《龙湖集团数字科技》专题
-
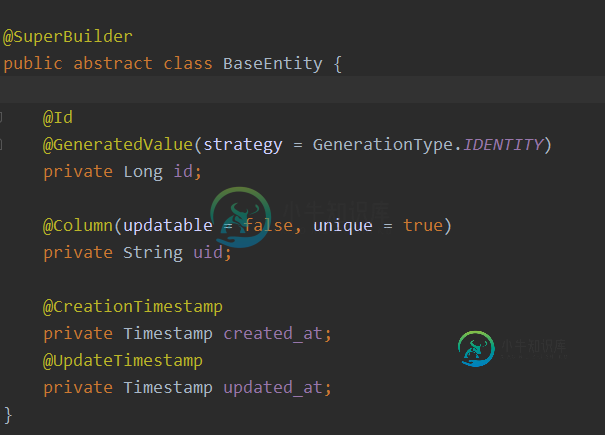 龙目岛超级建筑继承
龙目岛超级建筑继承我有一个类BaseEntity: 和一个扩展类: 我正在尝试使用生成器构建播种机: 我希望Lombok使用基类baseEntity在BreedEntity中创建一个构造函数。 我读了留档,当我删除@实体anotation SuperBuilder文档时,它工作得很好 有人能更详细地解释为什么会发生这种情况吗?
-
 9.02 中望龙腾软件一面
9.02 中望龙腾软件一面14.45 C++研发工程师 内容不全,凭回忆写的; 问的有点深,如果你答得不够多,他会问还有吗,或者直接提示你还有什么没说到,问的问题应该是事先记在本子上一个一个问的; 项目介绍,问设计到的技术; C++多态; 虚函数表的工作原理; 虚函数表的存储在内存的哪里;(给我问不会了分析了一个静态区,有大佬知道能告诉我一下吗) inline是什么,什么情况下使用; vector和list的区别; new
-
Gradle不能用龙目岛建造
目前无法与Gradle和龙目岛建立新项目。 我知道这是旧版本gradle和lombok的常见问题,并在本网站上看到类似问题,但我使用的是最新版本,无法通过此问题 环境信息 Java:openjdk 13.0.1 2019-10-15(这是OpenJ9版本,不是热点版本) 建筑gradle(使用Spring初始化器构建) 我尝试过的事情 我尝试过将deps换成Lombok gradle插件,如下所述
-
龙目岛是如何运作的?
我今天遇到了lombok。 我非常想知道它是如何工作的。 一篇Java Geek的文章给出了一些线索,但对我来说并不是很清楚: Java6删除了apt,使javac能够管理注释,简化了流程,以获得更简单的单步计算。这是龙目岛所走的路。 在Java6中,编译过程可能是:javac->apt->lombok apt process->使用ASM读取类文件并添加set/get方法? 你能给我看更多有关机
-
Prolog中的矩形挂钩接龙?
因为我是Prolog的新手,所以这里可能会有一个简短的问题。我试图将这个解决三角形挂钩接龙难题的代码转换为解决矩形挂钩接龙难题。我想我面临的问题是试图弄清楚如何让程序知道它完成了难题。这是我目前得到的: 三角拼图代码要求用户输入结束表的样子,但我不想这样。我希望这能显示任何可能的解决方案。表格总是正好6x4。我喜欢旋转网格来继续简单地计算水平跳跃的想法,所以我改变了旋转功能来旋转它的侧面,并添加了
-
slf4j+龙目岛+附加记录器
我想在我的类中使用lombok+@slf4j添加一个额外的记录器。当前,我正在使用@slf4j,它创建 私有静态最终org.slf4j.logger log=org.slf4j.loggerFactory.getLogger(logExample.class)。 我正在使用这个标准日志记录,我想创建另一个日志记录程序在类中的特定日志记录。 若要将特定日志输出到单独的文件,请执行以下操作。这是手动操
-
 网龙c++游戏开发面经
网龙c++游戏开发面经3.14 技术面+hr面 1.观察者模式 2.组合模式 3.工厂模式 4.A星算法 5.有限状态机 6.行为树 7.分层任务网络 8.背包系统 9.如何打乱一个数组里面的元素 不知道为什么一点八股都不问,只问了一部分项目的知识点。技术面试结束10分钟后通知进行hr面 3.15 oc #软件开发2024笔面经#
-
 南昌龙孚信息Java面试
南昌龙孚信息Java面试1.事务失效的场景 2.Collection接口下面有哪些集合,map属于Collection接口吗 3.讲讲 lambda表达式 4.讲讲ArrayList和LinkList 各有什么特点 5.Redis都有哪些数据结构 6.IOC是做什么的? 7.AOP在项目中的使用场景 8.Redis持久化方法 9.TCP协议 10.网络七层模型是哪七层 11.开发项目中用到哪些注解 12.使用mybati
