《美的群面》专题
-
 美的笔试c++,AC
美的笔试c++,AC第一题求字符串排列组合,结果要求升序,回朔+去重解决。 第二题将某个特定值全部移到结尾不改变顺序,原地双指针,打卡题。
-
 美的数分笔试
美的数分笔试不总结的笔试面试等于白做,最近的教训 三类题 1,20单选。主要是hadoop组件基础知识 2,5不定项选择。也是大数据基础知识 3,三个sql(一个窗口函数,一个基础,一个分组拼接) 第二个sql用例过了,提交0
-
 美团
美团美团平台 9/04 复活赛一面 前面主要问项目 tcp三次握手 redis缓存雪崩 有的八股忘了 问我Linux,我说用的少不怎么会就没问了 问了不到20分钟开始写题 一个mysql 算法删除链表中的重复元素|| 反问 感觉面试官有点急,问了没一会就做题了20分钟都没问到就让我写题 面完秒挂 问的我基本都回答上了,算法也写出来了 #美团求职进展汇总# #我的失利项目复盘# #秋招#
-
使用Wildfly的集群式Singleton?
问题内容: 我正在尝试在Wildfly 8.2上创建一个简单的集群。我已经配置了2个Wildfly实例,它们以独立的群集配置运行。我的应用程序已部署到这两个应用程序,并且我可以毫无问题地访问它。 我的集群EJB如下所示: …并且我编写了一个非常简单的RESTful服务,让我可以通过浏览器调用这些方法… 我可以从单个Wildfly实例中调用和方法,并获得预期值。但是,如果我尝试从一个实例调用poke
-
 Redis集群的相关详解
Redis集群的相关详解本文向大家介绍Redis集群的相关详解,包括了Redis集群的相关详解的使用技巧和注意事项,需要的朋友参考一下 注意!要求使用的都是redis3.0以上的版本,因为3.0以上增加了redis集群的功能。 1.redis介绍 1.1什么是redis Redis是用C语言开发的一个开源的高性能键值对(key-value)的非关系型数据库。通过多种键值数据类型来适应不同场景下的存储需求,目前支持的键值数
-
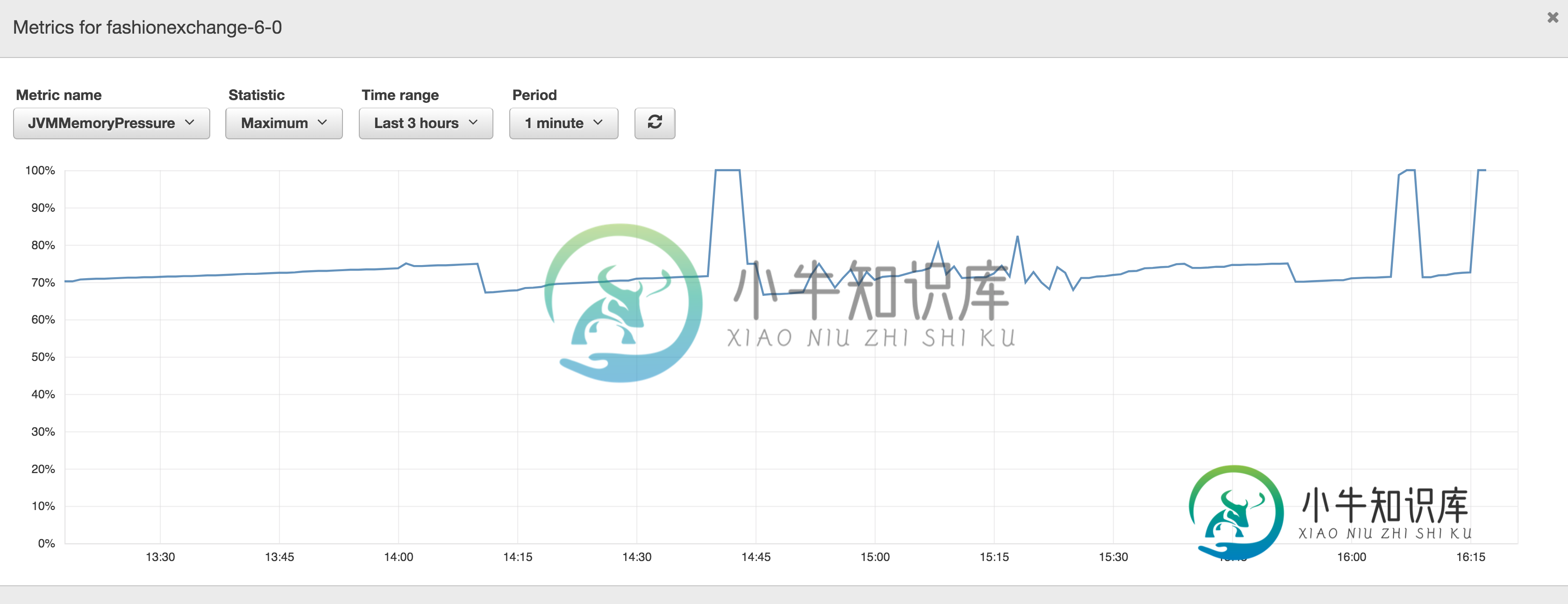 AWS ElasticSearch群集的堆大小
AWS ElasticSearch群集的堆大小我有一个AWS ElasticSearch T2.Medium实例,有两个节点在运行,几乎没有任何负载。但它一直在崩溃。 我看到了度量JVMMemoryPressure的以下图表: 当我去吉巴纳的时候,我看到下面的错误信息: 问题: 计算机只有64 MB可用内存,而不是应该与此实例类型关联的4 GB可用内存,我的解释正确吗?是否有其他地方来验证堆内存的绝对量,而不是只在Kibana出错时才在其上验
-
集群环境中的Spring Scheduler
我使用Spring调度程序,使用@调度注释来调度运行文件生成服务的作业。应用程序部署在集群环境中Tomcat的5个单独节点上,用于负载平衡和故障转移。正因为如此,服务被调度了5次,这是不可能的。有没有办法将调度程序配置为仅在当前节点上运行? 有一种方法使用数据库找出当前活动节点,并在这里调用该特定实例的调度器 另一种方法是使用石英调度器 由于我无法对部署的应用程序进行重大更改,是否有简单的解决方案
-
集群环境中的单例
问题内容: 将Singleton对象重构到集群环境的最佳策略是什么? 我们使用Singleton从数据库中缓存一些自定义信息。它 主要是 只读的,但是在发生某些特定事件时会刷新。 现在,我们的应用程序需要部署在集群环境中。根据定义,每个JVM将具有自己的Singleton实例。因此,当在单个节点上发生刷新事件并且刷新其缓存时,JVM之间的缓存可能不同步。 保持缓存同步的最佳方法是什么? 谢谢。 编
