《杉川机器人》专题
-
使用Dockerfile[复制]将文件从Docker容器复制到主机
我正在使用docker容器来编译一段代码,我不一定要将其docker化。我已使用必要的构建工具设置了一个映像,但我希望以某种方式将编译后的文件从容器中取出,而无需使用docker cp container:/file host/file命令。换句话说,我希望自动化这个过程,以便在构建完成后,将生成的文件复制到主机。 Dockerfile
-
 Docker-在主机和容器上为不同的网站运行Apache
Docker-在主机和容器上为不同的网站运行Apache我想使用Docker,以便能够运行一个需要PHP5.3的旧应用程序,同时在我的主机服务器上还有我的其他网站,在主机Apache上运行。 所以我有一个网站。com,siteB。com,siteC。com运行在主机上,使用主机Apache/PHP/MySQL服务器,我有siteZ。com,安装在Docker容器中,该容器应使用容器的Apache/PHP,而不是主机MySQL服务器。 这是我想获得的架构
-
如何从Docker容器内部获取Docker主机的IP地址
问题内容: 如标题所示。我需要能够检索Docker主机的IP地址和从主机到容器的端口映射,并在容器内部进行操作。 问题答案: 正如@MichaelNeale注意到的那样,没有必要使用此方法(除非仅在构建时需要此IP),因为此IP将在构建时进行硬编码。
-
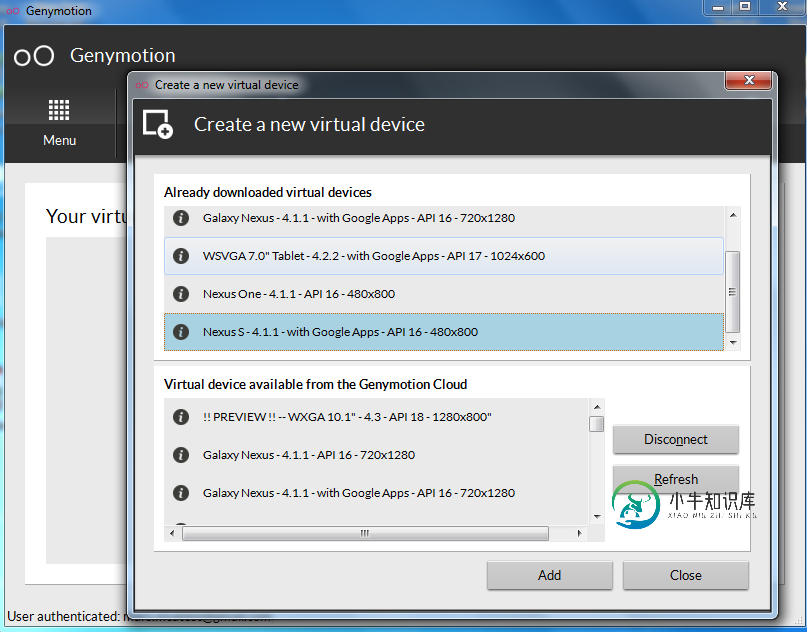 Android开发必备:秒杀真机超快模拟器Genymotion介绍
Android开发必备:秒杀真机超快模拟器Genymotion介绍本文向大家介绍Android开发必备:秒杀真机超快模拟器Genymotion介绍,包括了Android开发必备:秒杀真机超快模拟器Genymotion介绍的使用技巧和注意事项,需要的朋友参考一下 第一,这货速度太快,第二,模仿真机环境,第三,秒杀任何Android模拟器包括真机,不多说上图,我忒忙! 官网: http://www.genymotion.com/ 镜像图片可以创建多个模拟器 关键是有
-
如何在服务器停机后恢复spring批处理作业
问题是关于批处理作业的自动恢复策略。表示服务器由于未知原因关闭,当时有几个作业正在运行(状态为“开始”,结束时间为null)。当我们再次启动服务器时,我们如何恢复所有这些作业。 在我的情况下,我编写了自己的作业启动程序来接收请求并将它们保存到DB队列中。然后,我运行自己的作业调度程序轮询来自DB的请求并执行作业。为了将这些作业的状态从“已开始”更改为“已开始”,以便再次被我的计划程序接收,我的当前
-
php-共享主机中的Laravel给我“内部服务器错误”
在我的主机中,我在public_html的文件夹中有一些页面。 所以,我需要上传一个Laravel项目到一个新的文件夹中,这样才能访问:“www.mypage.com/laravelproject”。我的问题是,我创建了一个文件夹laravelproject,并将所有laravel项目都放在这个文件夹中,但请给出: 被禁止的 您没有在此服务器上访问/laravelproject/的权限。 此外,尝
-
为什么使用JIT与编译机器码相比Java更快?