-
 网龙产品设计师笔试
网龙产品设计师笔试五道简答题 第一题下面三个小问题 同一品类下的不同产品核心价值;选一进行仔细分析其如何体现的价值;选一说出好在哪不好在哪 第二题选Ai+任意领域可以有怎样的商业模式;元宇宙对于未来生活的影响 第三题 如何请客吃饭比较有感觉 第四题为什么要当产品设计师,过往对于产品设计师有涉及哪些内容,未来三个月要学什么 第五题排序领域 说明为什么-教育、金融云办公电商游戏娱乐等,个人性格描述,兴趣爱好,可以发送作
-
 网龙校招C++工具开发
网龙校招C++工具开发笔试 选择都很简单 简答题就是问多态实现,还有delete和delete[]区别 编程题一个反转字符串,一个遍历删除(考察迭代器和容器) 一面 没有要自我介绍,直接开始提问 上来直接问有没有做过界面开发,开发了多久。 你用过Qt,解释下信号和槽的概念 Qt的一些配置,平时怎么开发的,怎么配置项目,是用VC++还是什么? 看你好像linux下开发比较多(估计是看到我简历上都是linux下开发项目)
-
 @龙目岛项目中的数据已识别但不工作
@龙目岛项目中的数据已识别但不工作使用-版本:Mars。1版本(4.5.1)Maven-3.3.9 只需将龙目岛项目导入我的项目。 之后- 连线的事情是eclipse自动添加了导入,看起来lombok已经被识别了,但我仍然没有得到所有的getter/setter等等(看看右边的Outline窗口,没有任何变化)。 注意事项-1。我试图重新启动eclipse(甚至退出并进入,而不仅仅是重新启动)2。我按下项目 感谢阅读!
-
 湖南联通一面(已测评已OC)
湖南联通一面(已测评已OC)9.30日 自我介绍 面试官1 问 ArrayList 和 LinkedList 的区别 Arraylist扩容机制 数据库如何查询最大值 order by 降序 limit 1 聚集函数 max (面试官提示) 这两种方式哪个性能比较快 我猜的函数 orderby 能用索引吗 MySQL 的端口号 面试官2 为什么项目用到加密算法 AES 进一步问对称和非对称算法有哪些 (没专门记,只答了我会的
-
 蓝湖算法实习生一面凉经
蓝湖算法实习生一面凉经1. 自我介绍 2. 询问实习时间,谈论简历中上一段实习经历 3. 讲一讲简历里做过的最让你印象深刻的一个项目,具体的实施过程 4. (面试前不知道是cv算法方向,讲3的时候谈到了CNN)问了三个关于神经网络的问题: 1.为什么ResNet中使用1×1的卷积核 2.介绍一下CNN的反向传播过程(这个没推过,完全不会) 3.Dropout的作用 5.问最近有没有写过代码,手撕
-
 蓝湖-设计实习生-一面 已OC
蓝湖-设计实习生-一面 已OC#蓝湖##蓝湖实习# TIMELINE: 01-22投递🗳︎——01-23HR约面📢——01-24进行一面🎙︎ PROCESS: - 做个简单的自我介绍 - 介绍自己的项目 - 针对项目进行提问 - 反问环节 DETAIL: 1. 面试官开始就问了一些工具上的东西。比如Auto Layout以及Variants等。 2. 针对项目,面试官重点问Material Design、Design T
-
 前端蓝湖一二面面经(武汉)
前端蓝湖一二面面经(武汉)一面 一小时 1. 项目难点 2. 首页优化 3. 围绕着项目难点展开,一句八股没问,面试官说,他不喜欢问八股,从项目描述就能看出来个大概 4. 阅读过什么书籍?讲讲书里边都讲什么? 5. code 1. 使用reduce实现filter 2. 实现一个弹窗组件/函数,该函数初始化时调用:要求: 1. 每个自然日弹出一次 2. 最多弹出三次 二面 一小时 1. react和vue的区别 2. pi