-
集群模式下的Redis流
Redis streams是否受益于群集模式?假设您有10个流,它们是分布在集群中还是全部分布在同一个节点上?我计划使用Redis streams实现真正的高吞吐量(每秒200万条消息),因此我担心Redis streams在这种规模下的性能。 如果Redis streams不能在集群模式下进行开箱即用的扩展,那么任何关于水平扩展Redis streams的指导都会非常棒。
-
Hazelcast群集中的错误TargetException
我正在使用hazelcast集群的两个成员运行一个POC,使用3.4.1版本的hazelcast。我观察到一个奇怪的行为,其中一个成员不断抛出WrongTargetException。这是一个罕见的场景,我能够通过以下事件序列复制: 假设我运行的集群有两个成员,比如X和Y。 从集群中拔出Y,使其变得无响应。 X认为Y没有响应,因此将其从集群中删除。 再次插入Y,Y假设它没有收到来自X的任何响应/心
-
Kubernetes集群上的Jenkins安装
我正试图在我的kubernetes集群中安装Jenkins。当我探索的时候,我发现有两个方面。我理解的第一种方法是,安装詹金斯主从。在这里,我找到了在kubernetes集群上安装Jenkins主从代理的文档。第二种方法是我发现Kubernetes插件的用法。如果我们用这种方法,只需要安装master和配置插件。当创建一个部署时,从吊舱将自动工作。 在第一种方法中,我们需要定义安装主从机的工作机器
-
MariaDB Galera集群的DR设置
使用GTID的异步复制已在MDB-01到MDBDR-01之间设置,按照以下链接中的给定配置:http://www.severalnines.com/blog/deploy-asynchronous-replication-slave-mariadb-galera-cluster-gtid-clustercontrol(链接是MariaDB Galera Cluster之间的异步复制,以独立的Mar
-
带Zookeeper的集群监视器
我正在尝试用CuratorFramework创建一个基于动物园管理员的应用程序。该应用程序必须能够在更多的节点上以仲裁的方式运行。应用程序的每个实例都嵌入了动物园管理员服务器和客户端的实例。节点在仲裁中被成功地删除。每个节点都向 /workers/active/node1写入一个EPHEMERAL节点(“活动”是由领导者创建的PERSISTENT znode)。因为当客户端连接到动物园管理员服务器
-
JavaHadoop Kerberize群集的Http请求
我需要发送Http请求到Hadoop群集与Kerberos授权,我想与Keytab进行身份验证。我发现一个库HttpClient的Apache和我写了这个代码来获得HttpClient: 但我只能在对KeyTab执行Kinit命令后进行身份验证。如何在httpclient中传递密钥表的路径?你知道其他图书馆也能做到这一点吗?
-
2Kafka集群的SpringKafka消费者
我在站点1(3个代理)有两个集群设置cluster-1,在站点2(3个代理)有两个集群设置cluster-2。使用spring kafka(1.3.6)消费者(一台机器)并通过@KafkaListener注释收听消息。我们如何为每个集群(c1和c2)实例化多个KafkaListenerContainerFactory,并同时监听来自这两个集群的数据。 我的侦听器应该同时使用来自这两个集群的消息。