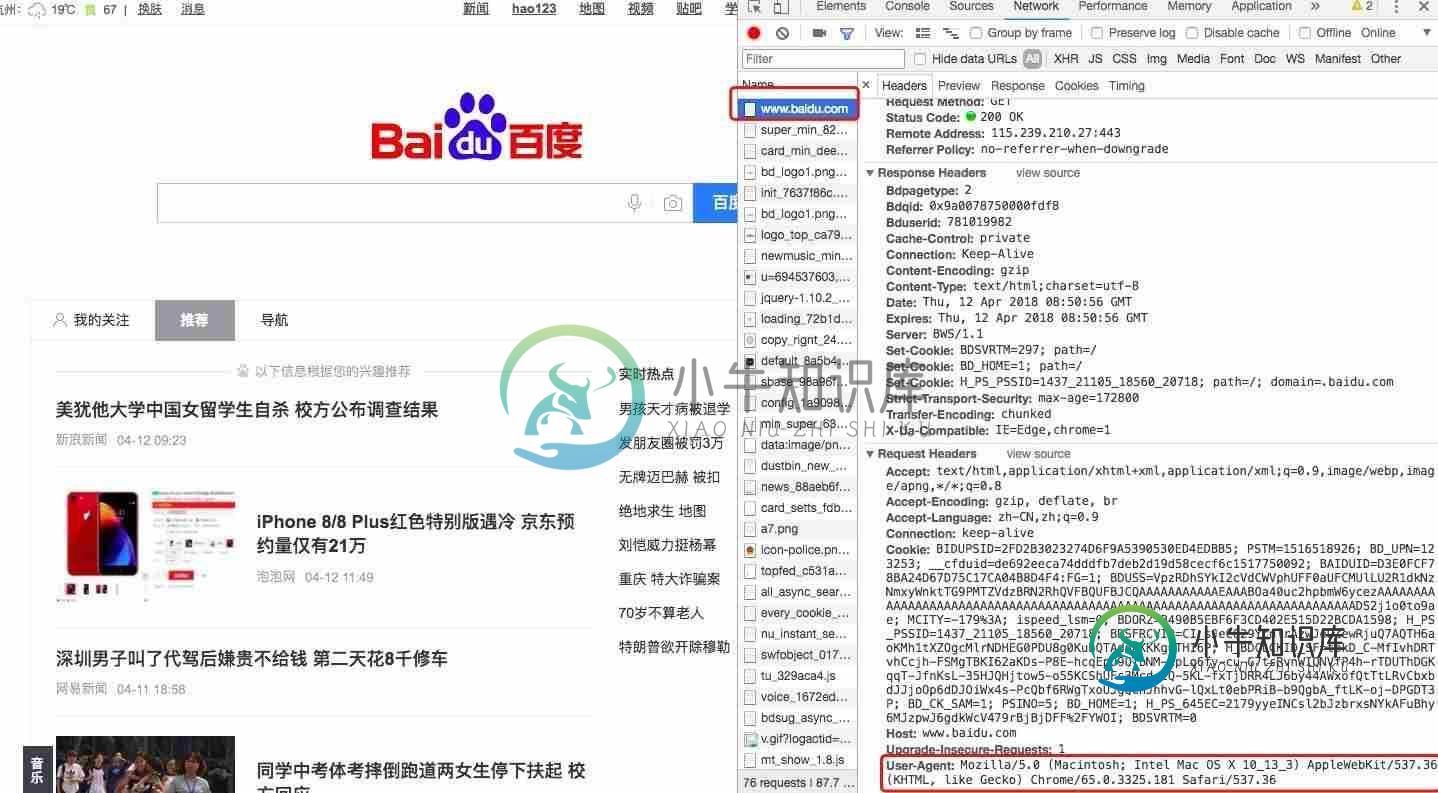 Python反爬虫伪装浏览器进行爬虫
Python反爬虫伪装浏览器进行爬虫本文向大家介绍Python反爬虫伪装浏览器进行爬虫,包括了Python反爬虫伪装浏览器进行爬虫的使用技巧和注意事项,需要的朋友参考一下 对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器--打开开发者模式--请求任意网站 如下图:找到请求的的名字,打
-
 python爬虫爬取某站上海租房图片
python爬虫爬取某站上海租房图片本文向大家介绍python爬虫爬取某站上海租房图片,包括了python爬虫爬取某站上海租房图片的使用技巧和注意事项,需要的朋友参考一下 对于一个net开发这爬虫真真的以前没有写过。这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup。python 版本:python3.6 ,IDE :pycharm
-
 Python爬虫爬取新闻资讯案例详解
Python爬虫爬取新闻资讯案例详解本文向大家介绍Python爬虫爬取新闻资讯案例详解,包括了Python爬虫爬取新闻资讯案例详解的使用技巧和注意事项,需要的朋友参考一下 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采
-
python爬虫容易学吗
本文向大家介绍python爬虫容易学吗,包括了python爬虫容易学吗的使用技巧和注意事项,需要的朋友参考一下 随着大数据时代的到来,数据将如同煤电气油一样,成为我们最重要的能源之一,然而这种能源是可以源源不断产生、可再生的。而Python爬虫作为获取数据的关键一环,在大数据时代有着极为重要的作用。于是许多同学就前来咨询:Python爬虫好学吗? 什么是爬虫? 网络爬虫,又被称为网页蜘蛛,网络机器
-
 Python 原生爬虫教程
Python 原生爬虫教程网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
-
 Python爬虫:通过关键字爬取百度图片
Python爬虫:通过关键字爬取百度图片本文向大家介绍Python爬虫:通过关键字爬取百度图片,包括了Python爬虫:通过关键字爬取百度图片的使用技巧和注意事项,需要的朋友参考一下 使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一。搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输
-
 Python爬虫爬取美剧网站的实现代码
Python爬虫爬取美剧网站的实现代码本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷
-
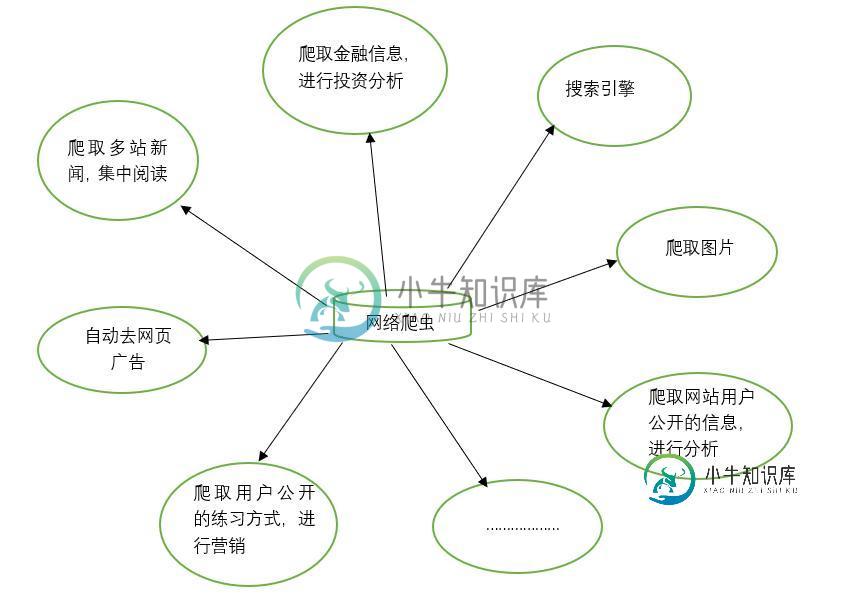 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以