问题内容: 我听说Java必须使用JIT来提高速度。与解释相比,这很合情合理,但是为什么有人不能制作可以生成快速Java代码的提前编译器呢?我知道,但是我认为它的输出通常不会比Hotspot快。 语言方面是否存在使这变得困难的事情?我认为可以归结为以下几点: 反射 类加载 我想念什么?如果我避免使用这些功能,是否可以将Java代码一次编译为本机代码并完成? 问题答案: 任何AOT编译器的真正杀手是
-
请你来说一下linux内核中的Timer 定时器机制
本文向大家介绍请你来说一下linux内核中的Timer 定时器机制相关面试题,主要包含被问及请你来说一下linux内核中的Timer 定时器机制时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1)低精度时钟 Linux 2.6.16之前,内核只支持低精度时钟,内核定时器的工作方式: 1、系统启动后,会读取时钟源设备(RTC, HPET,PIT…),初始化当前系统时间。 2、内核会根据HZ(
-
简要说说一个完整机器学习项目的流程?
本文向大家介绍简要说说一个完整机器学习项目的流程?相关面试题,主要包含被问及简要说说一个完整机器学习项目的流程?时的应答技巧和注意事项,需要的朋友参考一下 抽象成数学问题(确定是一个分类问题、回归问题还是聚类问题,明确可以获得什么样的数据) 获取数据(数据要具有代表性,对数据的量级也要有一个评估,多少样本,多少特征,对内存的消耗,考虑内存是否能放得下,如果放不下考虑降维或者改进算法,如果数据量太大
-
哪些机器学习算法不需要做归一化处理?
本文向大家介绍哪些机器学习算法不需要做归一化处理?相关面试题,主要包含被问及哪些机器学习算法不需要做归一化处理?时的应答技巧和注意事项,需要的朋友参考一下 概率模型不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化
-
在机器学习中,为何要经常对数据归一化?
本文向大家介绍在机器学习中,为何要经常对数据归一化?相关面试题,主要包含被问及在机器学习中,为何要经常对数据归一化?时的应答技巧和注意事项,需要的朋友参考一下 归一化可以: 归一化后加快了梯度下降求最优解的速度(两个特征量纲不同,差距较大时,等高线较尖,根据梯度下降可能走之字形,而归一化后比较圆走直线) 归一化有可能提高精度 (一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离
-
Linux中使用expect脚本实现远程机器自动登录
本文向大家介绍Linux中使用expect脚本实现远程机器自动登录,包括了Linux中使用expect脚本实现远程机器自动登录的使用技巧和注意事项,需要的朋友参考一下 首先创建一个expect脚本ssh_expect,文件内容如下: 然后定义一些命令别名,比如: 这些别名可以写到~/.bashrc文件中 然后执行 h101 就可以自动登录192.168.0.101机器了。
-
将包含数据的Docker容器克隆到另一台主机
我有两个正在运行的docker容器。一个容器有MySQL和数据,另一个容器有Tomcat中的Java web应用程序。 如何使用数据将MySQL容器克隆到另一个Docker主机? 尝试了保存/加载方法。但是没有成功,因为没有数据 但是Java web应用程序容器正在工作
-
使用当前时间vs不使用的随机数生成器
我想了解使用带有作为种子的随机数生成器和仅仅使用默认构造函数之间有什么区别。就是这个有什么区别: 还有这个: 我知道这些数字是伪随机的,但我还没有完全理解细节,以及它们是如何产生的,在使用当前时间作为种子时得到的“随机性”水平和使用默认构造函数时。
-
带有udf的Pyspark groupby:在本地机器上的性能较差
我正在尝试对由几个每日文件(每个15GB)组成的巨大数据集进行一些分析。为了更快,仅出于测试目的,我创建了一个非常小的数据集,其中包括所有相关场景。我必须分析每个用户的正确操作顺序(即类似于日志或审计)。 为了做到这一点,我定义了一个udf函数,然后应用了一个groupby。下面的代码重现了我的用例: 这给我带来了以下结果: 是不是太慢了? 我正在用一台现代笔记本电脑和康达。我使用conda na